DeepMorphy
1.0.0
DeepMorphy는 신경망 기반 러시아어 형태소 분석기입니다.
DeepMorphy는 러시아어 형태소 분석기입니다. .Net Standard 2.0 라이브러리로 사용 가능합니다. 할 수 있다:
DeepMorphy의 용어는 pymorphy2 형태소 분석기에서 부분적으로 차용되었습니다.
Grammeme (영어 grammeme) - 단어의 문법 범주 중 하나의 의미(예: 과거형, 단수형, 남성형).
문법 범주 는 일부 공통 기능(예: 성별, 시제, 격 등)을 특징짓는 상호 배타적인 문법 세트입니다. DeepMorphy에서 지원되는 모든 범주 및 문법 목록은 여기에 있습니다.
태그 (영어 태그) - 특정 단어를 특성화하는 일련의 문법입니다(예: 고슴도치라는 단어에 대한 태그 - 명사, 단수, 주격, 남성).
Lemma (영어 보조정리)는 단어의 일반적인 형태입니다.
Lemmatization (eng. lemmatization) - 단어를 일반적인 형태로 가져옵니다.
어휘소는 한 단어의 모든 형태의 집합입니다.
DeepMorphy의 핵심 요소는 신경망입니다. 대부분의 단어에 대해 형태소 분석 및 표제어 분석은 네트워크에서 수행됩니다. 일부 유형의 단어는 전처리기에 의해 처리됩니다.
3개의 전처리기가 있습니다:
네트워크는 tensorflow 프레임워크를 기반으로 구축되고 훈련되었습니다. Opencorpora 사전은 데이터세트 역할을 합니다. TensorFlowSharp를 통해 .Net에 통합되었습니다.
DeepMorphy의 단어 구문 분석을 위한 계산 그래프는 11개의 "서브넷"으로 구성됩니다.
단어의 형태를 바꾸는 문제는 1 seq2seq 네트워크로 해결됩니다.
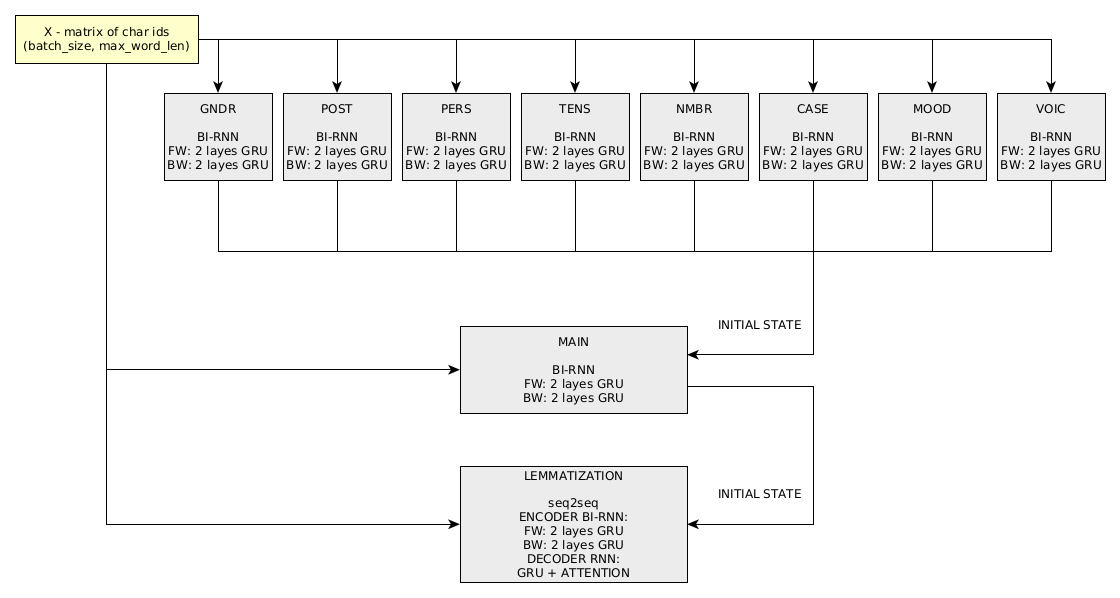
훈련은 순차적으로 수행되며 먼저 네트워크가 범주별로 훈련됩니다(순서는 중요하지 않음). 다음으로 태그별 주요 분류, 표제어 추출, 단어 형태 변경을 위한 네트워크를 학습합니다. 훈련은 3개의 Titan X GPU에서 수행되었습니다. 최신 릴리스의 테스트 데이터 세트에 대한 네트워크 성능 지표는 여기에서 볼 수 있습니다.
