mind x
1.0.0

이 프로젝트는 이러한 모델의 급속한 성장에 보조를 맞춰 개인 비서로서 개인화된 LLM(또는 LMM)의 타당성을 보여줍니다.
컨텍스트 경계가 있는 기존 Prompt-Tuning과 실시간 데이터 업데이트 및 환각 문제를 겪는 Fine-Tuning의 한계를 극복하기 위해 RAG(Retrieval-Augmented Generation) 방식을 도입했습니다.
전통적으로 RAG는 상점으로서 LangChain을 통해 Chroma와 같은 데이터베이스를 검색하는 데 사용되었지만 이 방법은 고정된 컨텍스트 내에서 작동하므로 제한적입니다.
따라서 우리는 자체 RAG 시스템을 구축할 계획입니다. 이 프로세스에는 LangChain이 제공할 수 있는 추론 및 회귀 문제를 해결하는 작업이 포함될 수 있습니다.
우리는 신속한 개발을 위해 최선을 다하고 있으며 곧 다국어 호환성을 지원할 예정입니다. 현재 이 시스템은 영어를 완벽하게 지원하고 있으며, 곧 한국어, 일본어 및 기타 언어도 지원할 계획입니다. 또한 회귀 및 추론 시스템도 곧 통합될 예정입니다.
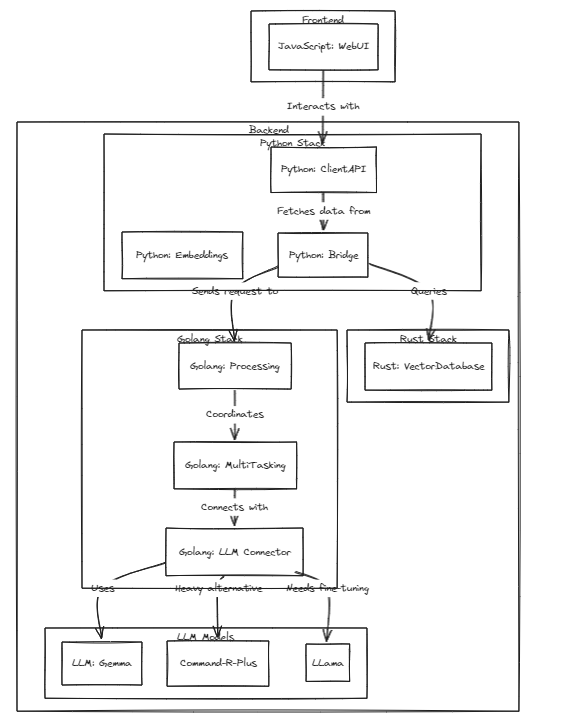
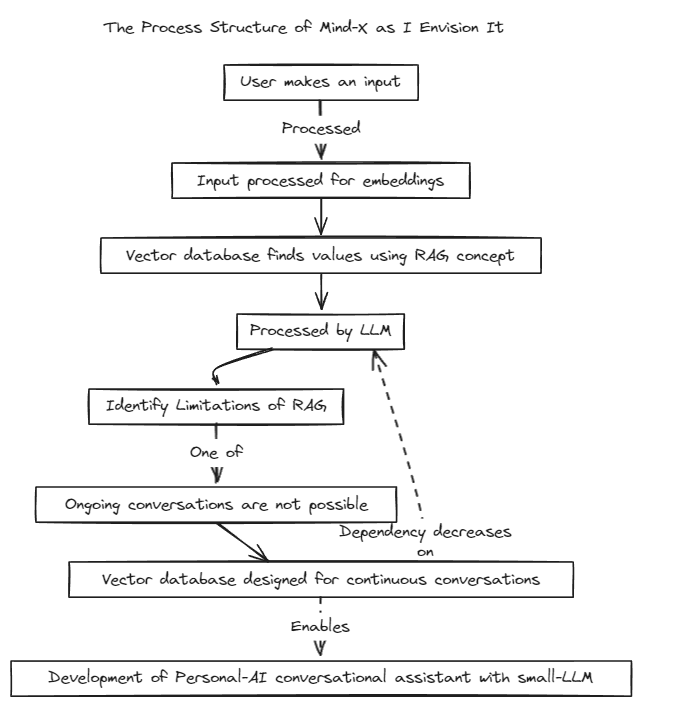
테스트를 실행하려면 다음 명령어를 실행하세요.
