system design primer
1.0.0
영어 ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελlamnικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ вارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภгษгไทม ∙ Türkçe ∙ tiếng Viet ∙ Français | 번역 추가
이 가이드 번역을 도와주세요!
대규모 시스템을 설계하는 방법을 알아보세요.
시스템 설계 인터뷰를 준비하세요.
확장 가능한 시스템을 설계하는 방법을 배우면 더 나은 엔지니어가 되는 데 도움이 됩니다.
시스템 설계는 광범위한 주제입니다. 시스템 설계 원칙에 따라 웹 전체에 방대한 양의 리소스가 흩어져 있습니다.
이 저장소는 규모에 맞게 시스템을 구축하는 방법을 배우는 데 도움이 되는 체계적인 리소스 모음 입니다.
이것은 지속적으로 업데이트되는 오픈 소스 프로젝트입니다.
기여를 환영합니다!
코딩 인터뷰 외에도 시스템 설계는 많은 기술 회사의 기술 인터뷰 프로세스 에서 필수 구성 요소 입니다.
일반적인 시스템 설계 인터뷰 질문을 연습 하고 결과를 샘플 솔루션 (토론, 코드, 다이어그램)과 비교하세요 .
인터뷰 준비를 위한 추가 주제:
제공된 Anki 플래시카드 데크는 간격 반복을 사용하여 핵심 시스템 설계 개념을 유지하는 데 도움을 줍니다.
이동 중에도 사용하기에 좋습니다.
코딩 인터뷰를 준비하는 데 도움이 되는 리소스를 찾고 계십니까?
추가 Anki 데크가 포함된 자매 저장소인 Interactive Coding Challenges를 확인하세요.
커뮤니티에서 배우세요.
도움을 받으려면 언제든지 끌어오기 요청을 제출하세요.
약간의 다듬질이 필요한 콘텐츠가 개발 중입니다.
기여 지침을 검토하세요.
장점과 단점을 포함한 다양한 시스템 설계 주제를 요약합니다. 모든 것은 절충안입니다 .
각 섹션에는 보다 심층적인 리소스에 대한 링크가 포함되어 있습니다.
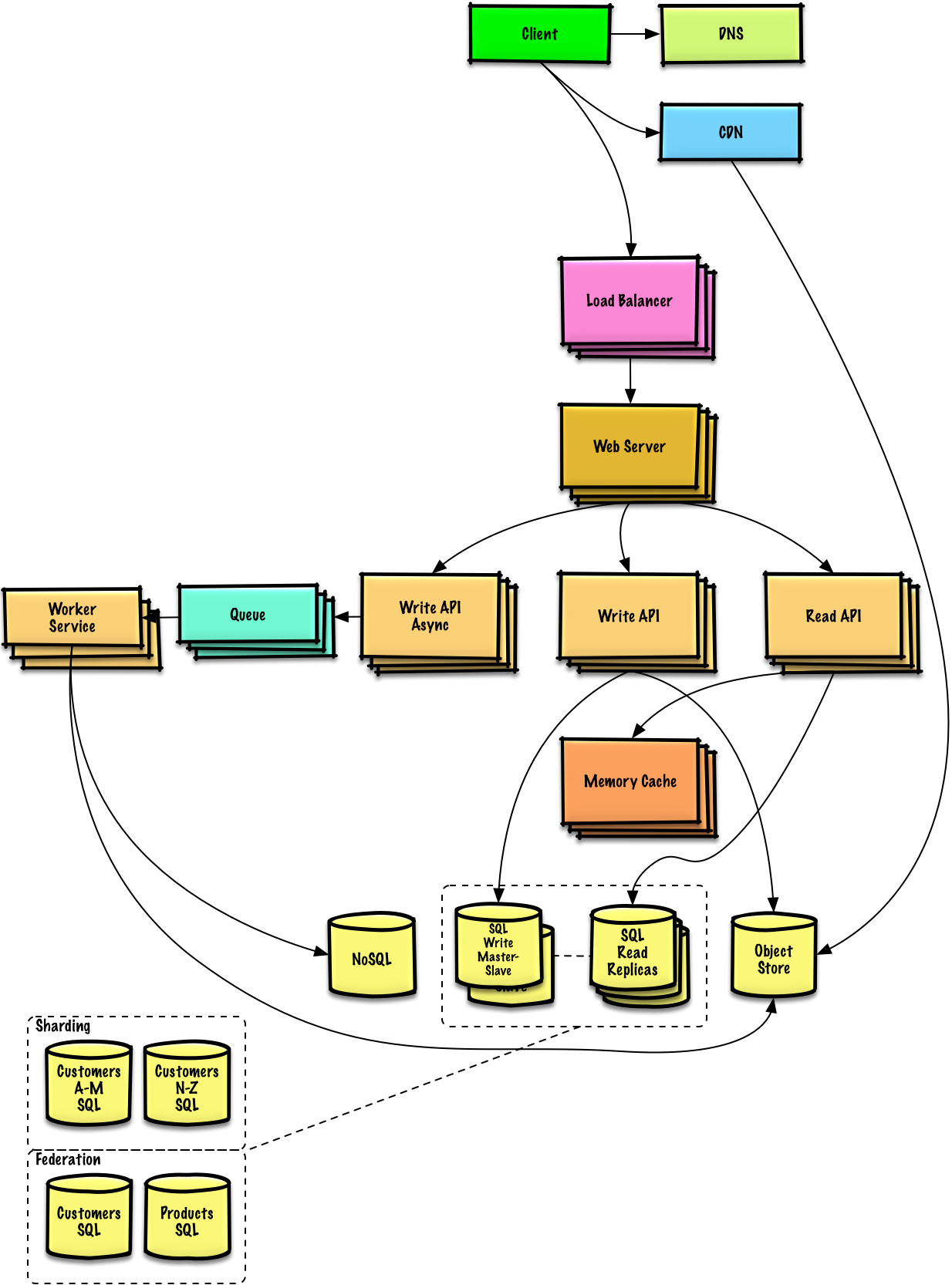
인터뷰 일정(단기, 중간, 장기)에 따라 검토할 제안 주제입니다.
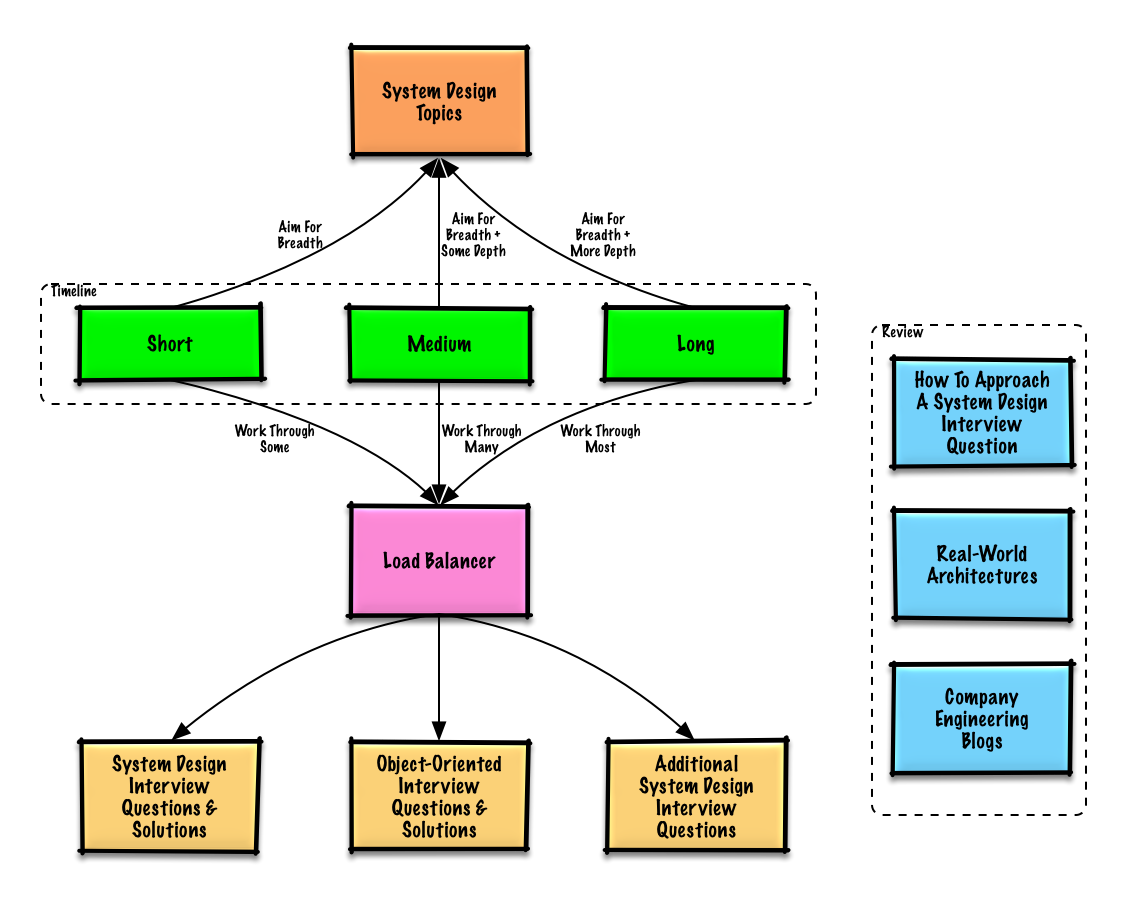
Q: 인터뷰를 하려면 여기에 있는 모든 것을 알아야 합니까?
A: 아니요. 인터뷰를 준비하기 위해 모든 것을 알 필요는 없습니다 .
인터뷰에서 질문하는 내용은 다음과 같은 변수에 따라 달라집니다.
경험이 많은 후보자는 일반적으로 시스템 설계에 대해 더 많이 알 것으로 예상됩니다. 설계자나 팀 리더는 개별 기여자보다 더 많은 것을 알고 있을 것으로 예상됩니다. 최고의 기술 기업은 한 번 이상의 디자인 인터뷰 라운드를 가질 가능성이 높습니다.
광범위하게 시작하여 몇 가지 영역에서 더 깊이 들어가세요. 다양한 주요 시스템 설계 주제에 대해 조금 아는 것이 도움이 됩니다. 귀하의 타임라인, 경험, 면접 대상 직위, 면접 대상 회사에 따라 다음 가이드를 조정하세요.
| 짧은 | 중간 | 긴 | |
|---|---|---|---|
| 시스템 작동 방식을 폭넓게 이해하려면 시스템 디자인 주제를 읽어보세요. | ? | ? | ? |
| 인터뷰 중인 회사에 대한 회사 엔지니어링 블로그의 몇 가지 기사를 읽어보세요. | ? | ? | ? |
| 몇 가지 실제 아키텍처를 읽어보세요. | ? | ? | ? |
| 시스템 설계 인터뷰 질문에 접근하는 방법 검토 | ? | ? | ? |
| 솔루션을 사용하여 시스템 설계 면접 질문을 해결하세요. | 일부 | 많은 | 최대 |
| 솔루션을 사용하여 객체 지향 디자인 면접 질문을 해결하세요. | 일부 | 많은 | 최대 |
| 추가 시스템 설계 인터뷰 질문 검토 | 일부 | 많은 | 최대 |
시스템 설계 면접 질문을 해결하는 방법.
시스템 설계 인터뷰는 개방형 대화 입니다. 이끌어갈 것으로 예상됩니다.
다음 단계를 사용하여 토론을 안내할 수 있습니다. 이 프로세스를 강화하려면 다음 단계를 사용하여 솔루션 섹션이 포함된 시스템 설계 인터뷰 질문을 진행하세요.
