amazon bedrock rag
1.0.0
검색 증강 생성(RAG)은 대규모 언어 모델의 출력을 최적화하는 프로세스이므로 응답을 생성하기 전에 훈련 데이터 소스 외부의 권위 있는 지식 기반을 참조합니다. LLM(대형 언어 모델)은 방대한 양의 데이터에 대해 교육을 받고 수십억 개의 매개변수를 사용하여 질문에 답하고, 언어를 번역하고, 문장을 완성하는 등의 작업을 위한 원본 출력을 생성합니다. RAG는 이미 강력한 LLM 기능을 모델을 재교육할 필요 없이 특정 도메인이나 조직의 내부 지식 기반으로 확장합니다. 이는 LLM 결과를 개선하여 다양한 상황에서 관련성, 정확성 및 유용성을 유지하는 비용 효율적인 접근 방식입니다. 여기에서 RAG에 대해 자세히 알아보세요.
Amazon Bedrock은 AI21 Labs, Anthropic, Cohere, Meta, Stability AI 및 Amazon과 같은 주요 AI 기업의 고성능 기반 모델(FM)을 단일 API를 통해 선택할 수 있는 완전관리형 서비스입니다. 보안, 개인정보 보호, 책임 있는 AI를 갖춘 생성적 AI 애플리케이션을 구축하는 데 필요한 기능입니다. Amazon Bedrock을 사용하면 사용 사례에 맞는 상위 FM을 쉽게 실험하고 평가할 수 있으며, 미세 조정 및 RAG와 같은 기술을 사용하여 데이터로 이를 개인적으로 사용자 정의하고, 엔터프라이즈 시스템 및 데이터 소스를 사용하여 작업을 실행하는 에이전트를 구축할 수 있습니다. Amazon Bedrock은 서버리스이므로 인프라를 관리할 필요가 없으며, 이미 익숙한 AWS 서비스를 사용하여 생성 AI 기능을 애플리케이션에 안전하게 통합하고 배포할 수 있습니다.
Amazon Bedrock용 기술 자료는 데이터 소스에 대한 사용자 지정 통합을 구축하고 데이터 흐름을 관리할 필요 없이 수집에서 검색 및 즉각적인 기능 보강까지 전체 RAG 워크플로를 구현하는 데 도움이 되는 완전 관리형 기능입니다. 세션 컨텍스트 관리가 내장되어 있으므로 앱에서 다단계 대화를 쉽게 지원할 수 있습니다.
기술 자료를 생성하는 과정에서 원하는 데이터 원본과 벡터 저장소를 구성합니다. 데이터 소스 커넥터를 사용하면 독점 데이터를 지식 기반에 연결할 수 있습니다. 데이터 원본 커넥터를 구성한 후에는 데이터를 기술 자료와 동기화하거나 최신 상태로 유지하고 데이터를 쿼리에 사용할 수 있습니다. Amazon Bedrock은 효율적인 데이터 검색을 위해 먼저 문서나 콘텐츠를 관리 가능한 덩어리로 분할합니다. 그런 다음 청크는 원본 문서에 대한 매핑을 유지하면서 임베딩으로 변환되어 벡터 인덱스(데이터의 벡터 표현)에 기록됩니다. 벡터 임베딩을 사용하면 텍스트의 유사성을 수학적으로 비교할 수 있습니다.
이 프로젝트는 두 가지 데이터 소스로 구현됩니다. Amazon S3에 저장된 문서에 대한 데이터 소스와 웹 사이트에 게시된 콘텐츠에 대한 또 다른 데이터 소스입니다. 벡터 검색 컬렉션은 벡터 저장을 위해 Amazon OpenSearch Serverless에서 생성됩니다.
