clearml fractional gpu
1.0.0
? Leave a star to support the project! ?
여러 사용자 간에 고급 GPU 또는 프로슈머 및 소비자 GPU를 공유하는 것은 AI 개발을 가속화하는 가장 비용 효율적인 방법입니다. 안타깝게도 지금까지 MIG/Slicing 고급 GPU(A100+)에 적용되고 Kubernetes가 필요한 유일한 기존 솔루션은
? 모든 Nvidia 카드에 대한 컨테이너 기반 분수형 GPU에 오신 것을 환영합니다! ?
사전 구축된 하드 메모리 제한이 있는 CUDA 11.x 및 CUDA 12.x를 지원하는 사전 패키징된 컨테이너를 제공합니다! 즉, 동일한 GPU에서 여러 컨테이너를 시작할 수 있으므로 한 사용자가 전체 호스트 GPU 메모리를 할당할 수 없습니다. (더 이상 전체 GPU 메모리를 차지하는 탐욕스러운 프로세스가 없습니다! 마지막으로 드라이버 수준의 하드 제한 메모리 옵션이 있습니다.)
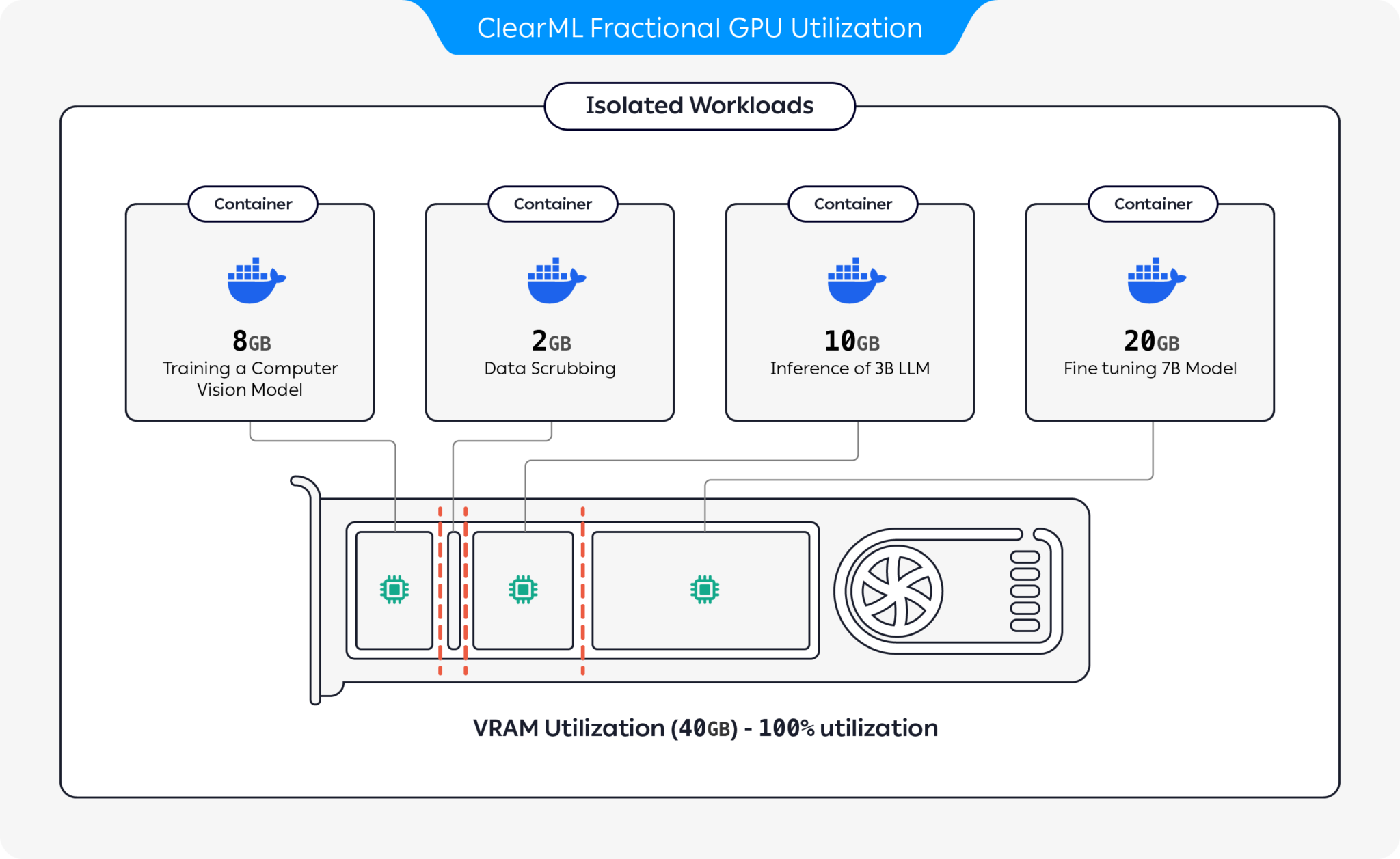
ClearML은 GPU를 분할하여 GPU 리소스 활용을 최적화하는 여러 옵션을 제공합니다.