요구 사항을 수집하고 문제 범위를 지정합니다. 사용 사례와 제약 조건을 명확히 하기 위해 질문을 하세요. 가정에 대해 토론하십시오.
모든 중요한 구성 요소를 포함하여 높은 수준의 디자인을 개략적으로 설명합니다.
각 핵심 구성요소에 대해 자세히 알아보세요. 예를 들어, URL 단축 서비스를 설계하라는 요청을 받은 경우 다음 사항에 대해 논의하세요.
주어진 제약 조건에 따라 병목 현상을 식별하고 해결합니다. 예를 들어, 확장성 문제를 해결하려면 다음이 필요합니까?
잠재적인 솔루션과 장단점에 대해 논의합니다. 모든 것은 절충안입니다. 확장 가능한 시스템 설계 원칙을 사용하여 병목 현상을 해결합니다.
몇 가지 추정을 직접 수행하라는 요청을 받을 수도 있습니다. 다음 리소스는 부록을 참조하세요.
무엇을 기대할 수 있는지 더 잘 알아보려면 다음 링크를 확인하세요.
샘플 토론, 코드 및 다이어그램이 포함된 일반적인 시스템 설계 인터뷰 질문입니다.
solutions/폴더의 콘텐츠에 링크된 솔루션입니다.
| 질문 | |
|---|---|
| 디자인 Pastebin.com(또는 Bit.ly) | 해결책 |
| Twitter 타임라인 및 검색(또는 Facebook 피드 및 검색) 디자인 | 해결책 |
| 웹 크롤러 디자인 | 해결책 |
| 디자인민트닷컴 | 해결책 |
| 소셜 네트워크의 데이터 구조 설계 | 해결책 |
| 검색 엔진을 위한 키-값 저장소 설계 | 해결책 |
| 아마존의 카테고리별 판매 순위 디자인 기능 | 해결책 |