Q&A 챗봇 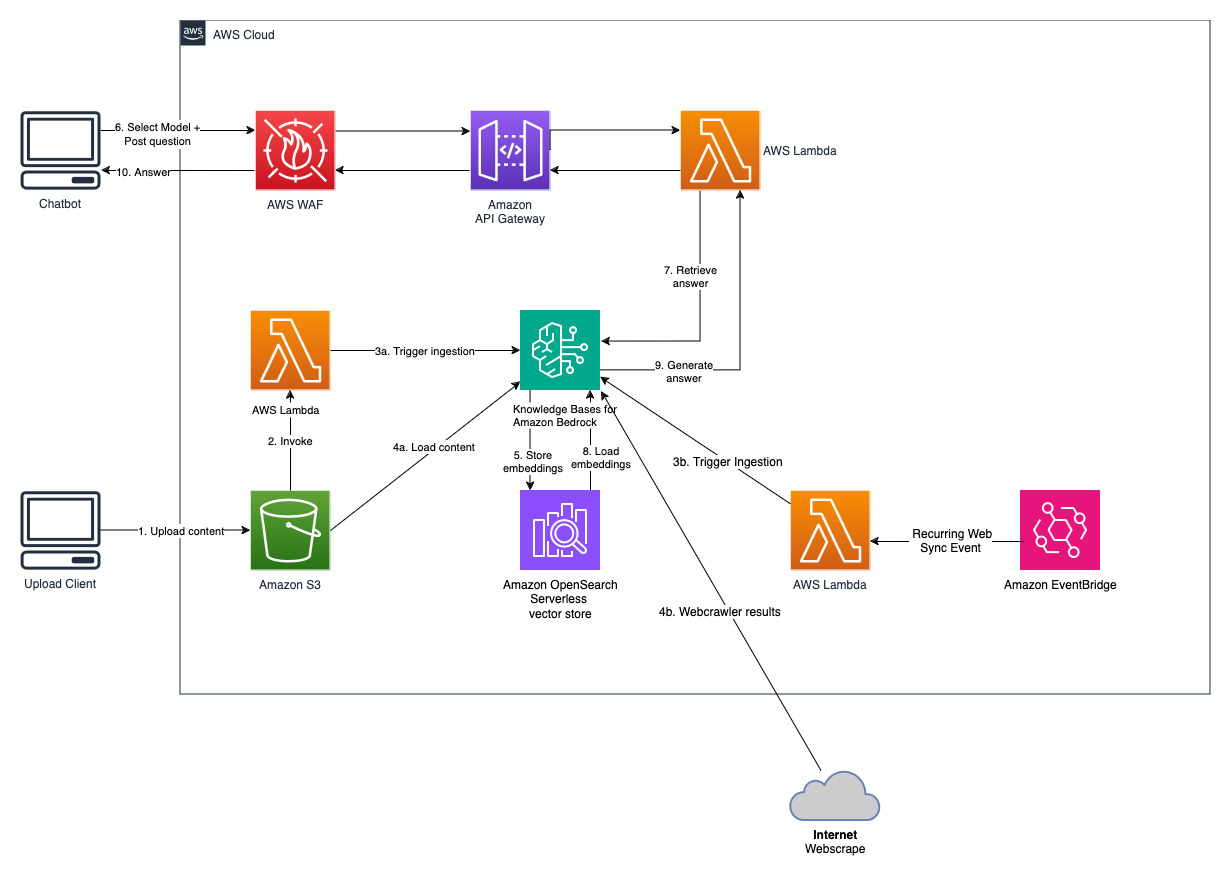
웹 데이터 소스를 위한 새 웹사이트 추가 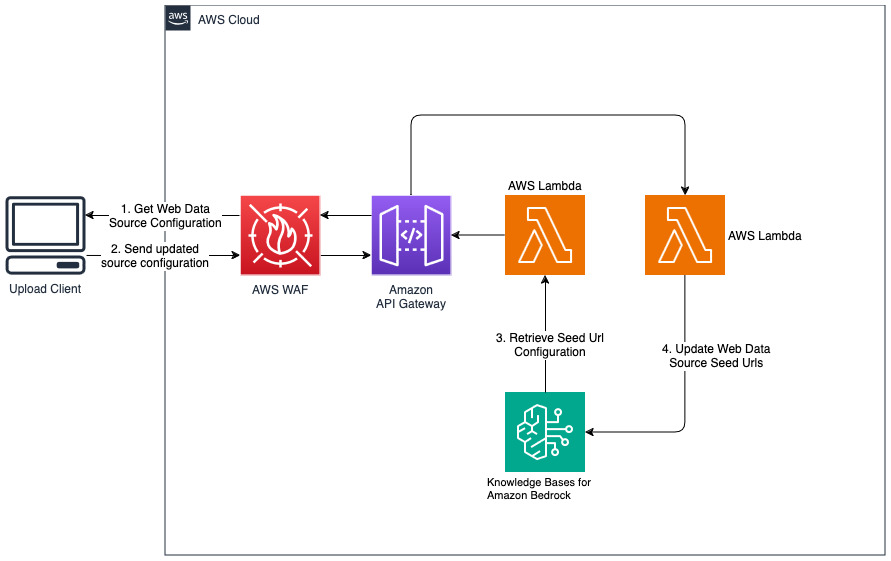
cdk deploy --context allowedip="xxx.xxx.xxx.xxx/32"
'allowedip' 컨텍스트 변수의 일부로 CIDR 형식으로 API 게이트웨이에 액세스할 수 있는 클라이언트 IP 주소를 제공합니다.
