GenDataAttribution
1.0.0
프로젝트 | 종이
왕성유 1 , Alexei A. Efros 2 , Jun-Yan Zhu 1 , Richard Zhang 3 .
카네기멜론대학교 1 , UC Berkeley 2 , Adobe Research 2
ICCV, 2023.
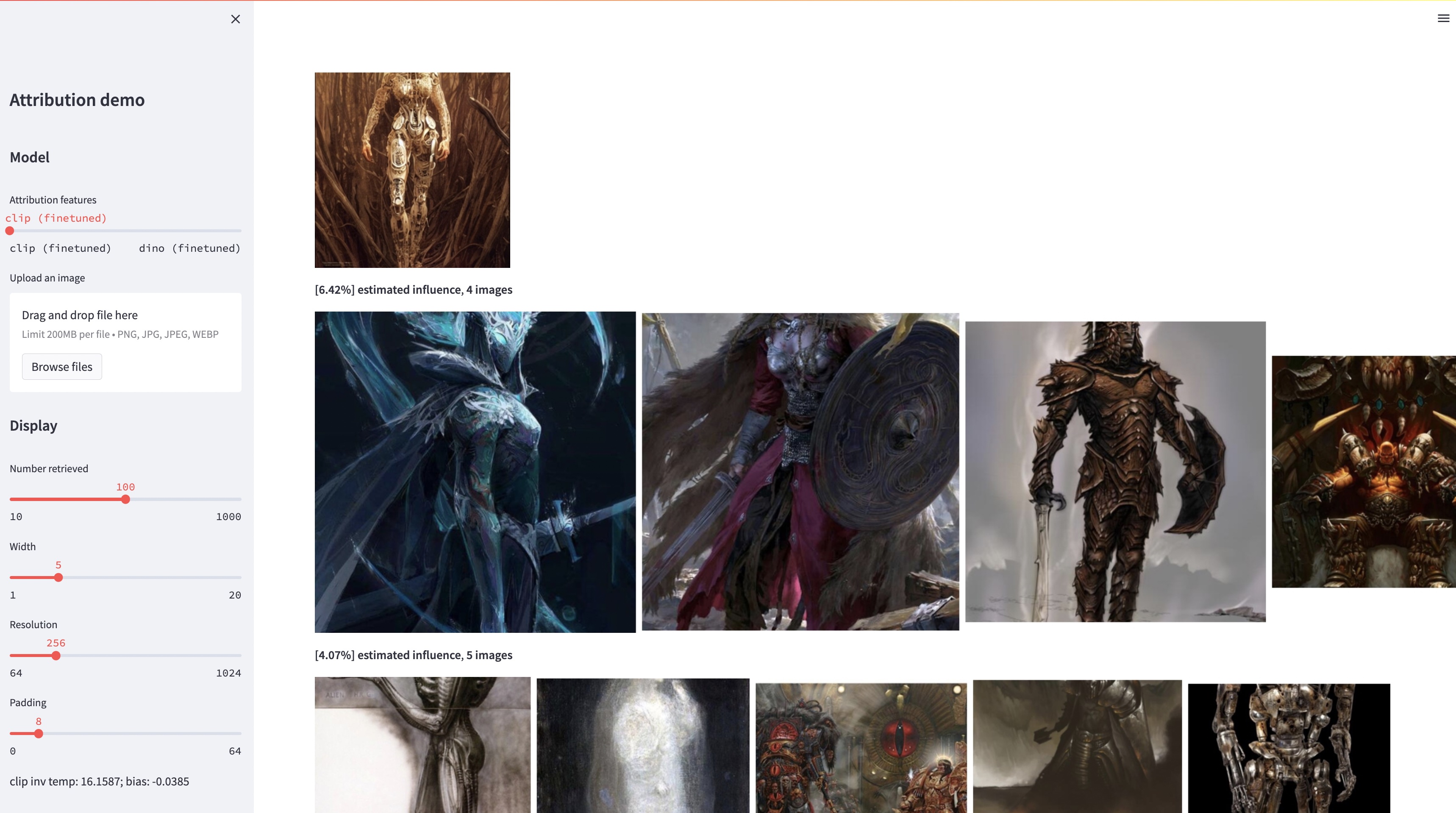
대규모 텍스트-이미지 모델은 "새로운" 이미지를 합성할 수 있지만 이러한 이미지는 반드시 훈련 데이터를 반영합니다. 훈련 세트의 이미지 중 주어진 생성 이미지의 모양에 가장 큰 영향을 미치는 모델의 데이터 속성 문제는 어렵지만 중요한 문제입니다. 이 문제에 대한 첫 번째 단계로 우리는 기존의 대규모 모델을 주어진 예시 개체나 스타일에 맞게 조정하는 "사용자 정의" 방법을 통해 속성을 평가합니다. 우리의 핵심 통찰력은 이를 통해 예시의 구성에 의해 계산적으로 영향을 받는 합성 이미지를 효율적으로 생성할 수 있다는 것입니다. 이러한 예시에 영향을 받은 이미지의 새로운 데이터 세트를 통해 다양한 데이터 속성 알고리즘과 다양한 특징 공간을 평가할 수 있습니다. 또한 데이터세트를 학습하여 DINO, CLIP, ViT와 같은 표준 모델을 귀인 문제에 맞춰 조정할 수 있습니다. 절차가 작은 표본 세트에 맞게 조정되었더라도 더 큰 세트에 대한 일반화를 보여줍니다. 마지막으로 문제에 내재된 불확실성을 고려하여 일련의 훈련 이미지에 소프트 속성 점수를 할당할 수 있습니다.
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh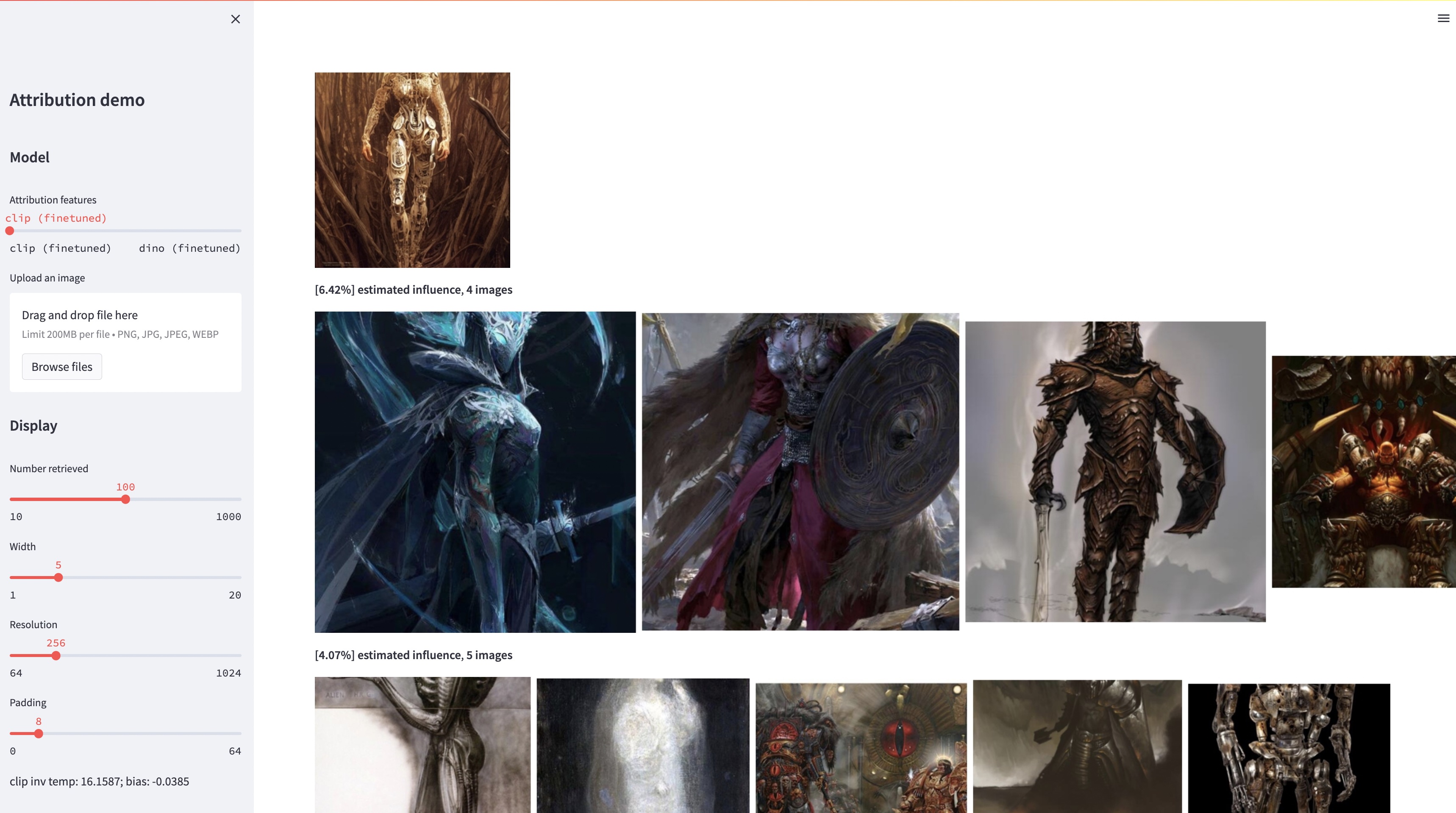