| AWS에서 수백만 명의 사용자로 확장되는 시스템 설계 | 해결책 |
| 시스템 설계 질문 추가 | 기여하다 |
연습 및 솔루션 보기
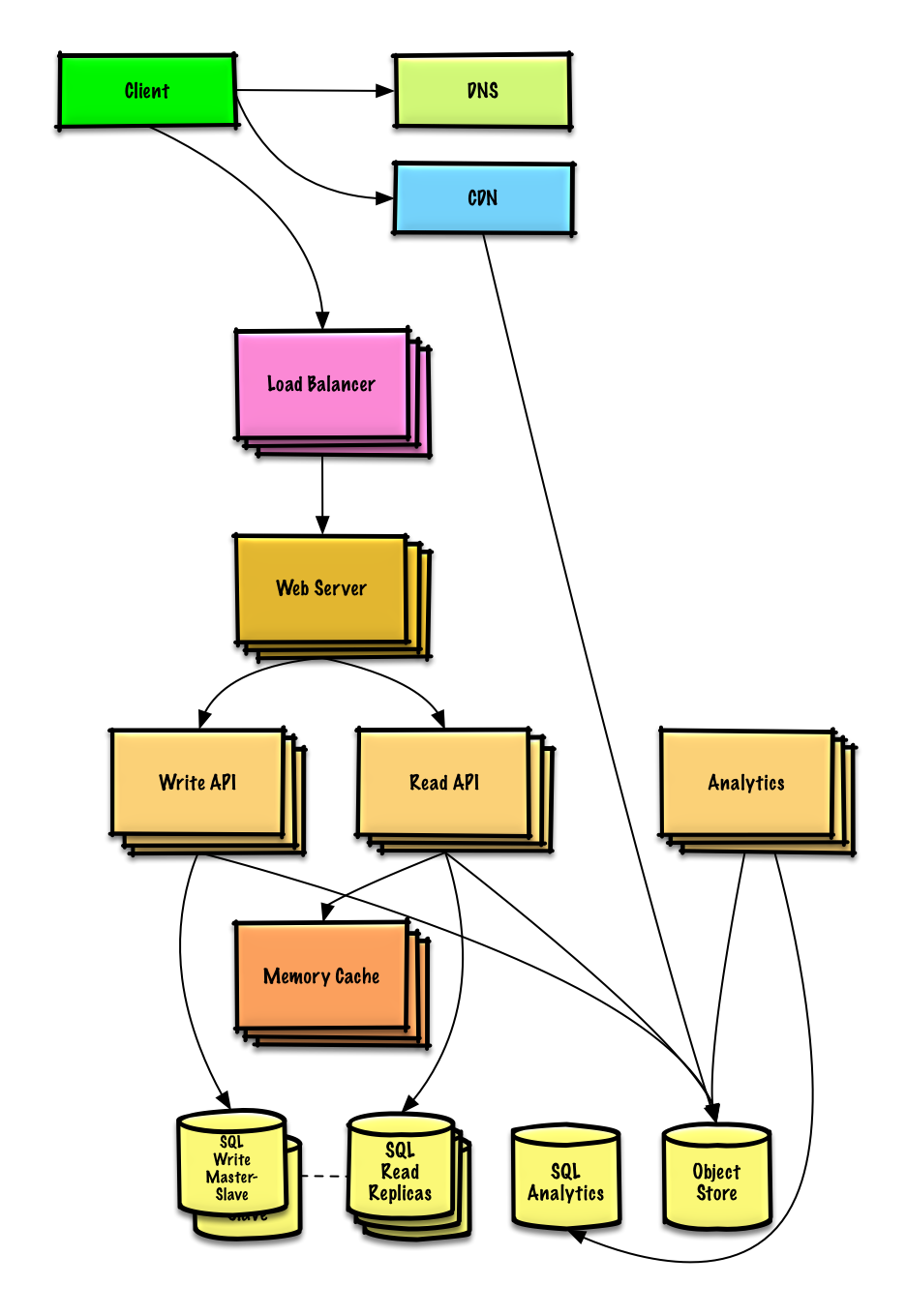
연습 및 솔루션 보기
연습 및 솔루션 보기
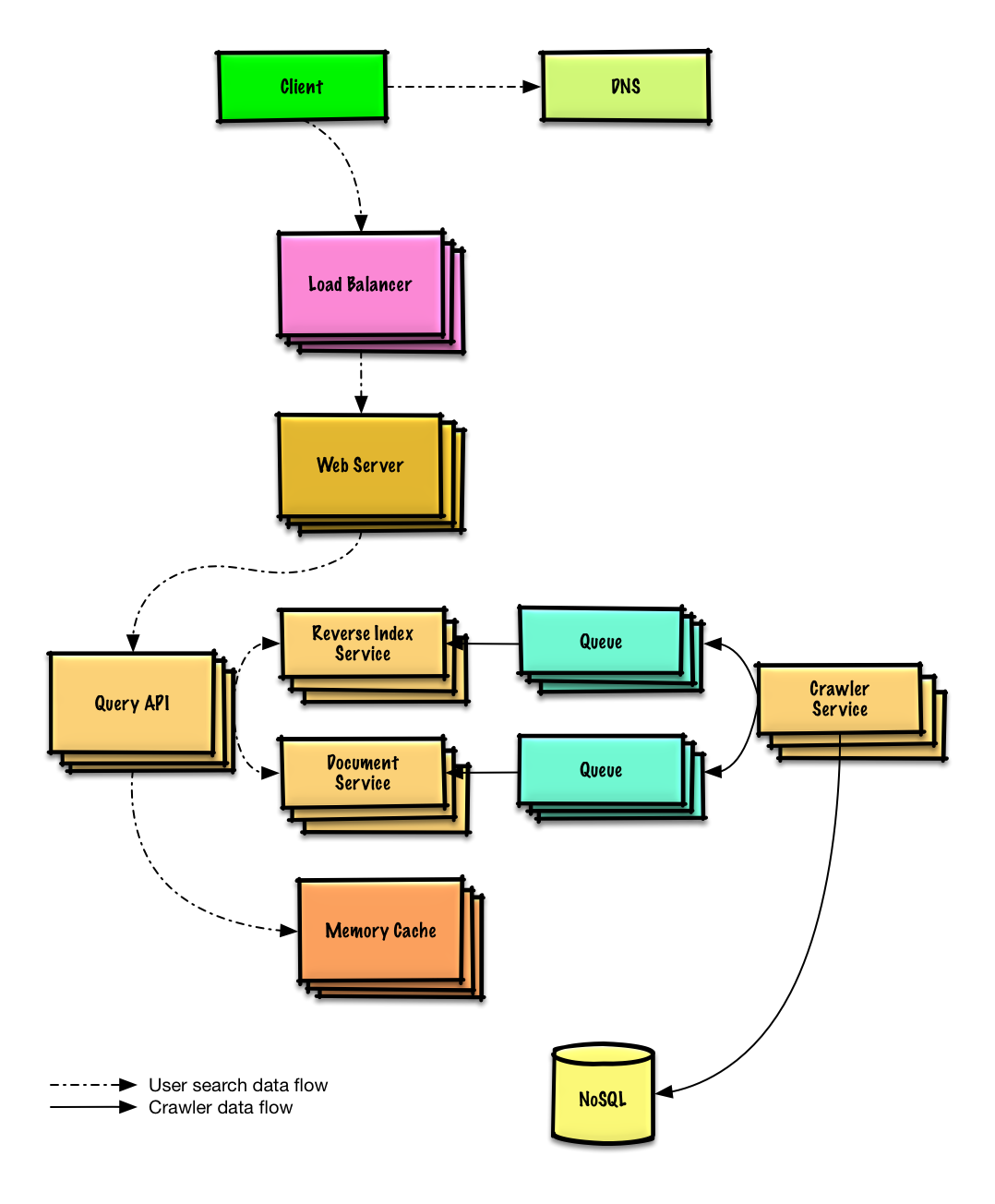
연습 및 솔루션 보기
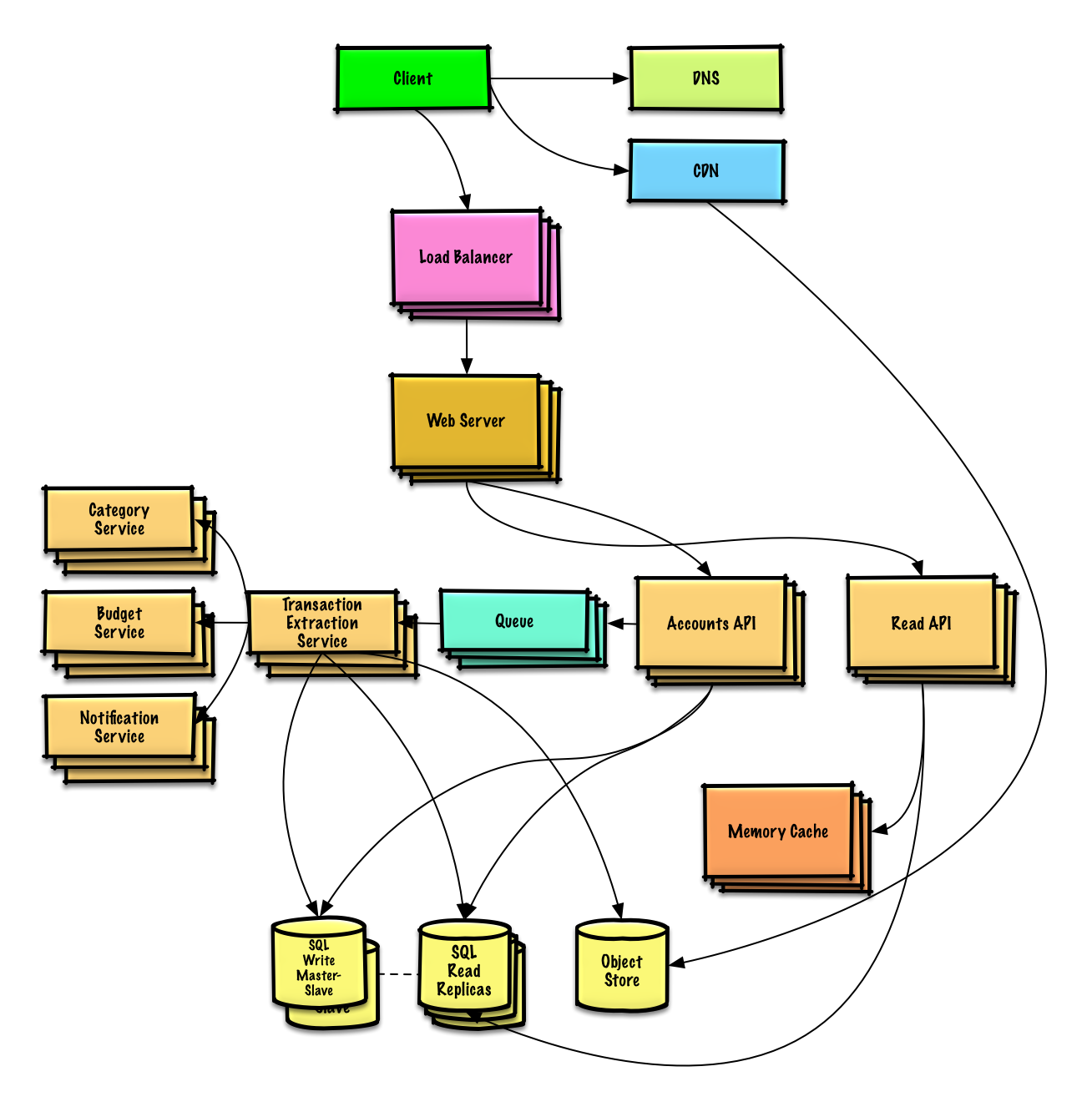
연습 및 솔루션 보기
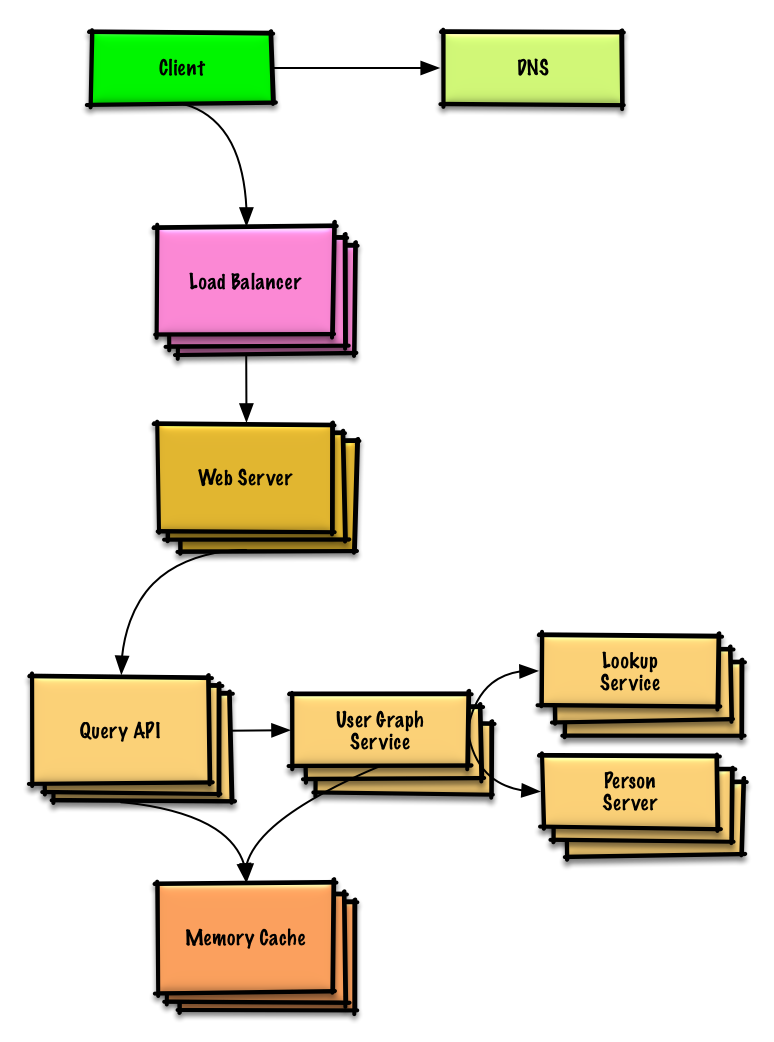
연습 및 솔루션 보기
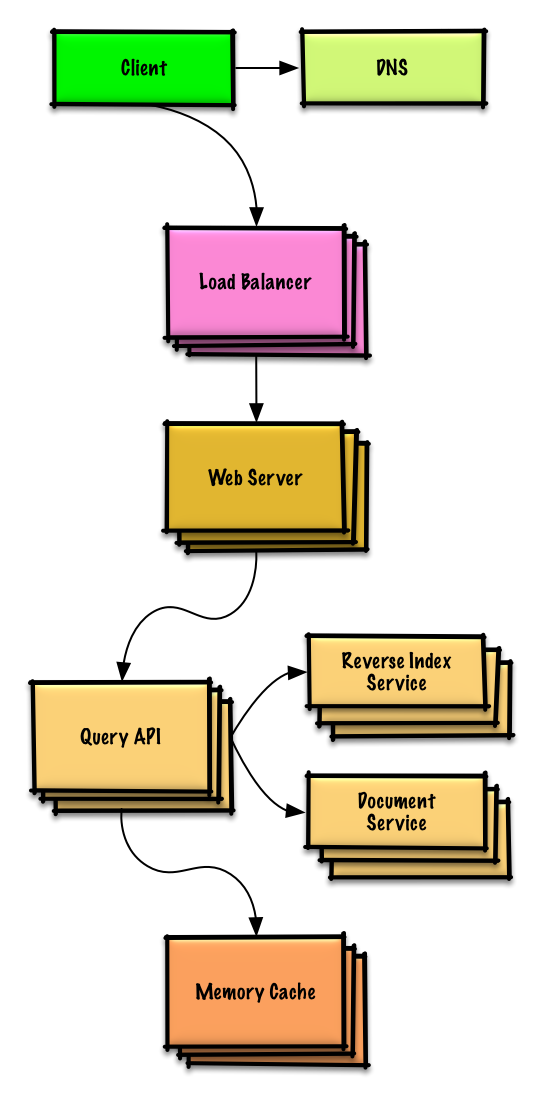
연습 및 솔루션 보기
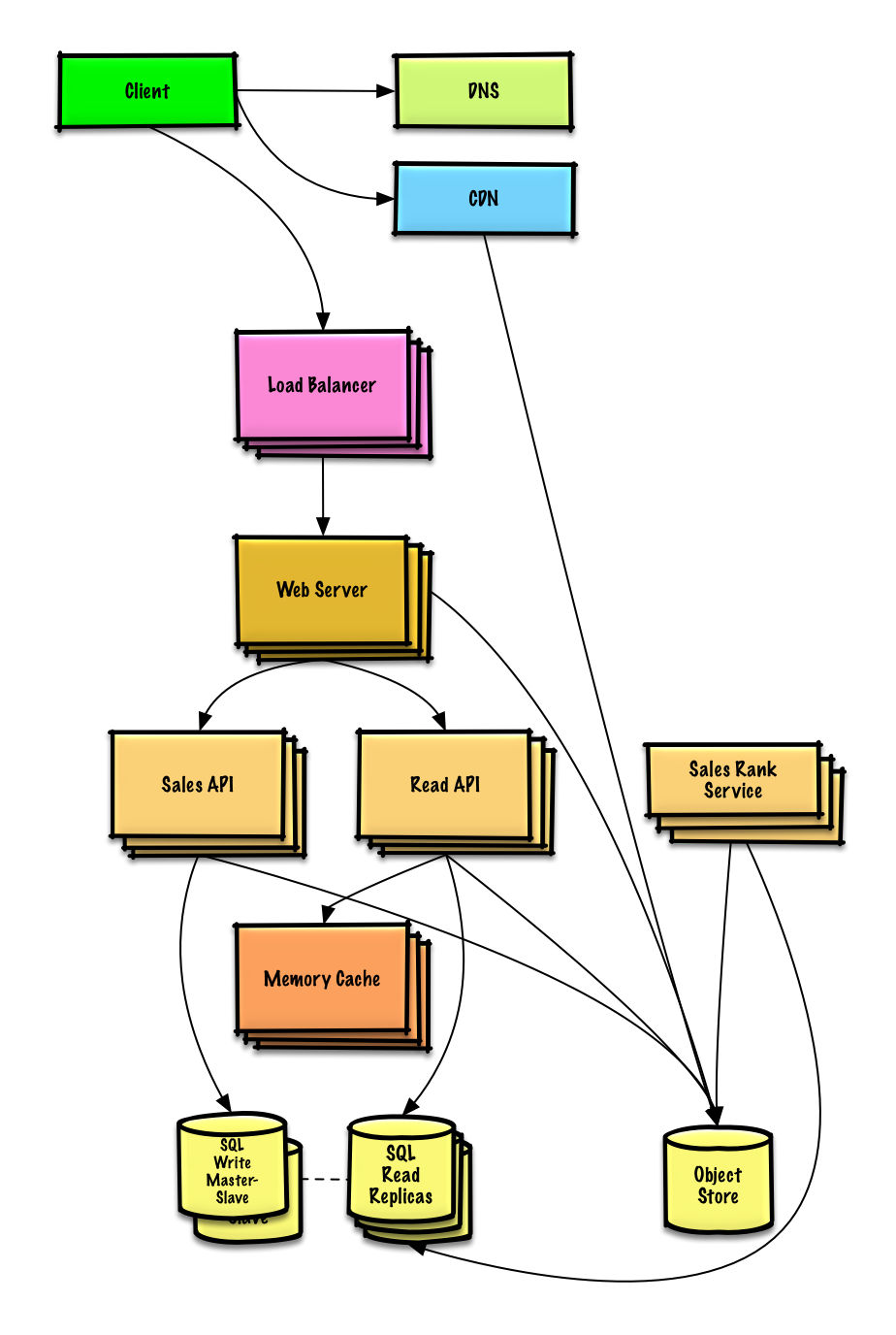
연습 및 솔루션 보기
샘플 토론, 코드 및 다이어그램이 포함된 일반적인 객체 지향 디자인 인터뷰 질문입니다.
solutions/폴더의 콘텐츠에 링크된 솔루션입니다.
참고: 이 섹션은 개발 중입니다.
| 질문 | |
|---|---|
| 해시 맵 디자인 | 해결책 |
| 최근에 가장 적게 사용된 캐시를 설계합니다. | 해결책 |
| 콜센터 디자인 | 해결책 |
| 카드 덱 디자인 | 해결책 |
| 주차장을 디자인하다 | 해결책 |
| 채팅 서버 설계 | 해결책 |
| 원형 배열 디자인 | 기여하다 |
| 객체 지향 설계 질문 추가 | 기여하다 |
시스템 설계가 처음이신가요?
