밈 검색 엔진
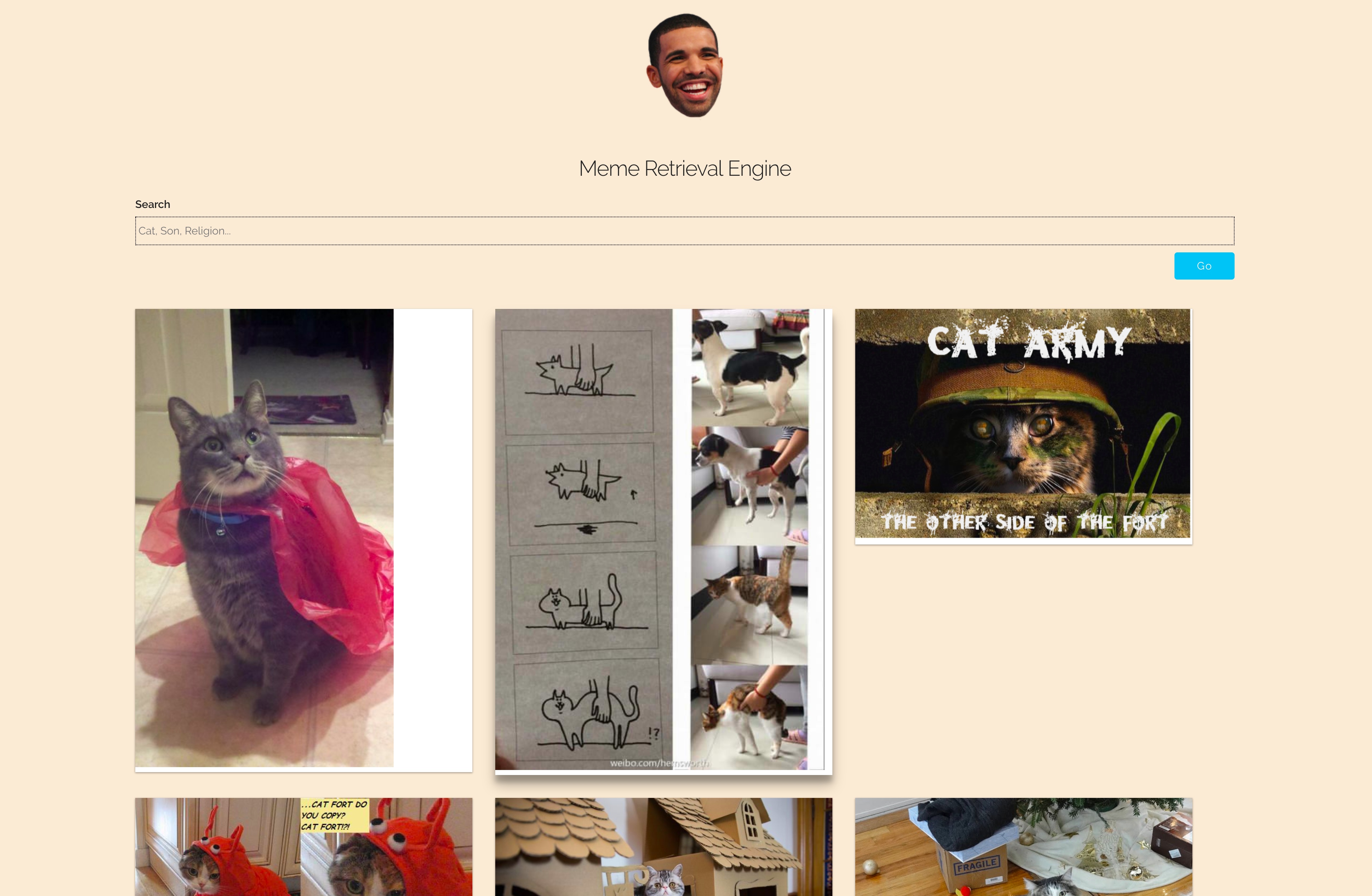
프로젝트 설명
채용된 기술
- 이미지 처리
- 기계 학습
- 자연어 처리
- 쉘 스크립팅
수집
밈은 스크레이퍼 스크립트 scrape/scraper.py 를 사용하여 인기 있는 하위 레딧에서 수집됩니다.
표준화
- 수집된 밈은
raw 폴더에 넣어지고 standard.py 스크립트가 실행됩니다. - 각 파일 이름은 추출되어 이미지에 대해 생성된 새로운 16진수 기반 파일 이름 옆에 있는 텍스트 파일에 저장됩니다.
- 표준화된 이미지는
processed 폴더에 저장됩니다.
쿼리 추출
- 입력된 쿼리는 단어로 분할되고, 각 단어에 대한 동의어는 nltk 라이브러리를 사용하여
related queries 목록에 추가됩니다. -
related queries 의 단어와 단어를 일치시키기 위해 데이터베이스를 스캔합니다. - 이는 검색 영역을 넓히고 제로 출력 시나리오를 최소화합니다.
쿼리와의 관련성
- 밈은 검색어와의 관련성 순서대로 정렬됩니다.
- 이는 데이터베이스에 존재하는 각 밈에 점수를 할당한 다음 점수의 내림차순으로 정렬하여 수행됩니다.
광학 문자 인식
- OCR은 Tesseract를 사용하여 프로젝트의 필수 부분인 밈에서 텍스트를 추출합니다.
- 추출된 텍스트가 완벽하게 정확하지 않으므로 ocr의 출력이 Python
autocorrect 라이브러리의 맞춤법 검사기에 입력됩니다. - 맞춤법 검사기를 사용하면 변환이 더 정확해집니다.
빠른 테스트
GUI를 실행하고 기능을 테스트하려면 다음을 입력하십시오.
수집 및 실행
- Bash 스크립트는 Meme 엔진이 제대로 작동할 수 있도록 데이터베이스를 준비합니다.
- Meme 검색 엔진(Meme Finder)을 실행하려면 다음을 입력하세요.
- 텍스트 필드에 쿼리를 입력하고
Go 을 클릭하세요. - 밈은 관련성을 기준으로 정렬됩니다.
- 선택한 밈은
Next 및 Previous 버튼을 사용하여 찾아볼 수 있습니다.
목록에 새 하위 레딧 추가
요구사항
- cv2 (OpenCV)
- 피테세랙트
- nltk
- 필
- 해시립
- 종료
- 자동 수정
- 피몽고
향후 개선 사항
- 진행률 표시줄에 기능 추가
- 캔버스에 표시할 밈의 크기 배율을 수정합니다.
- 저장된 밈을 플러시하는 기능 추가
- 인기 있는 밈 템플릿을 저장하고 이미지의 유사성을 확인하고 특수 키워드를 연결합니다.
선적 서류 비치
MemeFinder 문서