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
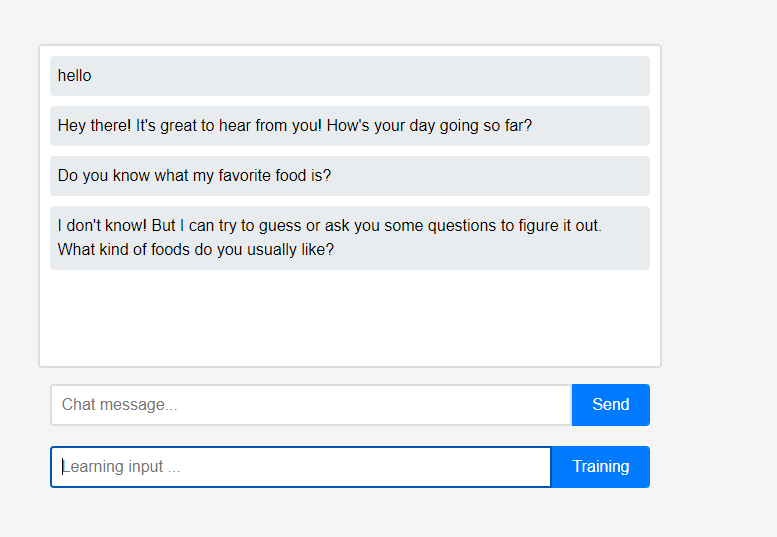 처음에 어시스턴트는 사용자에 대해 아무것도 모릅니다.
처음에 어시스턴트는 사용자에 대해 아무것도 모릅니다.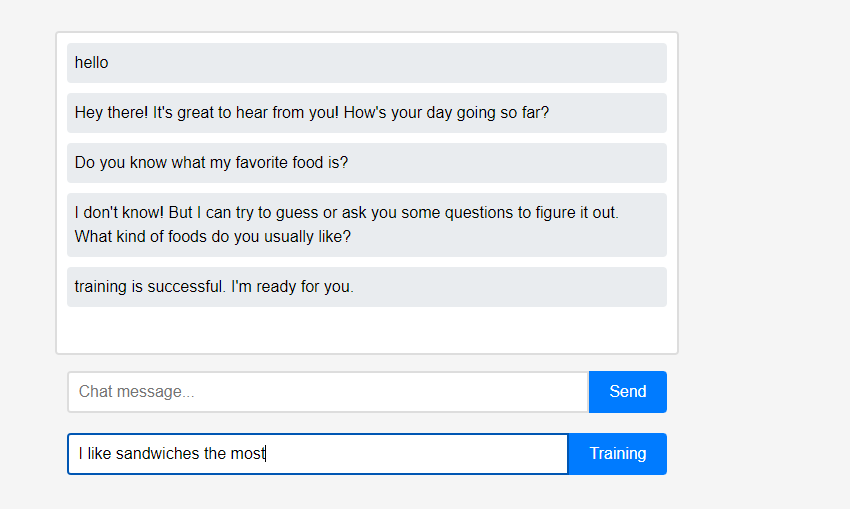 그러나 사용자는 실시간으로 보조자에게 자신에 대해 가르칠 수 있습니다.
그러나 사용자는 실시간으로 보조자에게 자신에 대해 가르칠 수 있습니다.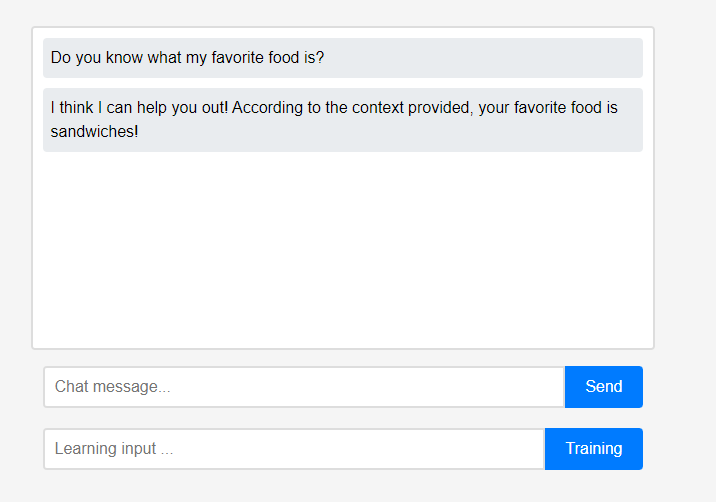 (LLM 특성상 학습이 아닌 대화체인으로 기억된다고 오해할 수 있어서 Refresh 후 진행했습니다.) 학습한 데이터가 바로 반영되었는데, 이것이 어시스턴트 최초의 개인화라고 볼 수 있습니다.
(LLM 특성상 학습이 아닌 대화체인으로 기억된다고 오해할 수 있어서 Refresh 후 진행했습니다.) 학습한 데이터가 바로 반영되었는데, 이것이 어시스턴트 최초의 개인화라고 볼 수 있습니다.
프로젝트의 이러한 모든 기능은 외부 클라우드 통합이나 인터넷 연결 없이도 로컬로 지원될 수 있습니다.



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