먼저, 공통 원칙에 대한 기본적인 이해가 필요하며, 그것이 무엇인지, 어떻게 사용되는지, 장단점에 대해 학습해야 합니다.
Harvard의 확장성 강의
확장성
다음으로, 높은 수준의 장단점을 살펴보겠습니다.
모든 것은 절충안이라는 점을 명심하세요.
그런 다음 DNS, CDN 및 로드 밸런서와 같은 보다 구체적인 주제를 살펴보겠습니다.
추가된 리소스에 비례하여 성능이 향상되는 경우 서비스는 확장 가능 합니다. 일반적으로 성능이 향상된다는 것은 더 많은 작업 단위를 제공하는 것을 의미하지만, 데이터 세트가 증가하는 경우와 같이 더 큰 작업 단위를 처리하는 것일 수도 있습니다. 1
성능과 확장성을 비교하는 또 다른 방법:
지연 시간 은 어떤 작업을 수행하거나 결과를 생성하는 데 걸리는 시간입니다.
처리량 은 단위 시간당 해당 작업 또는 결과의 수입니다.
일반적으로 허용 가능한 지연 시간 과 최대 처리량을 목표로 해야 합니다.
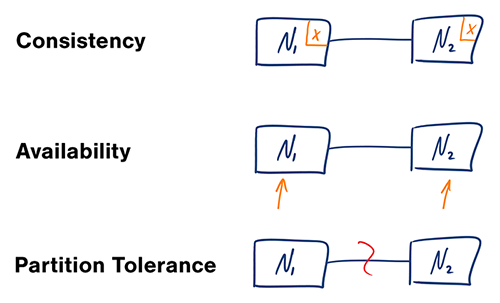
출처: CAP 정리 재검토
분산 컴퓨터 시스템에서는 다음 보장 중 두 가지만 지원할 수 있습니다.
네트워크는 안정적이지 않으므로 파티션 허용 오차를 지원해야 합니다. 일관성과 가용성 사이에서 소프트웨어 균형을 맞춰야 합니다.
분할된 노드의 응답을 기다리면 시간 초과 오류가 발생할 수 있습니다. 비즈니스 요구 사항에 원자성 읽기 및 쓰기가 필요한 경우 CP는 좋은 선택입니다.
응답은 모든 노드에서 사용 가능한 가장 쉽게 사용 가능한 데이터 버전을 반환하지만 최신 버전이 아닐 수도 있습니다. 파티션이 해결되면 쓰기가 전파되는 데 다소 시간이 걸릴 수 있습니다.
AP는 비즈니스에서 최종 일관성을 허용해야 하거나 외부 오류에도 불구하고 시스템이 계속 작동해야 하는 경우 좋은 선택입니다.
동일한 데이터의 여러 복사본이 있는 경우 클라이언트가 데이터에 대한 일관된 보기를 갖도록 이를 동기화하는 방법에 대한 옵션에 직면하게 됩니다. CAP 정리에서 일관성의 정의를 떠올려 보세요. 모든 읽기는 가장 최근의 쓰기 또는 오류를 받습니다.
쓰기 후에 읽기에서는 이를 볼 수도 있고 보지 못할 수도 있습니다. 최선의 노력을 다하는 접근 방식이 취해집니다.
이 접근 방식은 memcached와 같은 시스템에서 볼 수 있습니다. 약한 일관성은 VoIP, 화상 채팅, 실시간 멀티플레이어 게임과 같은 실시간 사용 사례에 적합합니다. 예를 들어, 전화 통화 중 몇 초 동안 수신이 끊긴 경우, 다시 연결되면 연결이 끊어졌을 때 말한 내용을 들을 수 없습니다.
쓰기 후 읽기에서는 결국 이를 보게 됩니다(일반적으로 밀리초 이내). 데이터는 비동기식으로 복제됩니다.
이 접근 방식은 DNS 및 이메일과 같은 시스템에서 볼 수 있습니다. 최종 일관성은 고가용성 시스템에서 잘 작동합니다.
쓰기 후에는 읽기에서 이를 볼 수 있습니다. 데이터는 동기식으로 복제됩니다.
이 접근 방식은 파일 시스템과 RDBMS에서 볼 수 있습니다. 강력한 일관성은 트랜잭션이 필요한 시스템에서 잘 작동합니다.
고가용성을 지원하는 두 가지 보완 패턴, 즉 장애 조치 및 복제가 있습니다.
활성-수동 장애 조치를 사용하면 대기 중인 활성 서버와 수동 서버 간에 하트비트가 전송됩니다. 하트비트가 중단되면 수동 서버가 활성 서버의 IP 주소를 인수하고 서비스를 재개합니다.
가동 중지 시간의 길이는 수동 서버가 이미 '핫' 대기 모드에서 실행 중인지 또는 '콜드' 대기 모드에서 시작해야 하는지 여부에 따라 결정됩니다. 활성 서버만 트래픽을 처리합니다.
활성-수동 장애 조치는 마스터-슬레이브 장애 조치라고도 합니다.
활성-활성에서는 두 서버 모두 트래픽을 관리하고 두 서버 간에 로드를 분산시킵니다.
서버가 공용인 경우 DNS는 두 서버의 공용 IP에 대해 알아야 합니다. 서버가 내부용인 경우 애플리케이션 로직은 두 서버 모두에 대해 알아야 합니다.
활성-활성 장애 조치는 마스터-마스터 장애 조치라고도 합니다.
이 주제는 데이터베이스 섹션에서 자세히 설명합니다.
가용성은 서비스를 사용할 수 있는 시간의 백분율로 표시되는 가동 시간(또는 가동 중지 시간)으로 정량화되는 경우가 많습니다. 가용성은 일반적으로 9의 수로 측정됩니다. 즉, 99.99%의 가용성을 갖는 서비스는 9가 4개 있는 것으로 설명됩니다.
| 지속 | 허용 가능한 가동 중지 시간 |
|---|---|
| 연간 가동 중지 시간 | 8시간 45분 57초 |
| 월별 가동 중지 시간 | 43분 49.7초 |
| 주당 가동 중지 시간 | 10분 4.8초 |
| 일일 가동 중지 시간 | 1분 26.4초 |
| 지속 | 허용 가능한 가동 중지 시간 |
|---|---|
| 연간 가동 중지 시간 | 52분 35.7초 |
| 월별 가동 중지 시간 | 4분 23초 |
| 주당 가동 중지 시간 | 1분 5초 |
| 일일 가동 중지 시간 | 8.6초 |
서비스가 오류가 발생하기 쉬운 여러 구성 요소로 구성된 경우 서비스의 전체 가용성은 구성 요소가 순차적인지 아니면 병렬인지에 따라 달라집니다.
가용성이 100% 미만인 두 구성 요소가 순서대로 있으면 전체 가용성이 감소합니다.
Availability (Total) = Availability (Foo) * Availability (Bar)
Foo 와 Bar 각각 99.9%의 가용성을 갖는다면 순서대로 총 가용성은 99.8%가 됩니다.
가용성이 100% 미만인 두 구성 요소가 병렬인 경우 전체 가용성이 증가합니다.
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
Foo 와 Bar 각각 99.9%의 가용성을 갖는다면 병렬의 총 가용성은 99.9999%가 됩니다.
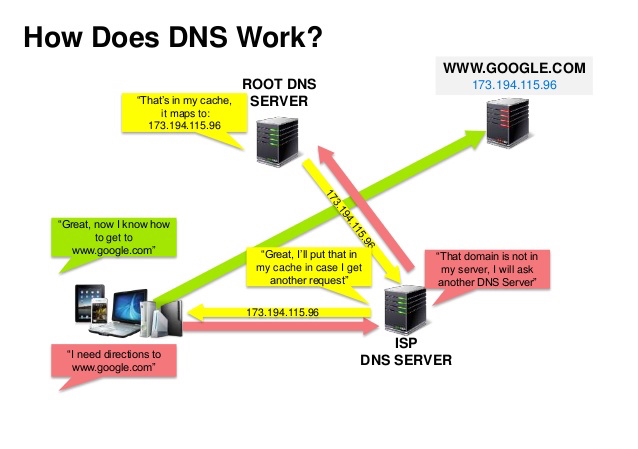
출처: DNS 보안 프레젠테이션
DNS(Domain Name System)는 www.example.com과 같은 도메인 이름을 IP 주소로 변환합니다.
DNS는 계층적이며 최상위 수준에 몇 개의 권한 있는 서버가 있습니다. 라우터나 ISP는 조회 시 연결할 DNS 서버에 대한 정보를 제공합니다. 낮은 수준의 DNS 서버 캐시 매핑은 DNS 전파 지연으로 인해 오래될 수 있습니다. DNS 결과는 TTL(Time To Live)에 따라 결정된 일정 기간 동안 브라우저나 OS에 의해 캐시될 수도 있습니다.
CNAME (example.com에서 www.example.com으로) 또는 A 레코드를 가리킵니다.CloudFlare 및 Route 53과 같은 서비스는 관리형 DNS 서비스를 제공합니다. 일부 DNS 서비스는 다양한 방법을 통해 트래픽을 라우팅할 수 있습니다.
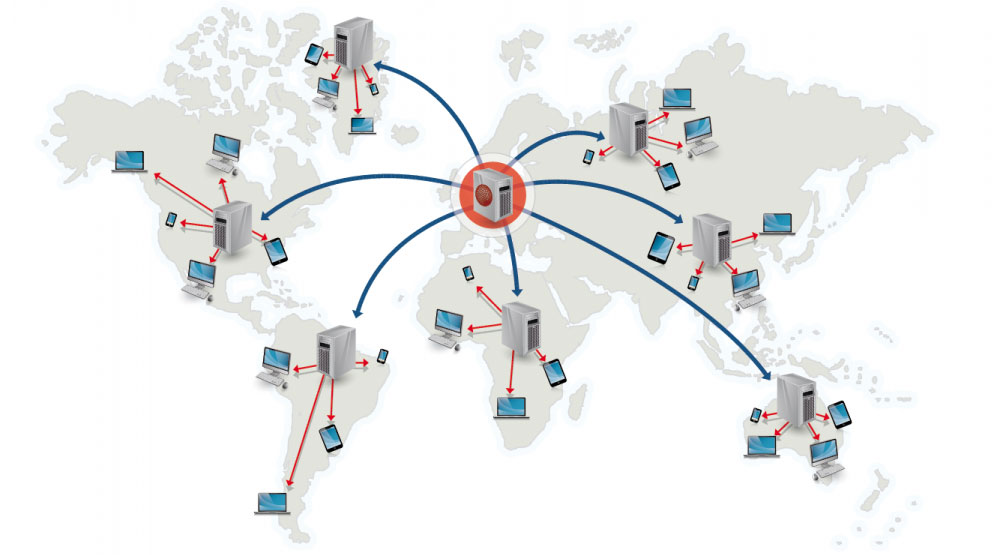
출처: CDN을 사용하는 이유
CDN(콘텐츠 전송 네트워크)은 전 세계적으로 분산된 프록시 서버 네트워크로, 사용자에게 더 가까운 위치에서 콘텐츠를 제공합니다. 일반적으로 HTML/CSS/JS, 사진, 비디오와 같은 정적 파일은 CDN에서 제공되지만 Amazon CloudFront와 같은 일부 CDN은 동적 콘텐츠를 지원합니다. 사이트의 DNS 확인은 클라이언트에게 접속할 서버를 알려줍니다.
CDN에서 콘텐츠를 제공하면 다음 두 가지 방법으로 성능을 크게 향상시킬 수 있습니다.
