dstoolkit km solution accelerator
V1.6

지식 마이닝 솔루션 가속기
이 리포지토리에는 Azure Cognitive Search를 기반으로 하는 엔드투엔드 지식 마이닝 솔루션을 배포하기 위한 모든 코드가 포함되어 있습니다.
이는 Functions, Web App Services, Congitive Services 및 Cognitive Search와 같은 표준 Azure 서비스를 기반으로 구축되었습니다. 프로젝트에 대한 CI/CD 파이프라인을 빠르고 쉽게 설정할 수 있는 배포 파이프라인을 제공합니다.
자세한 문서는 솔루션 위키가 포함된 저장소의 문서 섹션을 참조하세요.
솔루션을 성공적으로 설정하려면 다음 항목에 액세스하거나 프로비저닝해야 합니다.
Azure 구독 또는 대상 리소스 그룹에서 소유자 또는 기여자 역할이 가정됩니다.
이 솔루션 가속기를 배포하려면 README를 참조하세요.
모든 가이드에서 제공되는 지침에서는 사용자가 Azure Portal, Azure Functions, Azure Cognitive Search, Functions, Storage 및 Azure Cognitives Services에 대한 기본적인 실무 지식을 가지고 있다고 가정합니다.
추가 교육 및 지원은 다음을 참조하세요.
지식 마이닝(KM)은 지능형 서비스의 조합을 사용하여 방대한 양의 정보로부터 빠르게 학습하는 인공 지능(AI)의 새로운 분야입니다. 이를 통해 조직은 정보를 깊이 이해하고 쉽게 탐색하며 숨겨진 통찰력을 발견하고 대규모 관계와 패턴을 찾을 수 있습니다.
Azure의 지식 마이닝
이 KM 솔루션 가속기는 다음으로 구성된 실행 가능한 엔드투엔드 지식 마이닝 솔루션을 제공하는 것을 목표로 합니다.
이 클라우드 기반 가속기를 사용하면 배포, 확장, 운영 및 모니터링 도구를 갖춘 엔드투엔드 솔루션을 얻을 수 있습니다.
그런 점에서 솔루션은
이 지식 마이닝 솔루션 가속기는 다른 가속기 지식 마이닝 솔루션 가속기에서 영감을 받았습니다.
현장 경험을 바탕으로 우리는 유용성 및 데이터 탐색 경험에 중점을 두고 일반적인 구조화되지 않은 데이터 문제를 해결하기 위한 기능/기술을 구축했습니다.
다음은 주요 하이라이트의 대략적인 목록입니다.
임베디드 이미지 인덱싱
이미지 정규화 :
메타데이터
HTML 변환
테이블 추출 : 비정형 데이터 코퍼스에서는 테이블 형식의 정보가 일반적입니다. 솔루션은 전용 지식 저장소(선택 사항)에 테이블을 추출하고 색인화하며 프로젝트합니다.
번역 ": 이 솔루션에는 두 가지 번역 기능이 있습니다.
텍스트 분석 : 모든 문서 및 OCR 이미지 텍스트에서 엔터티(이름이 지정되고 연결됨)를 추출합니다.
Excel로 내보내기 : 구조화되지 않은 데이터를 탐색할 때 자주 묻는 질문입니다.
구성 가능한 UI : UI를 구축하는 데는 시간이 많이 소요됩니다. 우리는 뛰어난 UI 구성 가능성을 제공하여 적시에 새로운 KM 솔루션에 생명을 불어넣고 싶었습니다.
이 솔루션 가속기 정신은 Content Research KM 시나리오입니다.