.NET용 DeepMorphy는 .Net Standard 2.0 라이브러리입니다. 유일한 종속성은 TensorflowSharp 라이브러리입니다(신경망은 이를 통해 시작됩니다).
라이브러리는 Nuget에 게시되어 있으므로 Nuget을 통해 설치하는 것이 가장 쉽습니다.
패키지 관리자가 있는 경우:
Install-Package DeepMorphy
프로젝트가 PackageReference를 지원하는 경우:
<PackageReference Include="DeepMorphy"/>
누군가 소스에서 빌드하고 싶다면 C# 소스가 여기에 있습니다. Rider는 개발에 사용됩니다(모든 것은 문제 없이 스튜디오에서 조립되어야 합니다).
모든 작업은 MorphAnalyzer 클래스 개체를 통해 수행됩니다.
var morph = new MorphAnalyzer ( ) ;이상적으로는 이를 싱글톤으로 사용하는 것이 더 낫습니다. 객체를 생성할 때 사전과 네트워크를 로드하는 데 약간의 시간이 소요됩니다. 스레드 안전. 생성 시 다음 매개변수를 생성자에 전달할 수 있습니다.
구문 분석에는 Parse 메서드가 사용됩니다(분석할 단어가 포함된 IEnumerable을 입력으로 사용하고 분석 결과와 함께 IEnumerable을 반환함).
var results = morph . Parse ( new string [ ]
{
"королёвские" ,
"тысячу" ,
"миллионных" ,
"красотка" ,
"1-ый"
} ) . ToArray ( ) ;
var morphInfo = results [ 0 ] ;지원되는 문법 범주, 문법 및 해당 키 목록은 여기에 있습니다. 가장 가능성 있는 문법(태그) 조합을 찾으려면 MorphInfo 개체의 BestTag 속성을 사용해야 합니다.
// выводим лучшую комбинацию граммем для слова
Console . WriteLine ( morphInfo . BestTag ) ;단어 자체를 기반으로 문법 범주(동음어 참조)의 의미를 명확하게 결정하는 것이 항상 가능한 것은 아니므로 DeepMorphy를 사용하면 특정 단어(Tags 속성)에 대한 상위 태그를 볼 수 있습니다.
// выводим все теги для слова + их вероятность
foreach ( var tag in morphInfo . Tags )
Console . WriteLine ( $ " { tag } : { tag . Power } " ) ;태그에 그램 조합이 있습니까?
// есть ли в каком-нибудь из тегов прилагательные единственного числа
morphInfo . HasCombination ( "прил" , "ед" ) ;가장 가능성이 높은 태그에 그램 조합이 있습니까?
// ясляется ли лучший тег прилагательным единственного числа
morphInfo . BestTag . Has ( "прил" , "ед" ) ;최상의 태그에서 특정 문법 카테고리 검색:
// выводит часть речи лучшего тега и число
Console . WriteLine ( morphInfo . BestTag [ "чр" ] ) ;
Console . WriteLine ( morphInfo . BestTag [ "число" ] ) ;태그는 여러 문법 범주(예: 품사 및 숫자)에 대한 정보가 동시에 필요할 때 사용됩니다. 하나의 카테고리에만 관심이 있는 경우 MorphInfo 개체의 문법 카테고리 의미 확률에 대한 인터페이스를 사용할 수 있습니다.
// выводит самую вероятную часть речи
Console . WriteLine ( morphInfo [ "чр" ] . BestGramKey ) ;문법 범주별로 확률 분포를 얻을 수도 있습니다.