푸시 CDN은 서버에 변경 사항이 발생할 때마다 새로운 콘텐츠를 받습니다. 콘텐츠 제공, CDN에 직접 업로드, CDN을 가리키도록 URL 다시 작성에 대한 전적인 책임은 귀하에게 있습니다. 콘텐츠가 만료되는 시기와 업데이트되는 시기를 구성할 수 있습니다. 콘텐츠는 새롭거나 변경된 경우에만 업로드되므로 트래픽은 최소화하면서 저장 공간은 최대화됩니다.
트래픽이 적은 사이트나 콘텐츠가 자주 업데이트되지 않는 사이트는 푸시 CDN과 잘 작동합니다. 콘텐츠는 정기적으로 다시 가져오는 대신 CDN에 한 번만 배치됩니다.
풀 CDN은 첫 번째 사용자가 콘텐츠를 요청할 때 서버에서 새 콘텐츠를 가져옵니다. 서버에 콘텐츠를 남겨두고 CDN을 가리키도록 URL을 다시 작성합니다. 이로 인해 콘텐츠가 CDN에 캐시될 때까지 요청 속도가 느려집니다.
TTL(Time-To-Live)은 콘텐츠가 캐시되는 기간을 결정합니다. 풀 CDN은 CDN의 저장 공간을 최소화하지만 파일이 만료되어 실제로 변경되기 전에 풀링되면 중복 트래픽이 발생할 수 있습니다.
트래픽이 많은 사이트는 풀 CDN과 잘 작동합니다. 최근에 요청한 콘텐츠만 CDN에 남아 트래픽이 더욱 균등하게 분산되기 때문입니다.
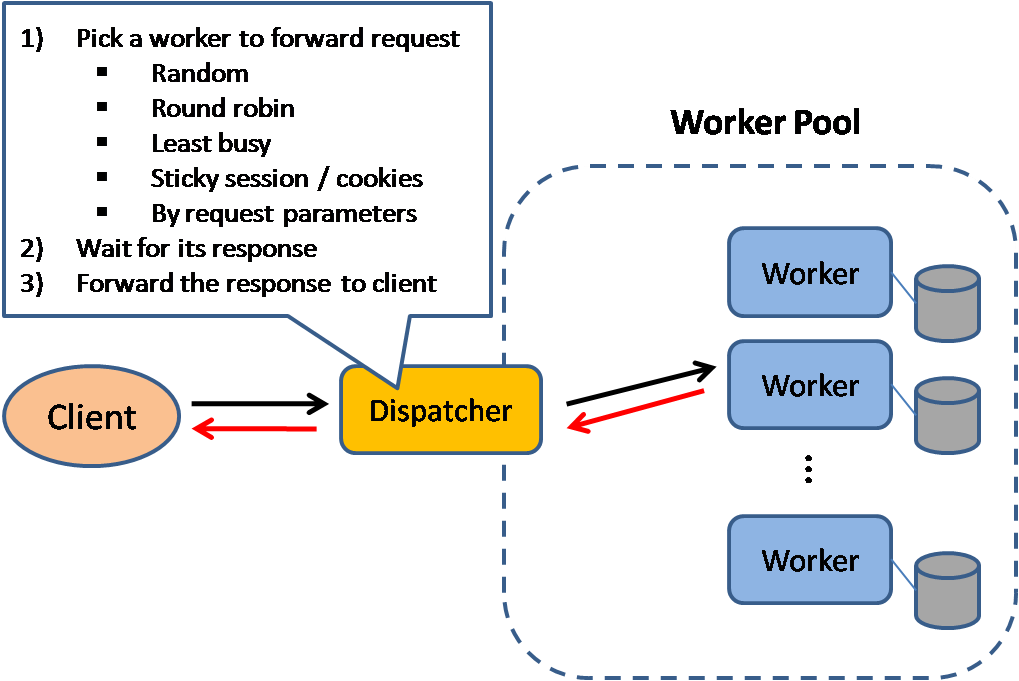
출처: 확장 가능한 시스템 설계 패턴
로드 밸런서는 들어오는 클라이언트 요청을 애플리케이션 서버 및 데이터베이스와 같은 컴퓨팅 리소스에 분산시킵니다. 각 경우에 로드 밸런서는 컴퓨팅 리소스의 응답을 적절한 클라이언트로 반환합니다. 로드 밸런서는 다음과 같은 경우에 효과적입니다.
로드 밸런서는 하드웨어(비싼) 또는 HAProxy와 같은 소프트웨어를 사용하여 구현할 수 있습니다.
추가 혜택은 다음과 같습니다.
오류로부터 보호하기 위해 활성-수동 또는 활성-활성 모드로 여러 로드 밸런서를 설정하는 것이 일반적입니다.
로드 밸런서는 다음을 포함한 다양한 지표를 기반으로 트래픽을 라우팅할 수 있습니다.
레이어 4 로드 밸런서는 전송 레이어의 정보를 확인하여 요청 배포 방법을 결정합니다. 일반적으로 여기에는 헤더의 소스, 대상 IP 주소 및 포트가 포함되지만 패킷의 내용은 포함되지 않습니다. 레이어 4 로드 밸런서는 NAT(네트워크 주소 변환)를 수행하여 업스트림 서버와 네트워크 패킷을 전달합니다.
레이어 7 로드 밸런서는 애플리케이션 레이어를 살펴보고 요청을 분산하는 방법을 결정합니다. 여기에는 헤더, 메시지 및 쿠키의 내용이 포함될 수 있습니다. 레이어 7 로드 밸런서는 네트워크 트래픽을 종료하고, 메시지를 읽고, 로드 밸런싱 결정을 내린 다음, 선택한 서버에 대한 연결을 엽니다. 예를 들어, 계층 7 로드 밸런서는 비디오 트래픽을 비디오를 호스팅하는 서버로 보내는 동시에 보다 민감한 사용자 청구 트래픽을 보안이 강화된 서버로 보낼 수 있습니다.
유연성을 희생시키면서 레이어 4 로드 밸런싱은 레이어 7보다 더 적은 시간과 컴퓨팅 리소스를 필요로 하지만 최신 상용 하드웨어에서는 성능에 미치는 영향이 최소화될 수 있습니다.
로드 밸런서는 수평 확장에도 도움이 되어 성능과 가용성을 향상시킬 수 있습니다. 상용 시스템을 사용하여 확장하는 것은 수직 확장 이라고 하는 더 비싼 하드웨어에서 단일 서버를 확장하는 것보다 비용 효율적이며 가용성이 더 높습니다. 또한 전문화된 엔터프라이즈 시스템보다 상용 하드웨어에서 일하는 인재를 고용하는 것이 더 쉽습니다.
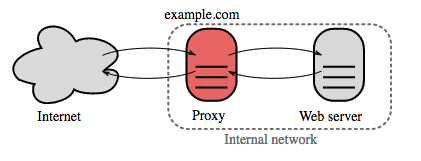
출처: 위키피디아
역방향 프록시는 내부 서비스를 중앙 집중화하고 대중에게 통합 인터페이스를 제공하는 웹 서버입니다. 클라이언트의 요청은 역방향 프록시가 서버의 응답을 클라이언트에 반환하기 전에 이를 수행할 수 있는 서버로 전달됩니다.
추가 혜택은 다음과 같습니다.
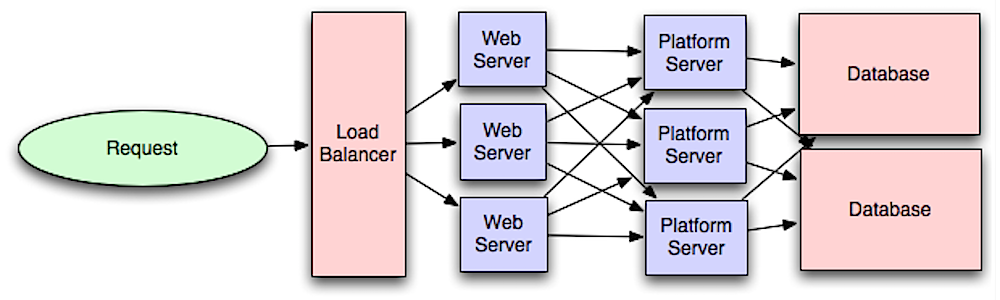
출처: 규모에 맞는 시스템 설계 소개
애플리케이션 계층(플랫폼 계층이라고도 함)에서 웹 계층을 분리하면 두 계층을 독립적으로 확장하고 구성할 수 있습니다. 새 API를 추가하면 웹 서버를 추가할 필요 없이 애플리케이션 서버가 추가됩니다. 단일 책임 원칙은 함께 작동하는 소규모의 자율적인 서비스를 옹호합니다. 소규모 서비스를 갖춘 소규모 팀은 빠른 성장을 위해 보다 공격적으로 계획을 세울 수 있습니다.
애플리케이션 계층의 작업자도 비동기성을 활성화하는 데 도움이 됩니다.
이 논의와 관련된 마이크로서비스는 독립적으로 배포 가능한 소규모 모듈식 서비스 제품군으로 설명할 수 있습니다. 각 서비스는 고유한 프로세스를 실행하고 잘 정의된 경량 메커니즘을 통해 통신하여 비즈니스 목표를 달성합니다. 1
예를 들어 Pinterest에는 사용자 프로필, 팔로어, 피드, 검색, 사진 업로드 등의 마이크로서비스가 있을 수 있습니다.
Consul, Etcd 및 Zookeeper와 같은 시스템은 등록된 이름, 주소 및 포트를 추적하여 서비스가 서로를 찾는 데 도움을 줄 수 있습니다. 상태 확인은 서비스 무결성을 확인하는 데 도움이 되며 종종 HTTP 엔드포인트를 사용하여 수행됩니다. Consul과 Etcd에는 구성 값과 기타 공유 데이터를 저장하는 데 유용할 수 있는 키-값 저장소가 내장되어 있습니다.
