inverted_index
1.0.0
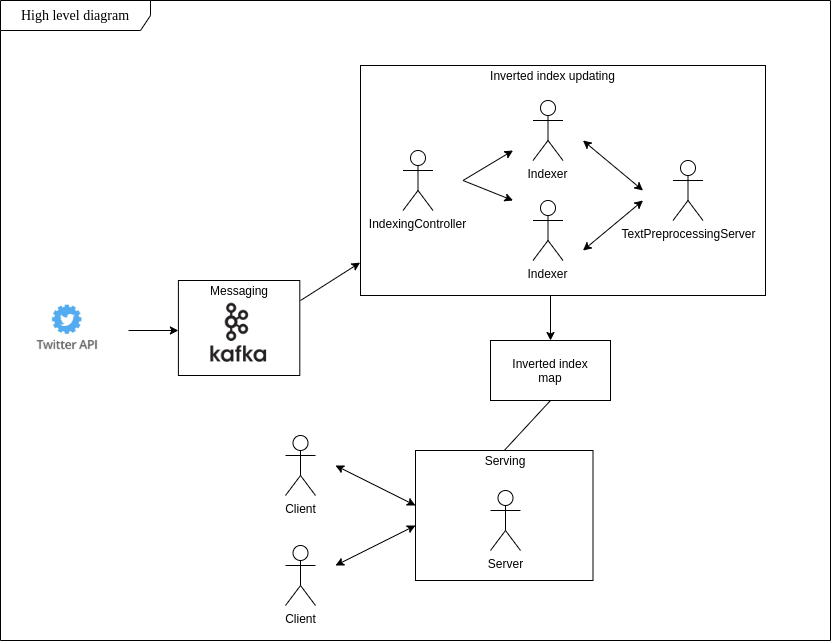
주변 사람들이 말하는 문구를 검색하는 것은 어려울 수 있습니다. 이 데이터 세트의 동적 업데이트는 어떻습니까? 확장 가능한 스토리지와 낮은 대기 시간? 이 프로젝트의 주요 목표는 이러한 요구 사항을 충족하고 실시간으로 트윗에 나타나는 트렌드를 최신 상태로 유지할 수 있는 시스템을 구축하는 것입니다.
역인덱스 아이디어에 따라 특정 콘텐츠가 포함된 트윗을 실시간으로 찾아 로컬 파일 시스템에 저장하고 클라이언트 연결을 초기화한 후 바로 단어 기반 검색을 수행할 수 있는 앱을 구현했습니다.
앱을 실행하려면 다음이 필요합니다.
git clone https://github.com/cyberpunk317/inverted_index.git TWITTER_APP_KEY = 'YOUR APP KEY'
TWITTER_APP_SECRET = 'YOUR APP SECRET'
TWITTER_KEY = 'YOUR KEY'
TWITTER_SECRET = 'YOUR SECRET' 클라이언트 및 서버용 Dockerfile을 만듭니다.
./gradlew clean build createClientDockerfile createMainDockerfile
그러면 루트 디렉터리에 app_server.Dockerfile 및 app_client.Dockerfile이 생성됩니다.
신청 시작:
docker-compose up
클라이언트 세션을 시작합니다.
docker build -f app_client.Dockerfile -t client:latest . && docker run -it --rm --network=host client:latest bash
관심 있는 단어를 입력해 보세요. 서버는 'dataset_v2//tweet_N.txt' 형식으로 트윗 위치를 반환합니다. 예를 들어:
You entered: war
Server response: [dataset_v2/Veeresh Dambal/tweet_30.txt, dataset_v2/pedro schliesser/tweet_1.txt]
제안된 기능(및 알려진 문제) 목록은 공개 문제를 참조하세요.
MIT 라이센스에 따라 배포됩니다. 자세한 내용은 LICENSE 참조하세요.