streamlit run streamlit_demo.py평가를 위해 테스트 세트를 출시합니다. 데이터세트를 다운로드하려면 다음 안내를 따르세요.
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laion데이터 세트는 다음과 같이 구성됩니다.
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
모든 예시 이미지는 dataset/exemplar 에 저장되고, 합성된 모든 이미지는 dataset/synth 에 저장되며, png의 100만개 라온 이미지는 dataset/laion_subset 에 저장됩니다. dataset/json 의 JSON 파일은 다양한 테스트 사례를 포함하여 열차/발행/테스트 분할을 지정하고 정답 레이블 역할을 합니다. JSON 파일 내부의 각 항목은 고유하고 미세 조정된 모델입니다. 항목에는 미세 조정에 사용된 예시 이미지와 모델에서 생성된 합성 이미지도 기록됩니다. test_artchive.json , test_bamfg.json , test_observed_imagenet.json 및 test_unobserved_imagenet.json 의 네 가지 테스트 사례가 있습니다.
테스트 세트, 사전 계산된 LAION 기능 및 사전 훈련된 가중치를 다운로드한 후 extract_feat.py 실행하여 테스트 세트에서 기능을 사전 계산한 다음 eval.py 실행하여 성능을 평가할 수 있습니다. 다음은 일괄적으로 평가를 실행하는 bash 스크립트입니다.