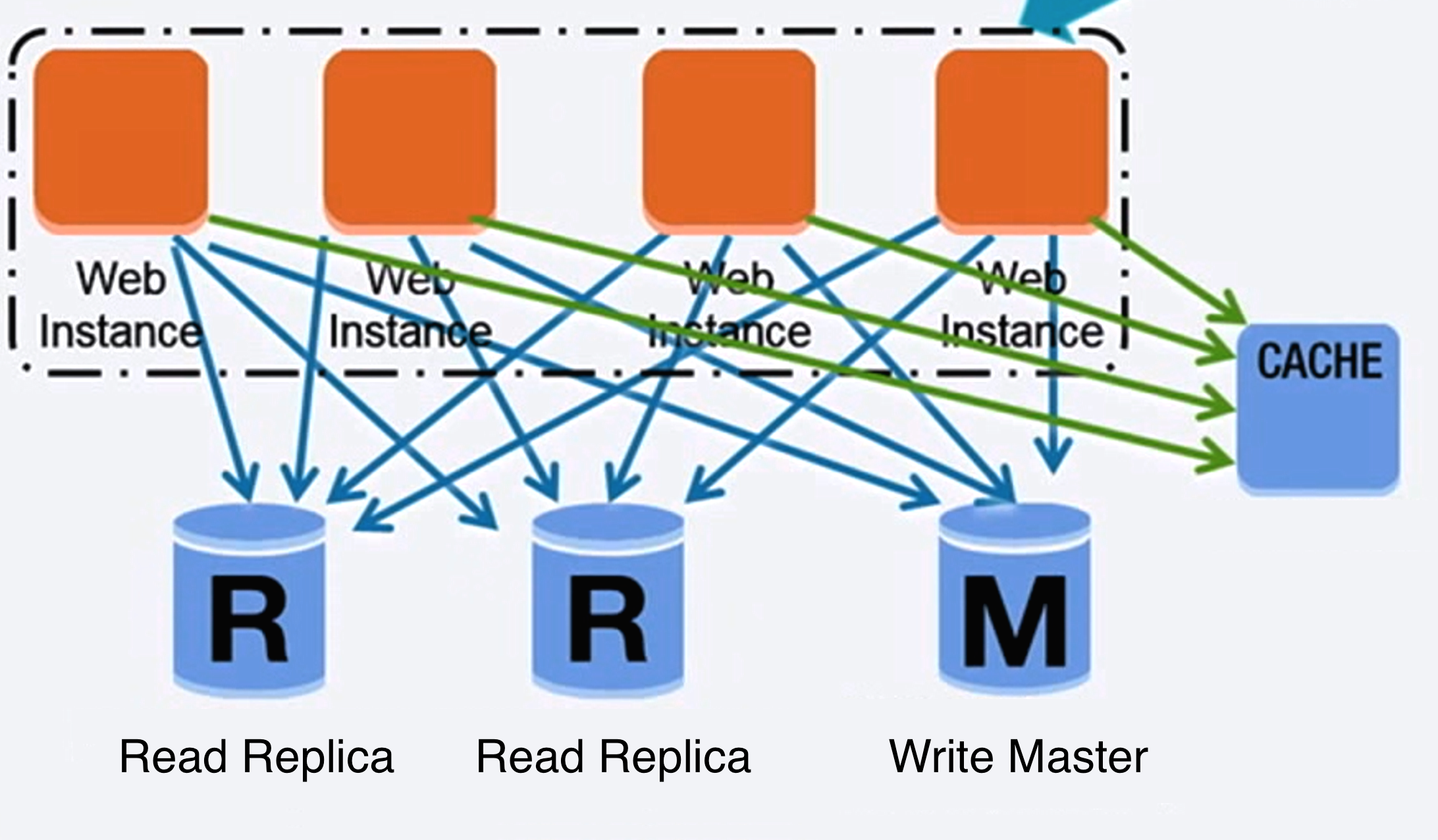
출처: 처음 1,000만 명의 사용자까지 확장
SQL과 같은 관계형 데이터베이스는 테이블로 구성된 데이터 항목의 모음입니다.
ACID는 관계형 데이터베이스 트랜잭션의 속성 집합입니다.
관계형 데이터베이스를 확장하는 데는 마스터-슬레이브 복제 , 마스터-마스터 복제 , 페더레이션 , 샤딩 , 비정규화 , SQL 튜닝 등 다양한 기술이 있습니다.
마스터는 읽기 및 쓰기를 제공하며, 읽기만 제공하는 하나 이상의 슬레이브에 쓰기를 복제합니다. 슬레이브는 트리와 같은 방식으로 추가 슬레이브에 복제할 수도 있습니다. 마스터가 오프라인이 되면 슬레이브가 마스터로 승격되거나 새 마스터가 프로비저닝될 때까지 시스템은 읽기 전용 모드로 계속 작동할 수 있습니다.
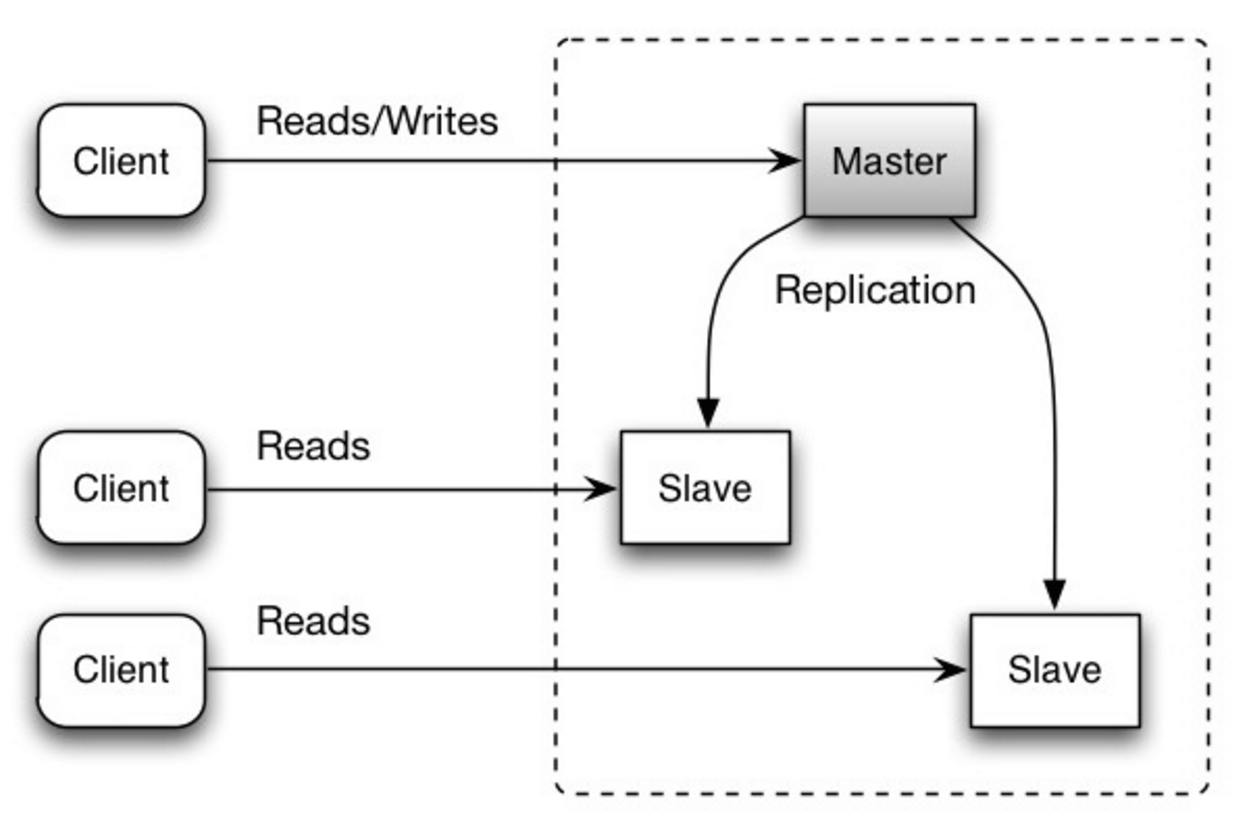
출처: 확장성, 가용성, 안정성, 패턴
두 마스터 모두 읽기 및 쓰기를 제공하고 쓰기 시 서로 조정합니다. 두 마스터 중 하나가 다운되더라도 시스템은 읽기 및 쓰기 작업을 계속해서 수행할 수 있습니다.
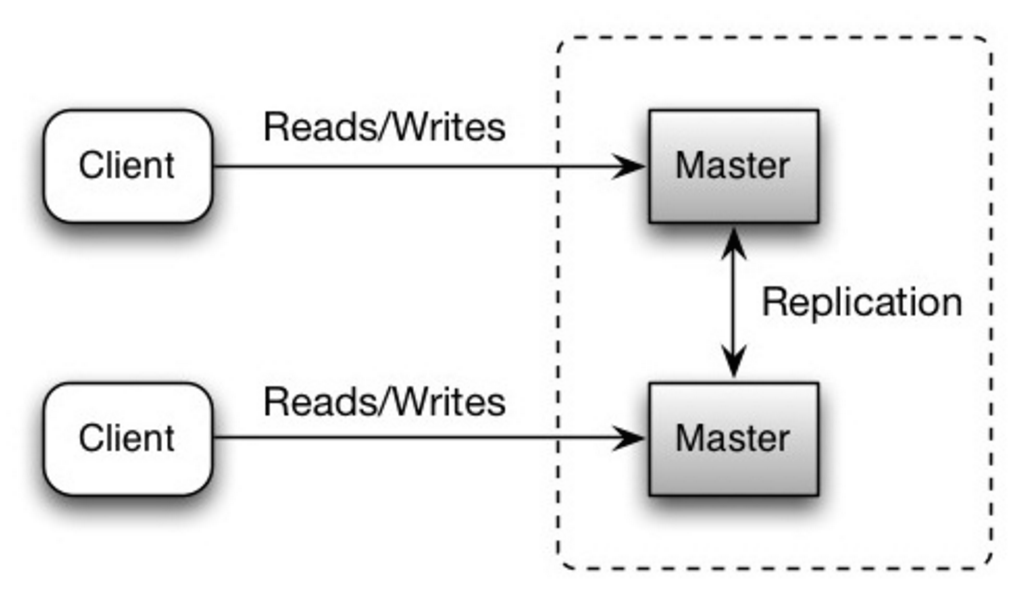
출처: 확장성, 가용성, 안정성, 패턴
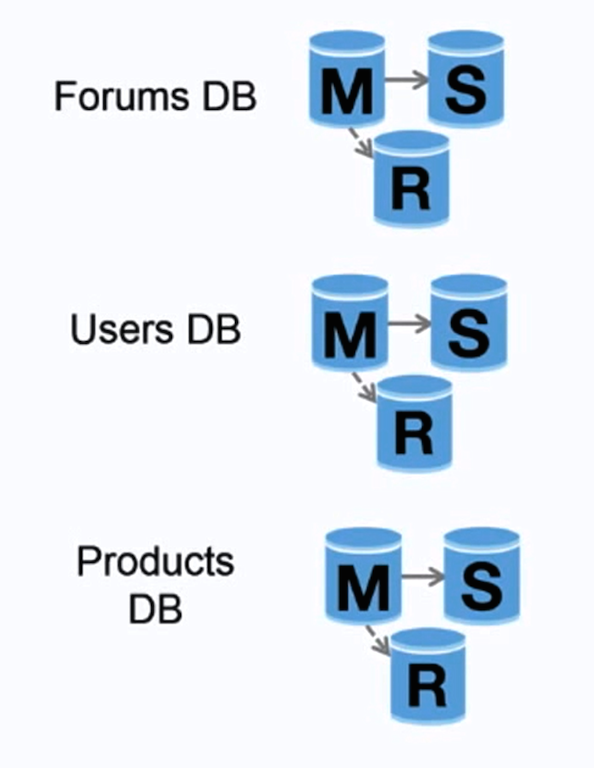
출처: 처음 1,000만 명의 사용자까지 확장
연합(또는 기능 분할)은 기능별로 데이터베이스를 분할합니다. 예를 들어 단일 모놀리식 데이터베이스 대신 forums , users 및 products 의 세 가지 데이터베이스를 보유할 수 있으므로 각 데이터베이스에 대한 읽기 및 쓰기 트래픽이 줄어들어 복제 지연이 줄어듭니다. 데이터베이스가 작을수록 메모리에 들어갈 수 있는 데이터가 더 많아지고, 결과적으로 캐시 지역성이 향상되어 더 많은 캐시 적중률이 발생합니다. 단일 중앙 마스터 직렬화 쓰기가 없으므로 병렬로 쓸 수 있어 처리량이 늘어납니다.