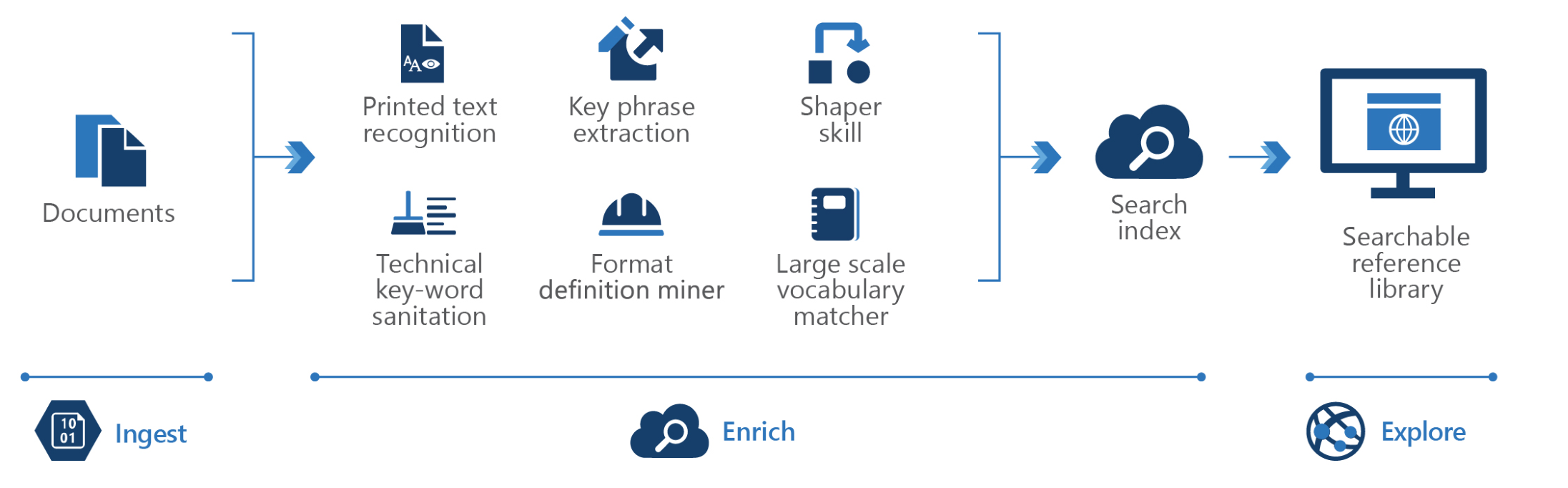
그럼에도 불구하고 해당 아키텍처는 개방형이므로 보다 전문화된 KM 시나리오의 기반으로 사용할 수 있습니다.
이 솔루션 가속기는 확장성을 통해 특정 도메인으로 만들 수 있는 도구를 제공하지만 특정 도메인을 대상으로 하지 않습니다.
영감을 주는 사용 사례
조직을 위한 가속기와 같은 제품화를 생각할 수도 있습니다.
이 솔루션 가속기는 다음이 필요한 사람을 대상으로 합니다.
이 솔루션 가속기의 목적은 데이터 과학 모듈을 지식 마이닝 솔루션에 쉽게 통합하는 것입니다.
Data Science Toolkit 팀은 데이터 과학 워크로드를 위한 가속기를 구축했습니다.
| 해결책 | 설명 |
|---|---|
| 유연성 | Verseagility는 맞춤형 자연어 처리(NLP) 작업을 강화하는 Python 기반 툴킷으로, 자체 데이터를 가져오고 선호하는 프레임워크를 사용하며 모델을 프로덕션으로 가져올 수 있습니다. 이는 Microsoft Data Science Toolkit의 핵심 구성 요소입니다. |
| MLOps 베이스 | 이 리포지토리에는 Azure 기술(Azure ML 및 Azure DevOps)을 기반으로 하는 기계 학습 프로젝트를 위한 기본 리포지토리 구조가 포함되어 있습니다. 폴더 이름과 파일은 개인적인 경험을 바탕으로 선택됩니다. 자체 프로젝트 및 MLOps 프로세스를 사용자 지정할 때 따르도록 권장되는 구조 뒤에 있는 원칙과 아이디어를 찾을 수 있습니다. 또한 사용자가 Azure Machine Learning 개념과 기술 사용 방법에 익숙할 것으로 기대합니다. |
| DataBricks용 MLOps | 이 리포지토리에는 Azure 기술을 기반으로 하는 데이터 엔지니어링 프로젝트 및 기계 학습 프로젝트를 제공하기 위한 Databricks 개발 프레임워크가 포함되어 있습니다. |
| 분류 솔루션 가속기 | 이 리포지토리에는 Azure 기술(Azure ML 및 Azure DevOps)을 기반으로 하는 기계 학습(ML) 프로젝트를 위한 분류 솔루션을 제공하기 위한 기본 리포지토리 구조가 포함되어 있습니다. |
| 개체 감지 솔루션 가속기 | 이 리포지토리에는 Azure 컴퓨팅 학습, 실험 모니터링 및 웹 서비스로서의 엔드포인트 배포를 위한 설정을 통해 AML(Azure Machine Learning) 내에서 TensorFlow 개체 감지 모델을 학습하기 위한 모든 코드가 포함되어 있습니다. MLOps Accelerator를 기반으로 구축되었으며 엔드투엔드 교육 및 배포 파이프라인을 제공하여 프로젝트에 대한 CI/CD 파이프라인을 빠르고 쉽게 설정할 수 있습니다. |
다음과 같이 솔루션 가속기 설명서를 참조할 수 있습니다.
