idt
1.0.0

IDT(이미지 데이터세트 도구)는 딥러닝에 사용할 이미지 데이터세트를 보다 쉽고 빠르게 생성할 수 있도록 개발된 CLI 앱입니다. 이 도구는 duckgo, bing 및 deviantart와 같은 여러 검색 엔진에서 이미지를 스크랩하여 이를 달성합니다. IDT는 또한 이미지 데이터 세트를 최적화합니다. 이 기능은 선택 사항이지만 사용자는 최적의 파일 크기와 크기에 맞게 이미지를 축소하고 압축할 수 있습니다. 총 23,688개의 이미지 파일을 포함하는 idt를 사용하여 생성된 샘플 데이터 세트의 무게는 559,2MB에 불과합니다.
최신 버전을 발표하게 된 것을 자랑스럽게 생각합니다! ??
무엇이 바뀌었나
pip를 통해 설치하거나 이 저장소를 복제할 수 있습니다.
user@admin:~ $ pip3 install idt
또는
user@admin:~ $ git clone https://github.com/deliton/idt.git && cd idt
user@admin:~/idt $ sudo python3 setup.py install
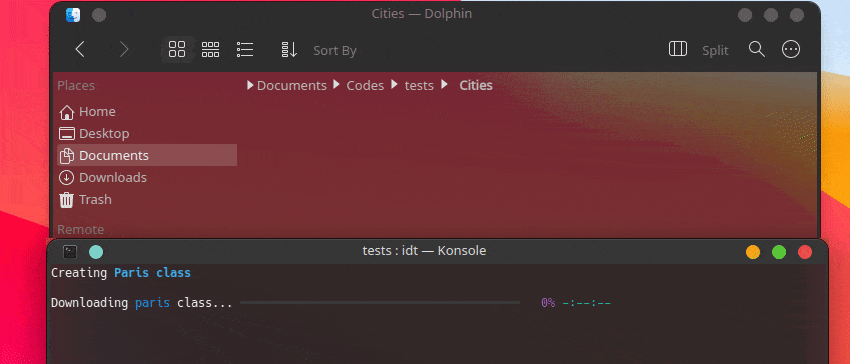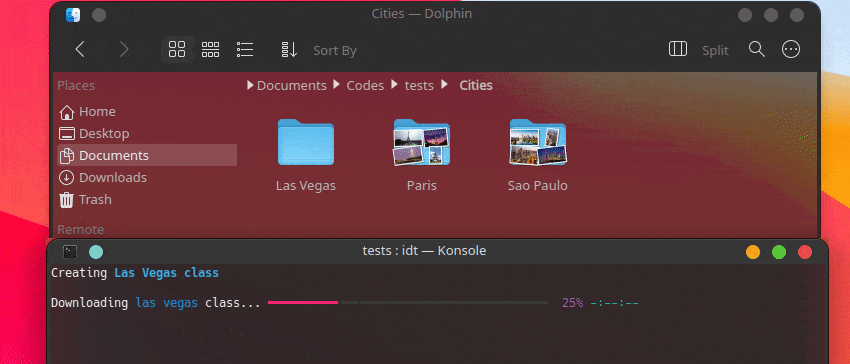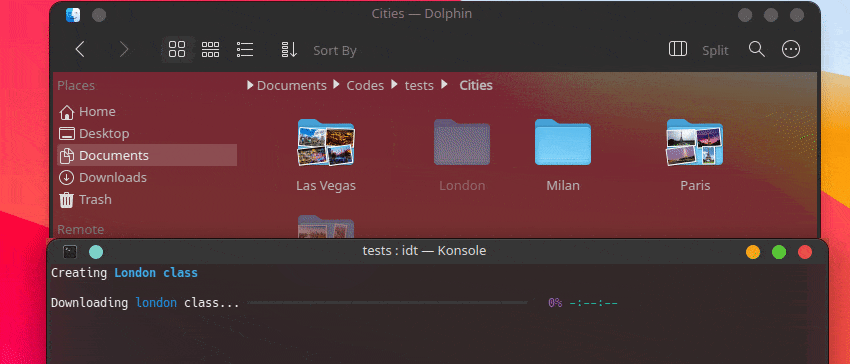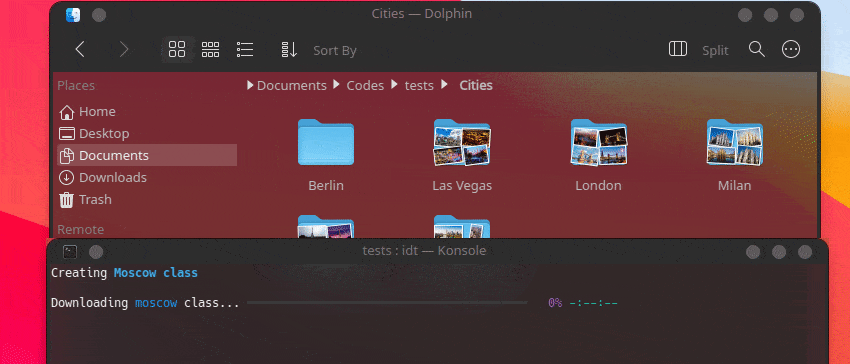
IDT를 시작하는 가장 빠른 방법은 간단한 "실행" 명령을 실행하는 것입니다. 즐겨 사용하는 콘솔에 다음과 같이 작성하세요.