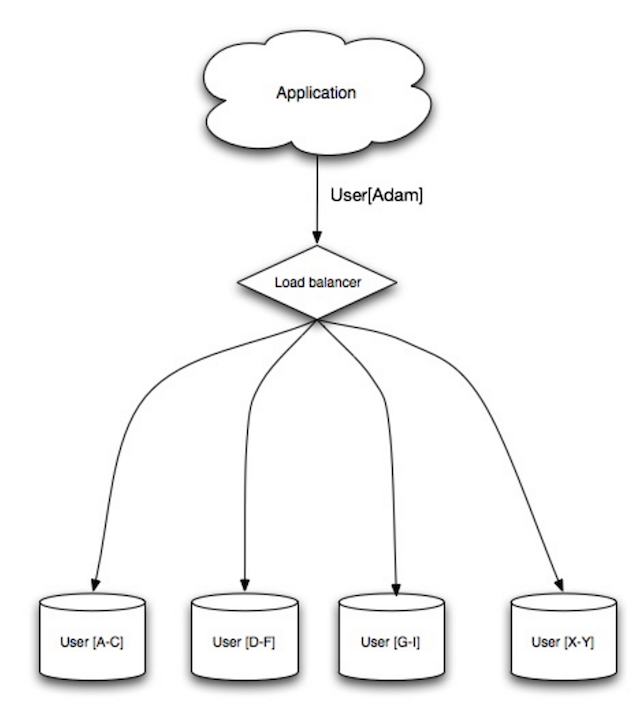
출처: 확장성, 가용성, 안정성, 패턴
샤딩은 각 데이터베이스가 데이터의 하위 집합만 관리할 수 있도록 여러 데이터베이스에 데이터를 분산합니다. 사용자 데이터베이스를 예로 들면, 사용자 수가 증가할수록 더 많은 샤드가 클러스터에 추가됩니다.
페더레이션의 장점과 유사하게 샤딩을 사용하면 읽기 및 쓰기 트래픽이 줄어들고 복제가 줄어들며 캐시 적중률이 높아집니다. 인덱스 크기도 줄어들어 일반적으로 더 빠른 쿼리로 성능이 향상됩니다. 샤드 하나가 다운되더라도 다른 샤드는 계속 작동하지만 데이터 손실을 방지하기 위해 복제 형태를 추가하는 것이 좋습니다. 페더레이션과 마찬가지로 쓰기를 직렬화하는 단일 중앙 마스터가 없으므로 처리량을 늘리면서 병렬로 쓸 수 있습니다.
사용자 테이블을 샤딩하는 일반적인 방법은 사용자의 성 이니셜이나 사용자의 지리적 위치를 사용하는 것입니다.
비정규화는 일부 쓰기 성능을 희생하면서 읽기 성능을 향상시키려고 시도합니다. 비용이 많이 드는 조인을 방지하기 위해 데이터의 중복 복사본이 여러 테이블에 기록됩니다. PostgreSQL 및 Oracle과 같은 일부 RDBMS는 중복 정보를 저장하고 중복 복사본의 일관성을 유지하는 작업을 처리하는 구체화된 뷰를 지원합니다.
일단 데이터가 연합 및 샤드와 같은 기술로 분산되면 데이터 센터 전체의 조인 관리는 복잡성을 더욱 증가시킵니다. 비정상화는 그러한 복잡한 결합의 필요성을 우회 할 수있다.
대부분의 시스템에서 읽기는 100 : 1 또는 심지어 1000 : 1을 쓸 수 있습니다. 복잡한 데이터베이스 조인을 초래하는 읽기는 매우 비쌀 수 있으며 디스크 작업에 상당한 시간을 소비합니다.
SQL 튜닝은 광범위한 주제이며 많은 책이 참조로 작성되었습니다.
병목 현상을 시뮬레이션하고 발견하기 위해 벤치 마크 및 프로필 이 중요합니다.
벤치마킹 및 프로파일 링은 다음과 같은 최적화를 지적 할 수 있습니다.
VARCHAR 대신 CHAR 사용하십시오.CHAR 빠르고 무작위로 액세스 할 수있는 반면, VARCHAR 의 경우 다음 끈으로 이동하기 전에 문자열의 끝을 찾아야합니다.TEXT 사용하십시오. TEXT 또한 부울 검색을 허용합니다. TEXT 필드를 사용하면 텍스트 블록을 찾는 데 사용되는 디스크에 포인터를 저장합니다.INT 사용하십시오.DECIMAL 소수점 표현 오류를 피하려면 화폐를 사용하십시오.BLOBS 저장하지 말고 대신 물체를 얻을 수있는 위치를 보관하십시오.VARCHAR(255) 는 8 비트 숫자로 계산할 수있는 가장 많은 수의 문자이며, 종종 일부 RDBMS에서 바이트의 사용을 최대화합니다.NOT NULL 제약 조건을 설정하십시오. SELECT , GROUP BY , ORDER BY , JOIN )은 인덱스에서 더 빠를 수 있습니다.NOSQL은 키 값 저장소 , 문서 저장소 , 넓은 열 저장소 또는 그래프 데이터베이스 에 표시되는 데이터 항목 모음입니다. 데이터는 정상화되며 결합은 일반적으로 응용 프로그램 코드에서 수행됩니다. 대부분의 NOSQL 상점에는 진정한 산 거래가 부족하고 최종 일관성을 선호합니다.
베이스는 종종 NOSQL 데이터베이스의 속성을 설명하는 데 사용됩니다. CAP 정리와 비교하여 Base는 일관성보다 가용성을 선택합니다.
SQL 또는 NOSQL 중에서 선택하는 것 외에도 사용 사례에 가장 적합한 NOSQL 데이터베이스 유형을 이해하는 것이 도움이됩니다. 다음 섹션에서 주요 값 상점 , 문서 상점 , 와이드 칼럼 상점 및 그래프 데이터베이스를 검토합니다.
추상화 : 해시 테이블
키 가치 저장소는 일반적으로 O (1) 읽기 및 쓰기를 허용하며 종종 메모리 또는 SSD로 뒷받침됩니다. 데이터 저장소는 키를 사전 순서로 유지하여 키 범위를 효율적으로 검색 할 수 있습니다. 키 가치 저장소는 메타 데이터를 값으로 저장할 수 있습니다.
키-값 스토어는 고성능을 제공하며 종종 간단한 데이터 모델 또는 메모리 인 캐시 계층과 같은 빠르게 변화하는 데이터에 사용됩니다. 제한된 작업 세트 만 제공하므로 추가 작업이 필요한 경우 복잡성이 응용 프로그램 계층으로 이동됩니다.
키 가치 저장소는 문서 저장소와 같은보다 복잡한 시스템의 기초 및 경우에 따라 그래프 데이터베이스입니다.
추상화 : 값으로 저장된 문서가있는 키 가치 저장소
문서 저장소는 문서 (XML, JSON, 이진 등)를 중심으로하며 문서는 주어진 개체에 대한 모든 정보를 저장합니다. 문서 저장소는 문서 자체의 내부 구조를 기반으로 API 또는 쿼리 언어를 쿼리 할 수 있습니다. 많은 주요 값 스토어에는 값 메타 데이터로 작업하는 기능이 포함되어 있으며이 두 스토리지 유형 사이의 선을 흐리게합니다.
기본 구현을 기반으로 문서는 컬렉션, 태그, 메타 데이터 또는 디렉토리로 구성됩니다. 문서를 함께 구성하거나 그룹화 할 수 있지만 문서에는 서로 완전히 다른 필드가있을 수 있습니다.
MongoDB 및 CouchDB와 같은 일부 문서 저장소는 복잡한 쿼리를 수행하기위한 SQL 유사 언어를 제공합니다. DynamoDB는 주요 값과 문서를 모두 지원합니다.
문서 저장소는 유연성이 높은 유연성을 제공하며 종종 때때로 변화하는 데이터로 작업하는 데 사용됩니다.
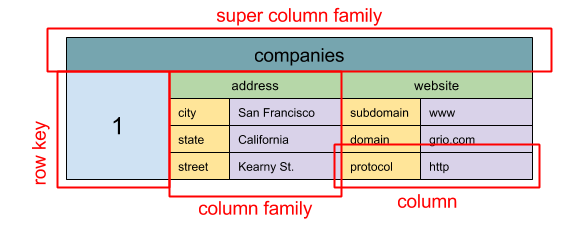
출처 : SQL & NOSQL, 간단한 역사
추상화 : 중첩 맵
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
넓은 열 저장소의 기본 데이터 단위는 열 (이름/값 쌍)입니다. 열은 컬럼 패밀리로 그룹화 될 수 있습니다 (SQL 테이블과 유사). 슈퍼 칼럼 가족 추가 그룹 칼럼 패밀리. 행 키로 독립적으로 각 열과 동일한 행 키 형식의 열이있는 열에 독립적으로 액세스 할 수 있습니다. 각 값에는 버전 및 충돌 해결을위한 타임 스탬프가 포함됩니다.
Google은 Bigtable을 최초의 Wide Column Store로 소개했으며, 이는 Hadoop 생태계에서 종종 사용되는 오픈 소스 HBase와 Facebook의 Cassandra에 영향을 미쳤습니다. BigTable, HBase 및 Cassandra와 같은 상점은 사전 순서대로 키를 유지하여 선택적 키 범위를 효율적으로 검색 할 수 있습니다.
와이드 컬럼 상점은 고 가용성과 높은 확장 성을 제공합니다. 그들은 종종 매우 큰 데이터 세트에 사용됩니다.
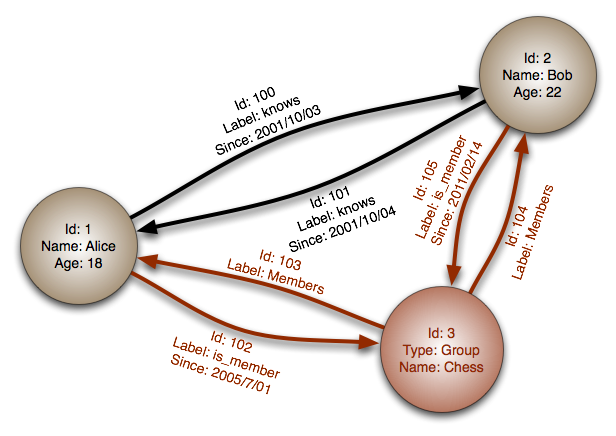
출처 : 그래프 데이터베이스
추상화 : 그래프
그래프 데이터베이스에서 각 노드는 레코드이며 각 아크는 두 노드 간의 관계입니다. 그래프 데이터베이스는 많은 외국 키 또는 다수의 관계와의 복잡한 관계를 나타내도록 최적화되었습니다.
그래프 데이터베이스는 소셜 네트워크와 같은 복잡한 관계를 가진 데이터 모델에 대한 고성능을 제공합니다. 그것들은 비교적 새롭고 아직 널리 사용되지 않았습니다. 개발 도구와 리소스를 찾는 것이 더 어려울 수 있습니다. 많은 그래프는 REST API로만 액세스 할 수 있습니다.