| 주제 | 설명 | 문서 링크 |
|---|---|---|
| 사전 요구 사항 | 솔루션을 배포하고 운영하려면 무엇이 필요합니까? | 읽어보기 |
| 건축학 | 솔루션 구성 방식 | 읽어보기 |
| 전개 | 이 솔루션 가속기를 배포하는 방법 | 읽어보기 |
| 구성 | 솔루션 가속기 구성에 대해 알아야 할 모든 것 | 읽어보기 |
| 데이터 과학 | 데이터 과학과의 통합 | 읽어보기 |
| 전개 | 솔루션 배포를 시작하려면 Ho | 읽어보기 |
| 모니터링 | 솔루션을 모니터링하는 방법 | 읽어보기 |
| 찾다 | 검색 구성 및 관리 방법 | 읽어보기 |
| 검색 및 탐색(UI) | 검색 및 탐색을 위한 사용자 인터페이스 | 읽어보기 |
이 가속기의 저장소 구조는 다음과 같습니다.
이 리포지토리를 복제하거나 다운로드한 다음 배포 가이드에 설명된 단계에 따라 배포 폴더로 이동하세요.
모든 단계를 완료하면 데이터 원본 수집과 데이터 강화 기술 및 Azure Cognitive Search에서 제공하는 웹앱을 결합하는 작동하는 엔드투엔드 지식 마이닝 솔루션을 갖게 됩니다.
이 솔루션은 원본 작업에서 영감을 얻었습니다.
이 솔루션 가속기의 핵심 기여자는 다음과 같습니다.
데이터 과학 툴킷 후원팀
지식 마이닝 및 비정형 데이터에 대한 훌륭한 대화를 위해
이 프로젝트는 기여와 제안을 환영합니다. 대부분의 기여는 귀하가 귀하의 기여를 사용할 수 있는 권리를 갖고 있으며 실제로 그렇게 하고 있음을 선언하는 기여자 라이센스 계약(CLA)에 동의해야 합니다. 자세한 내용을 보려면 https://cla.opensource.microsoft.com을 방문하세요.
끌어오기 요청을 제출하면 CLA 봇이 자동으로 CLA 제공이 필요한지 여부를 결정하고 PR을 적절하게 장식합니다(예: 상태 확인, 댓글). 봇이 제공하는 지침을 따르기만 하면 됩니다. CLA를 사용하여 모든 저장소에서 이 작업을 한 번만 수행하면 됩니다.
이 프로젝트는 Microsoft 오픈 소스 행동 강령을 채택했습니다. 자세한 내용은 행동 강령 FAQ를 참조하거나 추가 질문이나 의견이 있는 경우 [email protected]으로 문의하세요.
이 프로젝트에는 프로젝트, 제품 또는 서비스에 대한 상표나 로고가 포함될 수 있습니다. Microsoft 상표 또는 로고의 승인된 사용에는 Microsoft의 상표 및 브랜드 지침이 적용되며 이를 따라야 합니다. 이 프로젝트의 수정된 버전에 Microsoft 상표 또는 로고를 사용하면 혼동을 일으키거나 Microsoft 후원을 암시해서는 안 됩니다. 제3자 상표 또는 로고의 사용에는 해당 제3자의 정책이 적용됩니다.