이러한 옵션을 통해 ClearML은 최적화된 하드웨어 활용도 및 워크로드 성능으로 AI 워크로드를 실행할 수 있습니다. 이 리포지토리는 컨테이너 기반 분수 GPU를 다룹니다. ClearML의 분수형 GPU 제품에 대한 자세한 내용은 ClearML 설명서를 참조하세요.
자신에게 적합한 컨테이너를 선택하고 실행하세요.
docker run -it --gpus 0 --ipc=host --pid=host clearml/fractional-gpu:u22-cu12.3-8gb bash부분 GPU 메모리 제한이 올바르게 작동하는지 확인하려면 컨테이너 내부에서 실행하세요.
nvidia-smi다음은 A100 GPU의 출력 예입니다.
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 A100-PCIE-40GB Off | 00000000:01:00.0 Off | N/A |
| 32% 33C P0 66W / 250W | 0MiB / 8128MiB | 3% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+
| 메모리 제한 | 쿠다 버전 | 우분투 버전 | 도커 이미지 |
|---|---|---|---|
| 12GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-12gb |
| 12GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-12gb |
| 12GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-12gb |
| 12GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-12gb |
| 8GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-8gb |
| 8GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-8gb |
| 8GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-8gb |
| 8GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-8gb |
| 4GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-4gb |
| 4GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-4gb |
| 4GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-4gb |
| 4GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-4gb |
| 2GiB | 12.3 | 22.04 | clearml/fractional-gpu:u22-cu12.3-2gb |
| 2GiB | 12.3 | 20.04 | clearml/fractional-gpu:u20-cu12.3-2gb |
| 2GiB | 11.7 | 22.04 | clearml/fractional-gpu:u22-cu11.7-2gb |
| 2GiB | 11.1 | 20.04 | clearml/fractional-gpu:u20-cu11.1-2gb |
중요한
--pid=host 로 컨테이너를 실행해야 합니다!
메모
--pid=host 메모리/사용률 사용량을 제한할 때 드라이버가 컨테이너의 프로세스와 다른 호스트 프로세스를 구별할 수 있도록 하는 데 필요합니다.
팁
ClearML-Agent 사용자는 구성 파일의 agent.extra_docker_arguments 섹션에 [--pid=host] 를 추가합니다.
자신만의 컨테이너를 만들고 원래 컨테이너를 상속받으세요.
여기에서 몇 가지 예를 찾을 수 있습니다.
단편 GPU 컨테이너는 Kubernetes POD뿐만 아니라 베어메탈 실행에도 사용할 수 있습니다. 예! Fractional GPU 컨테이너 중 하나를 사용하면 작업/Pod의 메모리 소비를 제한하고 서로 메모리 충돌을 걱정하지 않고 GPU를 쉽게 공유할 수 있습니다!
다음은 간단한 Kubernetes POD 템플릿입니다.
apiVersion : v1
kind : Pod
metadata :
name : train-pod
labels :
app : trainme
spec :
hostPID : true
containers :
- name : train-container
image : clearml/fractional-gpu:u22-cu12.3-8gb
command : ['python3', '-c', 'print(f"Free GPU Memory: (free, global) {torch.cuda.mem_get_info()}")'] 중요한
hostPID: true 로 Pod를 실행해야 합니다!
메모
hostPID: true 가 필요합니다.
컨테이너는 Nvidia 드라이버 <= 545.xx 를 지원합니다. 새로운 드라이버가 계속 출시되면 계속 업데이트하고 지원할 예정입니다.
