T5Elasticsearch
1.0.0
다음은 채용정보 검색 예시입니다.
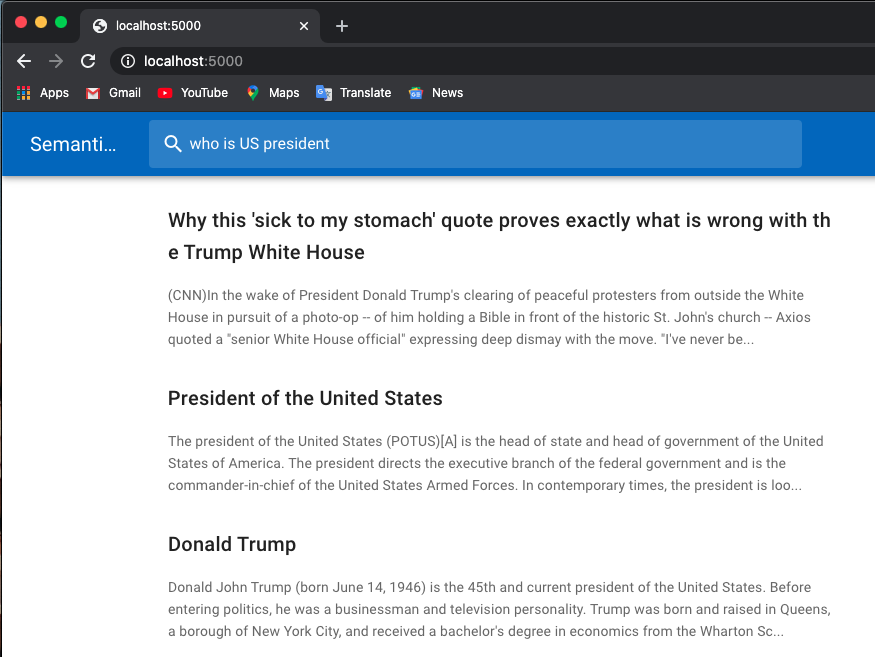
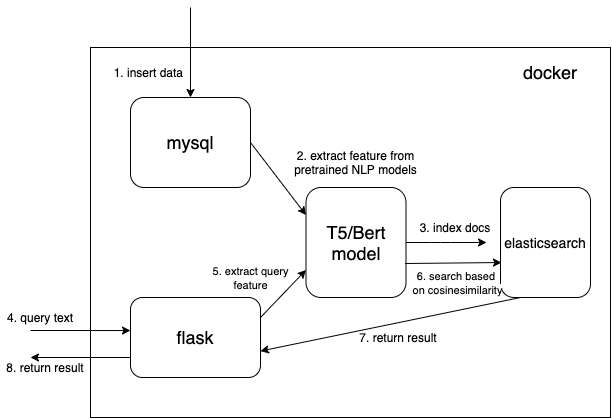
나는 Huggingface Transformers의 사전 훈련된 모델을 사용합니다.
사전 학습된 토크나이저 및 t5/bert 모델을 로컬 디렉터리에 수동으로 다운로드합니다. 여기에서 모델을 확인할 수 있습니다.
저는 't5-small' 모델을 사용하고 있는데 여기를 체크한 후 List all files in model 클릭하여 파일을 다운로드합니다. 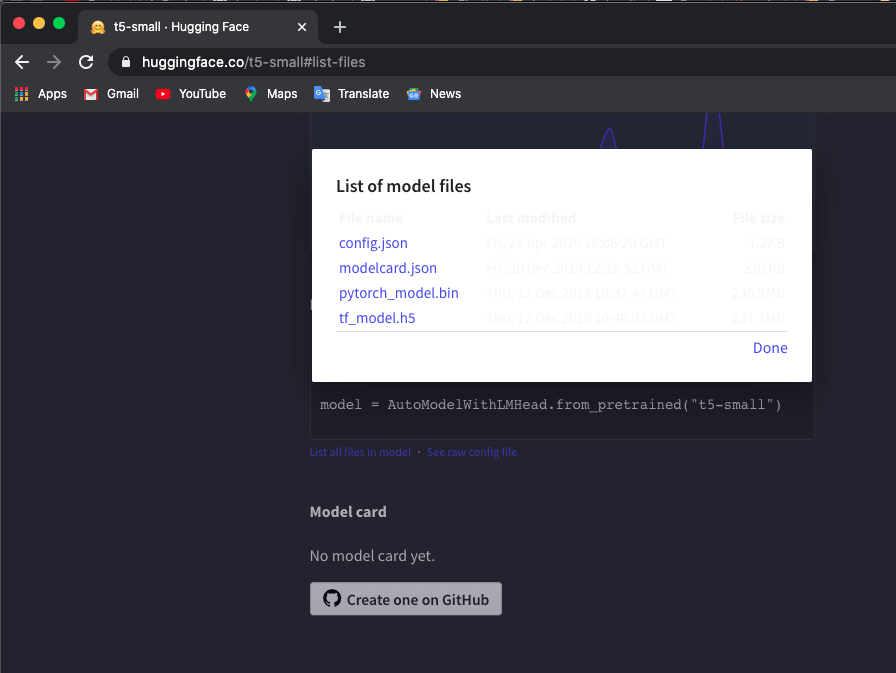
수동으로 다운로드한 파일 디렉터리 구조를 확인하세요.