배포가 완료되면,
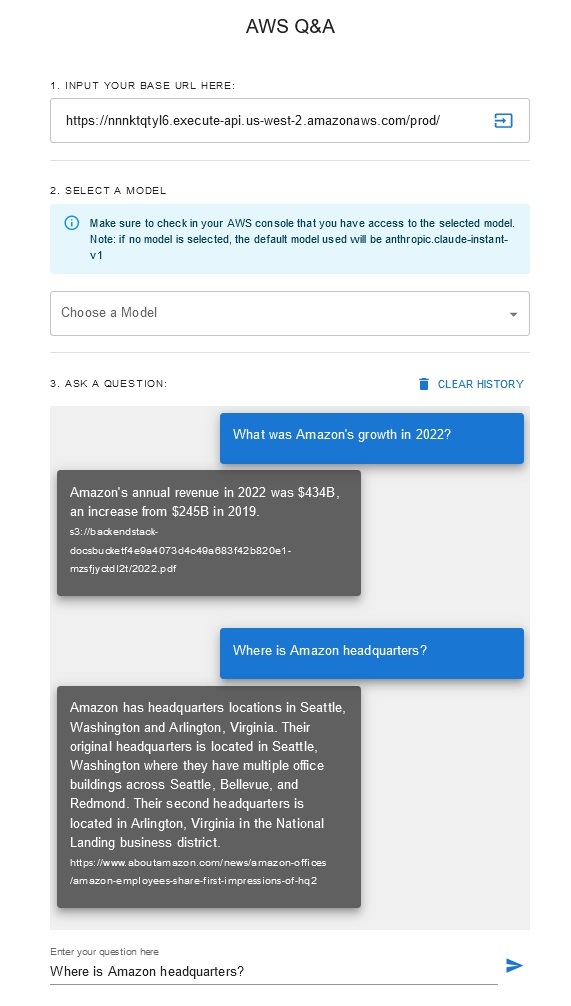
이 솔루션을 통해 사용자는 검색 및 생성 단계에서 사용할 기본 모델을 선택할 수 있습니다. 기본 모델은 Anthropic Claude Instant 입니다. 지식 기반 임베딩 모델의 경우 이 솔루션은 Amazon Titan Embeddings G1 - 텍스트 모델을 사용합니다. 이러한 기초 모델에 액세스할 수 있는지 확인하세요.
최근 공개적으로 사용 가능한 Amazon의 연례 보고서를 받아 앞서 언급한 S3 버킷 이름에 복사하세요. 빠른 테스트를 위해 AWS S3 콘솔을 사용하여 Amazon의 2022년 연례 보고서를 복사할 수 있습니다. 솔루션 배포가 S3 버킷의 새 콘텐츠를 감시하고 수집 워크플로를 트리거하기 때문에 S3 버킷의 콘텐츠는 지식 베이스와 자동으로 동기화됩니다.
배포된 솔루션은 URL https://www.aboutamazon.com/news/amazon-offices 사용하여 "WebCrawlerDataSource"라는 웹 데이터 소스를 초기화합니다. 웹 사이트 수집은 나중에 수행될 예정이므로 웹 사이트 콘텐츠를 검색하려면 이 Web Crawler 데이터 소스를 AWS 콘솔의 지식 베이스와 수동으로 동기화해야 합니다. Amazon Bedrock 콘솔 기반 지식에서 이 데이터 소스를 선택하고 "동기화" 작업을 시작합니다. 자세한 내용은 데이터 소스를 Amazon Bedrock 기술 자료와 동기화를 참조하세요. 웹사이트 콘텐츠는 동기화가 완료된 후에만 Q&A 챗봇에서 사용할 수 있습니다. 웹사이트를 데이터 소스로 설정할 때 이 지침을 사용하십시오.
이 솔루션 배포에서 생성된 클라우드 리소스 스택을 삭제하려면 "cdk destroy"를 사용하십시오.