user@admin:~ $ idt run -i apples 그러면 사과 이미지 50개가 빠르게 다운로드됩니다. 이를 위해 기본적으로 duckgo 검색 엔진을 사용합니다. run 명령은 다음 옵션을 허용합니다.
| 옵션 | 설명 |
|---|---|
| -i 또는 --input | 원하는 이미지를 찾기 위한 키워드입니다. |
| -s 또는 --size | 다운로드할 이미지의 양. |
| -e 또는 --engine | 원하는 검색 엔진(옵션: duckgo, bing, bing_api 및 flickr_api) |
| --크기 조정 방법 | 이미지 크기 조정 방법을 선택합니다. (옵션: 긴 쪽, 짧은 쪽 및 smartcrop) |
| -is 또는 --이미지 크기 | 원하는 이미지 크기 비율을 설정하는 옵션입니다. 기본값=512 |
| -ak 또는 --api-key | API 키가 필요한 검색 엔진을 사용하는 경우 이 옵션은 필수입니다. |
IDT에는 데이터세트 구성 방법을 알려주는 구성 파일이 필요합니다. 다음 명령을 사용하여 만들 수 있습니다.
user@admin:~ $ idt init이 명령은 구성 파일 생성기를 트리거하고 원하는 데이터세트 매개변수를 요청합니다. 이 예에서는 좋아하는 자동차의 이미지가 포함된 데이터세트를 만들어 보겠습니다. 이 명령이 묻는 첫 번째 매개변수는 데이터 세트의 이름이 무엇이어야 하는지입니다. 이 예에서는 데이터 세트 이름을 "My favorite cars"로 지정하겠습니다.
Insert a name for your dataset: : My favorite cars그런 다음 도구는 데이터세트를 탑재하는 데 필요한 검색당 샘플 수를 묻습니다. 딥러닝을 위한 좋은 데이터 세트를 구축하려면 많은 이미지가 필요하며, 이미지를 스크랩하기 위해 검색 엔진을 사용하기 때문에 적당한 크기의 데이터 세트를 마운트하려면 다양한 키워드로 많은 검색이 필요합니다. 이 값은 검색할 때마다 다운로드해야 하는 이미지 수에 해당합니다. 이 예에서는 각 클래스에 250개의 이미지가 있는 데이터 세트가 필요하며 5개의 키워드를 사용하여 각 클래스를 마운트합니다. 따라서 여기에 숫자 50을 입력하면 IDT는 제공된 모든 키워드의 이미지 50개를 다운로드합니다. 5개의 키워드를 제공하면 필요한 250개의 이미지를 얻을 수 있습니다.
How many samples per search will be necessary? : 50이제 도구에서 이미지 크기 비율을 묻습니다. 신경망을 훈련하기 위해 큰 이미지를 사용하는 것은 실행 가능한 것이 아니기 때문에 선택적으로 다음 이미지 크기 비율 중 하나를 선택하고 이미지를 해당 크기로 축소할 수 있습니다. 이 예에서는 512x512를 사용하지만 이 작업에는 256x256이 더 나은 옵션입니다.
Choose images resolution:
[1] 512 pixels / 512 pixels (recommended)
[2] 1024 pixels / 1024 pixels
[3] 256 pixels / 256 pixels
[4] 128 pixels / 128 pixels
[5] Keep original image size
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
What is the desired image size ratio: 1그런 다음 크기 조정 방법으로 "longer_side"를 선택합니다.