지원되는 GPU : RTX 시리즈 10, 20, 30, 40, A 시리즈 및 Data-Center P100, A100, A10/A40, L40/s, H100
제한 사항 : Windows 호스트 시스템은 현재 지원되지 않습니다. 이것이 중요하다면 이슈 섹션에 요청을 남겨주세요.
Q : 컨테이너 내부에서 nvidia-smi 실행하면 로컬 프로세스 GPU 소비가 보고됩니까?
A : 예, nvidia-smi 하위 수준 드라이버와 직접 통신하며 정확한 컨테이너 GPU 메모리와 컨테이너 로컬 메모리 제한을 모두 보고합니다.
GPU 활용도는 특정 로컬 컨테이너 GPU 활용도가 아닌 전역(예: 호스트 측) GPU 활용도입니다.
Q : Python/Pytorch/Tensorflow가 실제로 메모리가 제한되어 있는지 어떻게 확인하나요?
A : PyTorch의 경우 다음을 실행할 수 있습니다.
import torch
print ( f'Free GPU Memory: (free, global) { torch . cuda . mem_get_info () } ' )Numba 예:
from numba import cuda
print ( f'Free GPU Memory: { cuda . current_context (). get_memory_info () } ' ) Q : 사용자가 제한을 깨뜨릴 수 있나요?
A : 악의적인 사용자가 방법을 찾을 것이라고 확신합니다. 악의적인 사용자로부터 보호하려는 의도는 결코 없었습니다.
귀하의 시스템에 액세스할 수 있는 악의적인 사용자가 있는 경우 부분 GPU가 가장 큰 문제가 아닙니까?
Q : 프로그래밍 방식으로 메모리 제한을 감지하려면 어떻게 해야 합니까?
A : OS 환경 변수 GPU_MEM_LIMIT_GB 를 확인할 수 있습니다.
이를 변경해도 제한이 제거되거나 줄어들지는 않습니다.
Q : --pid=host 사용하여 컨테이너를 실행하는 것이 안전/안전합니까?
A : 안전하고 안전해야 합니다. 보안 관점에서 볼 때 가장 주의해야 할 점은 컨테이너 프로세스가 호스트 시스템에서 실행 중인 모든 명령줄을 볼 수 있다는 것입니다. 프로세스 명령줄에 "비밀"이 포함되어 있는 경우, 이는 잠재적인 데이터 유출이 될 수 있습니다. 명령줄에 "비밀"을 전달하는 것은 바람직하지 않으므로 보안 위험으로 간주하지 않습니다. 즉, 보안이 핵심이라면 엔터프라이즈 에디션(아래 참조)에서는 pid-host 사용하여 실행할 필요가 없으므로 완전히 안전합니다.
Q : --pid=host 없이 컨테이너를 실행할 수 있습니까?
A : 할 수 있어요! 하지만 Clearml-fractional-gpu 컨테이너의 엔터프라이즈 버전을 사용해야 합니다(그렇지 않으면 메모리 제한이 컨테이너 전체가 아닌 시스템 전체에 적용됩니다). 이 기능이 중요하다면 ClearML 영업 및 지원팀에 문의하세요.
ClearML 사용 라이센스는 연구 또는 개발 목적으로만 부여됩니다. ClearML은 교육용, 개인용 또는 내부 상업용으로 사용될 수 있습니다.
제품 또는 서비스 내에서 사용할 수 있는 확장된 상업용 라이센스는 ClearML Scale 또는 Enterprise 솔루션의 일부로 제공됩니다.
ClearML은 단편 GPU에 오케스트레이션, 우선 순위 대기열, 할당량 관리, 컴퓨팅 클러스터 대시보드, 데이터 세트 관리 및 실험 관리, 엔터프라이즈급 보안 및 지원을 포함하는 많은 추가 기능을 추가하는 기업 및 상업용 라이센스를 제공합니다. ClearML 오케스트레이션에 대해 자세히 알아보거나 ClearML 영업 담당자에게 직접 문의하세요.
모두에게 알려주세요! #ClearMLFractionalGPU
Slack 채널에 가입하세요
문제가 발생하면 알려주시고 문제 페이지에서 디버깅할 수 있도록 도와주세요.
이 제품은 ClearML 팀에서 ❤️과 함께 제공합니다.