// выводит распределение вероятностей для падежа
foreach ( var gram in morphInfo [ "падеж" ] . Grams )
{
Console . WriteLine ( $ " { gram . Key } : { gram . Power } " ) ;
}형태소 분석과 함께 단어의 기본형을 얻어야 하는 경우 분석기는 다음과 같이 생성되어야 합니다.
var morph = new MorphAnalyzer ( withLemmatization : true ) ;기본형은 단어 태그에서 얻을 수 있습니다:
Console . WriteLine ( morphInfo . BestTag . Lemma ) ;주어진 단어에 보조정리가 있는지 확인:
morphInfo . HasLemma ( "королевский" ) ;CanBeSameLexeme 메소드를 사용하여 단일 어휘소의 단어를 찾을 수 있습니다.
// выводим все слова, которые могут быть формой слова королевский
var words = new string [ ]
{
"королевский" ,
"королевские" ,
"корабли" ,
"пересказывают" ,
"королевского"
} ;
var results = morph . Parse ( words ) . ToArray ( ) ;
var mainWord = results [ 0 ] ;
foreach ( var morphInfo in results )
{
if ( mainWord . CanBeSameLexeme ( morphInfo ) )
Console . WriteLine ( morphInfo . Text ) ;
}형태학적 구문 분석 없이 표제어 추출만 필요한 경우 Lemmatize 메서드를 사용해야 합니다.
var tasks = new [ ]
{
new LemTask ( "синяя" , morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ) ,
new LemTask ( "гуляя" , morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var lemmas = morph . Lemmatize ( tasks ) . ToArray ( ) ;
foreach ( var lemma in lemmas )
Console . WriteLine ( lemma ) ;DeepMorphy는 어휘소 내의 단어 형식을 변경할 수 있습니다. 지원되는 굴절 목록은 여기에 있습니다. 사전 단어는 사전에 있는 형태 내에서만 변경할 수 있습니다. 단어의 형태를 변경하려면 Inflect 메서드가 사용됩니다. InflectTask 개체의 열거형(소스 단어, 소스 단어의 태그 및 단어가 배치되어야 하는 태그 포함)을 입력으로 사용합니다. 출력은 필수 양식이 포함된 열거형입니다(양식을 처리할 수 없는 경우 null임).
var tasks = new [ ]
{
new InflectTask ( "синяя" ,
morph . TagHelper . CreateTag ( "прил" , gndr : "жен" , nmbr : "ед" , @case : "им" ) ,
morph . TagHelper . CreateTag ( "прил" , gndr : "муж" , nmbr : "ед" , @case : "им" ) ) ,
new InflectTask ( "гулять" ,
morph . TagHelper . CreateTag ( "инф_гл" ) ,
morph . TagHelper . CreateTag ( "деепр" , tens : "наст" ) )
} ;
var results = morph . Inflect ( tasks ) ;
foreach ( var result in results )
Console . WriteLine ( result ) ;Lexeme 메소드를 사용하여 단어의 모든 형태를 얻는 것도 가능합니다(사전 단어의 경우 사전의 모든 형태를 반환하고 다른 경우에는 지원되는 굴절의 모든 형태를 반환합니다).
var word = "лемматизировать" ;
var tag = m . TagHelper . CreateTag ( "инф_гл" ) ;
var results = m . Lexeme ( word , tag ) . ToArray ( ) ;알고리즘의 특징 중 하나는 형태를 변경하거나 어휘소를 생성할 때 네트워크가 존재하지 않는(가설) 단어 형태, 즉 언어에서 사용되지 않는 형태를 "발명"할 수 있다는 것입니다. 예를 들어, 아래에서는 "will run"이라는 단어가 표시되지만 현재는 언어에서 특별히 사용되지 않습니다.
var tasks = new [ ]
{
new InflectTask ( "победить" ,
m . TagHelper . CreateTag ( "инф_гл" ) ,
m . TagHelper . CreateTag ( "гл" , nmbr : "ед" , tens : "буд" , pers : "1л" , mood : "изъяв" ) )
} ;
Console . WriteLine ( m . Inflect ( tasks ) . First ( ) ) ; 