[1] Resize image based on longer side
[2] Resize image based on shorter side
[3] Smartcrop
ps: note that the aspect ratio of the image will not be changed,
so possibly the images received will have slightly different size
Desired Image resize method: : longer_side
이제 데이터세트에 포함되어야 하는 클래스/폴더 수를 선택해야 합니다. 이 예에서 이 부분은 매우 개인적일 수 있지만 제가 가장 좋아하는 자동차는 Chevrolet Impala, Range Rover Evoque, Tesla Model X 및 AvtoVAZ Lada입니다. 따라서 이 경우에는 즐겨찾는 클래스별로 하나씩 총 4개의 클래스가 있습니다.
How many image classes are required? : 4그 후에는 사용 가능한 검색 엔진 중 하나를 선택하라는 메시지가 표시됩니다. 이 예에서는 DuckGO를 사용하여 이미지를 검색해 보겠습니다.
Choose a search engine:
[1] Duck GO (recommended)
[2] Bing
[3] Bing API
[4] Flickr API
Select option:: 1이제 우리는 반복적인 양식 작성을 수행해야 합니다. 이미지를 찾는 데 사용될 각 클래스와 모든 키워드의 이름을 지정해야 합니다. 이 부분은 나중에 자신의 코드로 변경되어 더 많은 클래스와 키워드를 생성할 수 있습니다.
Class 1 name: : Chevrolet Impala첫 번째 클래스 이름을 입력한 후 데이터 세트를 찾기 위해 모든 키워드를 제공하라는 메시지가 표시됩니다. 프로그램에 각 키워드에 대해 50개의 이미지를 다운로드하도록 지시했으므로 이 경우 250개의 이미지를 모두 얻으려면 5개의 키워드를 제공해야 합니다. 각 키워드는 쉼표(,)로 구분되어야 합니다.
In order to achieve better results, choose several keywords that will
be provided to the search engine to find your class in different settings.
Example:
Class Name: Pineapple
keywords: pineapple, pineapple fruit, ananas, abacaxi, pineapple drawing
Type in all keywords used to find your desired class, separated by commas: Chevrolet Impala 1967 car photos,
chevrolet impala on the road, chevrolet impala vintage car, chevrolet impala convertible 1961, chevrolet impala 1964 lowrider
그런 다음 필요한 4개 수업을 모두 채울 때까지 수업 이름과 키워드를 채우는 과정을 반복하세요.
Dataset YAML file has been created successfully. Now run idt build to mount your dataset!데이터 세트 구성 파일이 생성되었습니다. 이제 다음 명령을 실행하면 마법이 일어나는 것을 볼 수 있습니다.
user@admin:~ $ idt build그리고 데이터 세트가 마운트되는 동안 기다립니다.
Creating Chevrolet Impala class
Downloading Chevrolet Impala 1967 car photos [#########################-----------] 72% 00:00:12
결국 모든 이미지는 데이터 세트 이름이 있는 폴더에서 사용할 수 있습니다. 또한 데이터세트 통계가 포함된 csv 파일도 데이터세트의 루트 폴더에 포함되어 있습니다.
딥러닝에서는 종종 데이터 세트를 훈련/검증 폴더의 하위 집합으로 분할해야 하므로 이 프로젝트도 이 작업을 수행할 수 있습니다! 그냥 실행하세요:
user@admin:~ $ idt split이제 기차/유효한 비율을 선택해야 합니다. 이 예에서는 이미지의 70%가 훈련용으로 예약되고 나머지는 검증용으로 예약되도록 선택했습니다.
Choose the desired proportion of images of each class to be distributed in train/valid folders.
What percentage of images should be distributed towards training?
(0-100): 70
70 percent of the images will be moved to a train folder, while 30 percent of the remaining images
will be stored in a validation folder.
Is that ok? [Y/n]: y그리고 그게 다야! 이제 해당 train/valid 하위 디렉터리에서 데이터세트 분할을 찾을 수 있습니다.
이 프로젝트는 여가 시간에 개발되고 있으며 버그가 발생하지 않으려면 여전히 많은 노력이 필요합니다. 끌어오기 요청과 기여자에게 정말 감사드립니다. 어떤 방식으로든 자유롭게 기여해 주세요!