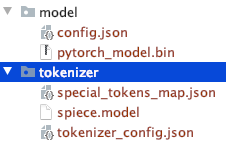
다른 T5 또는 Bert 모델을 사용할 수 있습니다.
다른 모델을 다운로드하신 경우, 휴가페이스 트랜스포머 사전 테스트 모델 목록을 확인하여 모델명을 확인하세요.
$ export TOKEN_DIR=path_to_your_tokenizer_directory/tokenizer
$ export MODEL_DIR=path_to_your_model_directory/model
$ export MODEL_NAME=t5-small # or other model you downloaded
$ export INDEX_NAME=docsearch$ docker-compose up --build 또한 더 많은 메모리를 얻기 위해 사용하지 않는 모든 컨테이너, 네트워크 및 이미지를 제거하기 위해 docker system prune 사용합니다. Container exits with non-zero exit code 137 발생하는 경우 도커 메모리를 늘리십시오( 8GB 사용).
우리는 사전 훈련된 NLP 모델에서 추출된 특징을 저장하기 위해 조밀한 벡터 데이터 유형을 사용합니다(여기서는 t5 또는 bert이지만 관심 있는 사전 훈련된 모델을 직접 추가할 수 있습니다).
{
...
"text_vector" : {
"type" : " dense_vector " ,
"dims" : 512
}
...
} 치수 dims:512 T5 모델용입니다. Bert 모델을 사용하는 경우 dims 768로 변경하세요.
mysql에서 문서를 읽고 문서를 올바른 json 형식으로 변환하여 Elasticsearch로 대량 변환하세요.
$ cd index_files
$ pip install -r requirements.txt
$ python indexing_files.py
# or you can customize your parameters
# $ python indexing_files.py --index_file='index.json' --index_name='docsearch' --data='documents.jsonl'http://127.0.0.1:5000으로 이동합니다.
사전 학습된 모델을 사용하여 기능을 추출하기 위한 핵심 코드는 ./index_files/indexing_files.py 및 ./web/app.py 파일의 get_emb 함수입니다.
def get_emb ( inputs_list , model_name , max_length = 512 ):
if 't5' in model_name : #T5 models, written in pytorch
tokenizer = T5Tokenizer . from_pretrained ( TOKEN_DIR )
model = T5Model . from_pretrained ( MODEL_DIR )
inputs = tokenizer . batch_encode_plus ( inputs_list , max_length = max_length , pad_to_max_length = True , return_tensors = "pt" )
outputs = model ( input_ids = inputs [ 'input_ids' ], decoder_input_ids = inputs [ 'input_ids' ])
last_hidden_states = torch . mean ( outputs [ 0 ], dim = 1 )
return last_hidden_states . tolist ()
elif 'bert' in model_name : #Bert models, written in tensorlow
tokenizer = BertTokenizer . from_pretrained ( 'bert-base-multilingual-cased' )
model = TFBertModel . from_pretrained ( 'bert-base-multilingual-cased' )
batch_encoding = tokenizer . batch_encode_plus ([ "this is" , "the second" , "the thrid" ], max_length = max_length , pad_to_max_length = True )
outputs = model ( tf . convert_to_tensor ( batch_encoding [ 'input_ids' ]))
embeddings = tf . reduce_mean ( outputs [ 0 ], 1 )
return embeddings . numpy (). tolist ()코드를 변경하고 선호하는 사전 학습된 모델을 사용할 수 있습니다. 예를 들어 GPT2 모델을 사용할 수 있습니다.
.webapp.py 에서 cosineSimilarity 대신 자체 점수 함수를 사용하여 Elasticsearch를 사용자 정의할 수도 있습니다.
이 담당자는 bert 기능을 추출하기 위해 bert-serving 패키지를 사용하는 Hironsan/bertsearch를 기반으로 수정되었습니다. TF1.x로 제한됩니다.