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.sh 측정항목은 results 의 .pkl 파일에 저장됩니다. 현재 스크립트는 각 명령을 순차적으로 실행합니다. 명령을 병렬로 실행하려면 자유롭게 수정하세요. 다음 명령은 .pkl 파일을 .csv 파일로 저장된 테이블로 구문 분석합니다.
python results_to_csv.py 2023년 12월 18일 업데이트 객체 중심 또는 스타일 중심 모델에 대해서만 훈련된 모델을 다운로드하려면 bash weights/download_style_object_ablation.sh 실행하세요.
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
이전 초안을 읽고 통찰력 있는 피드백을 주신 Aaron Hertzmann에게 감사드립니다. 유용한 토론을 해주신 Eli Shechtman, Oliver Wang, Nick Kolkin, 박태성, John Collomosse, Sylvain Paris 등 Adobe Research의 동료들과 Alex Li, Yonglong Tian에게 감사드립니다. Custom Diffusion 훈련에 대한 지침을 주신 Nupur Kumari, 초안 교정을 도와주신 Ruihan Gao, Stable Diffusion 기능 추출을 위한 조언을 주신 Alex Li, BAM-FG 데이터 세트에 대한 도움을 주신 Dan Ruta에게 감사드립니다. 팬데믹 하이킹과 브레인스토밍에 대해 Bryan Russell에게 감사드립니다. 이 작업은 SYW가 Adobe 인턴이었을 때 시작되었으며 부분적으로 Adobe 선물과 JP Morgan Chase Faculty Research Award의 지원을 받았습니다.