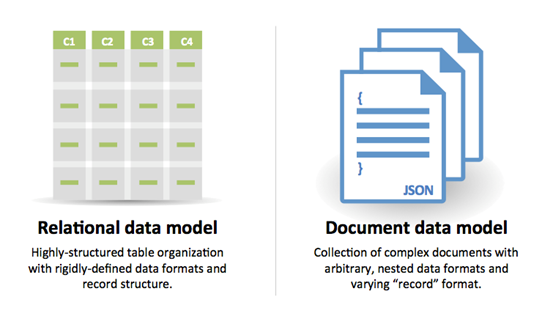
출처 : RDBMS에서 NOSQL 로의 전환
SQL 의 이유 :
NOSQL 의 이유 :
NOSQL에 적합한 샘플 데이터 :
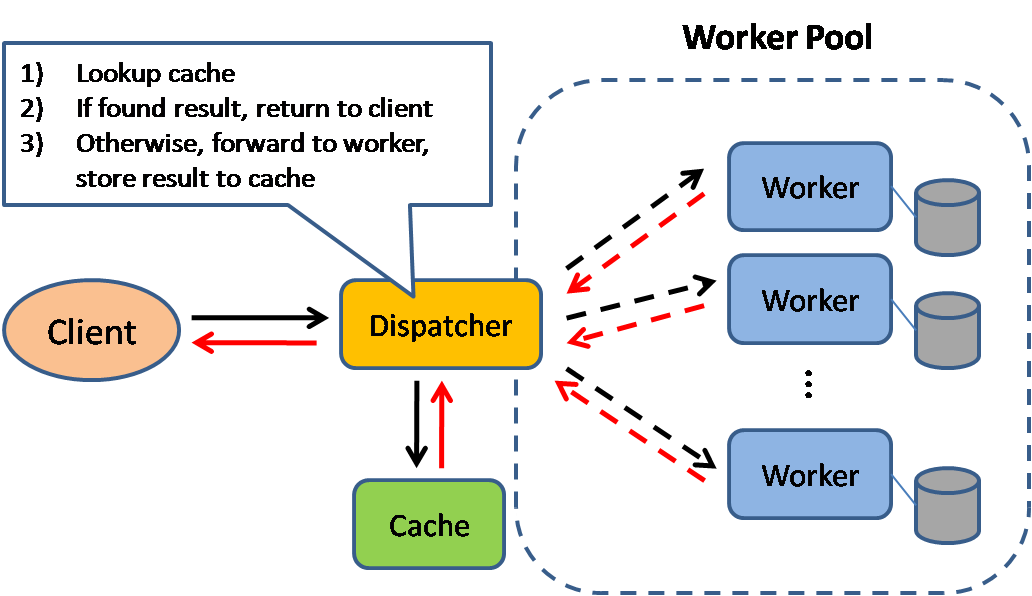
출처 : 확장 가능한 시스템 설계 패턴
캐싱은 페이지로드 시간을 향상시키고 서버 및 데이터베이스의로드를 줄일 수 있습니다. 이 모델에서는 요청이 이전에 작성된 경우 먼저 조회하고 실제 실행을 저장하기 위해 이전 결과를 찾으려고 시도합니다.
데이터베이스는 종종 파티션에 걸쳐 읽기와 쓰기의 균일 한 분포로부터 혜택을받습니다. 인기있는 품목은 분포를 왜곡하여 병목 현상을 유발할 수 있습니다. 데이터베이스 앞에 캐시를 배치하면 트래픽이 고르지 않은 하중과 스파이크를 흡수하는 데 도움이됩니다.
캐시는 클라이언트 쪽 (OS 또는 브라우저), 서버 측 또는 별개의 캐시 레이어에 위치 할 수 있습니다.
CDN은 캐시 유형으로 간주됩니다.
바니시와 같은 리버스 프록시 및 캐시는 정적 및 동적 컨텐츠를 직접 제공 할 수 있습니다. 웹 서버는 애플리케이션 서버에 연락하지 않고도 요청을 캐시하고 응답을 반환 할 수도 있습니다.
데이터베이스에는 일반적으로 기본 구성으로 일정 수준의 캐싱이 포함되어 있으며 일반 사용 사례에 최적화됩니다. 특정 사용 패턴에 대해 이러한 설정을 조정하면 성능이 향상 될 수 있습니다.
Memcached 및 Redis와 같은 메모리 캐시는 응용 프로그램과 데이터 스토리지 사이의 주요 가치 저장소입니다. 데이터는 RAM으로 유지되므로 데이터가 디스크에 저장되는 일반적인 데이터베이스보다 훨씬 빠릅니다. RAM은 디스크보다 더 제한되어 있으므로 LRU (최근에 사용되지 않은)와 같은 캐시 무효화 알고리즘은 '콜드'항목을 무효화하고 '핫'데이터를 RAM으로 유지하는 데 도움이 될 수 있습니다.
Redis에는 다음과 같은 추가 기능이 있습니다.
데이터베이스 쿼리 및 객체의 두 가지 일반 범주로 분류 할 수있는 여러 레벨이 있습니다.
일반적으로 복제 및 자동 스케일링을 더욱 어렵게 만들기 때문에 파일 기반 캐싱을 피해야합니다.
데이터베이스를 쿼리 할 때마다 쿼리를 키로 해시하고 결과를 캐시에 저장하십시오. 이 접근법은 만료 문제가 있습니다.
응용 프로그램 코드에서 수행하는 것과 유사한 데이터를 객체로 확인하십시오. 응용 프로그램이 데이터베이스에서 클래스 인스턴스 또는 데이터 구조로 데이터 세트를 조립하도록하십시오.
캐시의 제안 :
제한된 양의 데이터 만 캐시에 저장할 수 있으므로 사용 사례에 가장 적합한 캐시 업데이트 전략을 결정해야합니다.
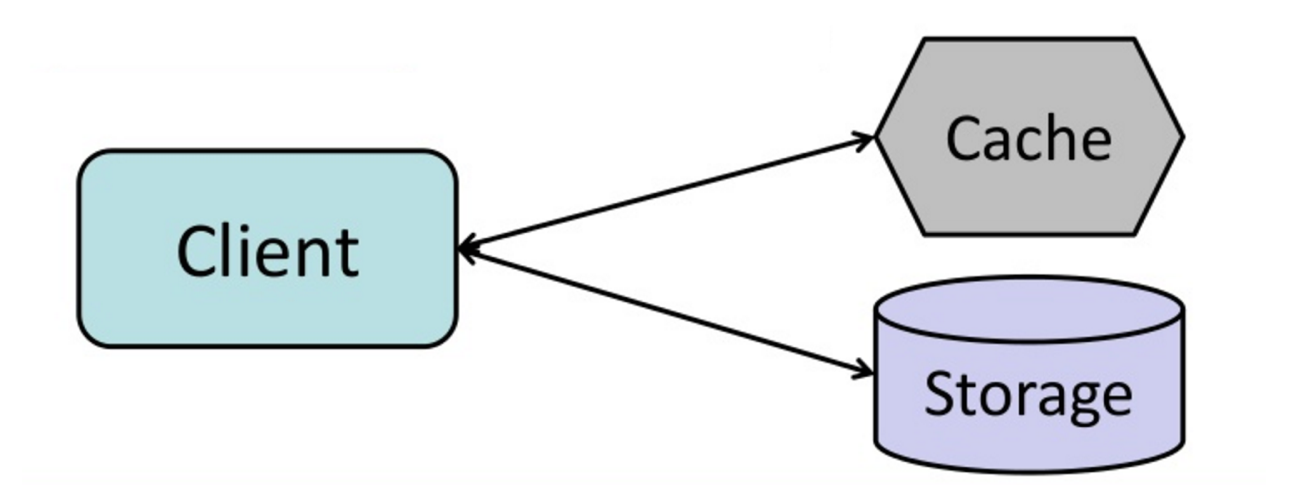
출처 : 캐시에서 메모리 내 데이터 그리드까지
이 응용 프로그램은 스토리지에서 읽고 쓰고 쓰는 책임이 있습니다. 캐시는 스토리지와 직접 상호 작용하지 않습니다. 응용 프로그램은 다음을 수행합니다.
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return usermemcached는 일반적으로 이러한 방식으로 사용됩니다.
캐시에 추가 된 데이터의 후속 읽기는 빠릅니다. 캐시-아라이드는 게으른 하중이라고도합니다. 요청되지 않은 데이터 만 캐시되어 요청되지 않은 데이터로 캐시를 채우지 않도록합니다.
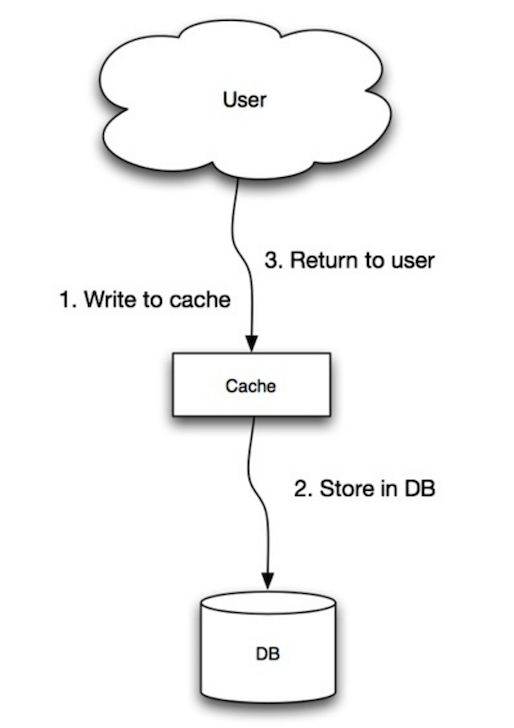
출처 : 확장 성, 가용성, 안정성, 패턴
응용 프로그램은 캐시를 기본 데이터 저장소로 사용하고 데이터를 읽고 쓰는 반면 캐시는 데이터베이스를 읽고 쓰는 일을 담당합니다.
응용 프로그램 코드 :
set_user ( 12345 , { "foo" : "bar" })캐시 코드 :
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )쓰기 스루는 쓰기 작업으로 인해 전반적인 작업이 느리지 만 서면 데이터에 대한 후속 읽기는 빠릅니다. 사용자는 데이터를 읽는 것보다 데이터를 업데이트 할 때 일반적으로 대기 시간에 더 견딜 수 있습니다. 캐시의 데이터는 오래되지 않습니다.
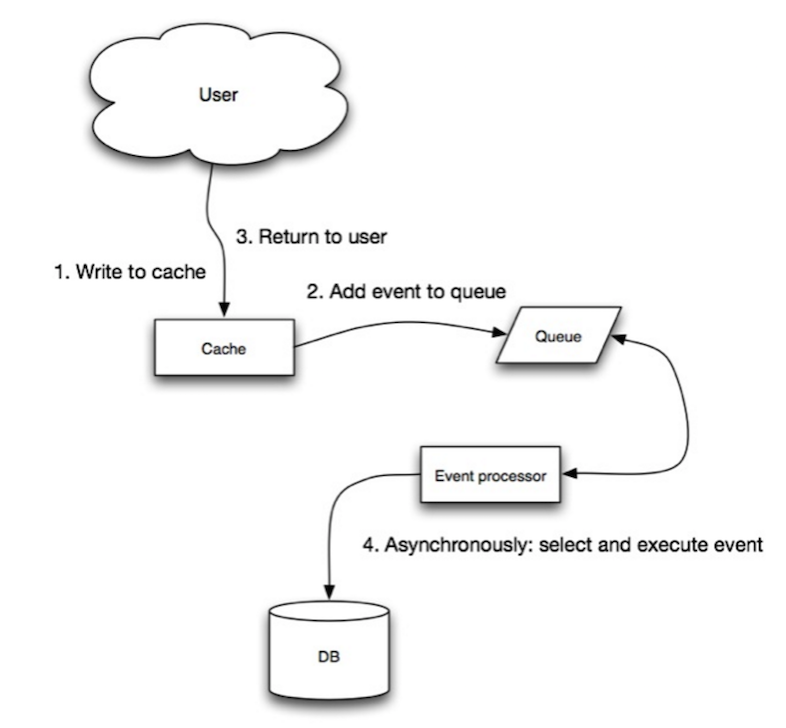
출처 : 확장 성, 가용성, 안정성, 패턴
Write-Behind에서 응용 프로그램은 다음을 수행합니다.
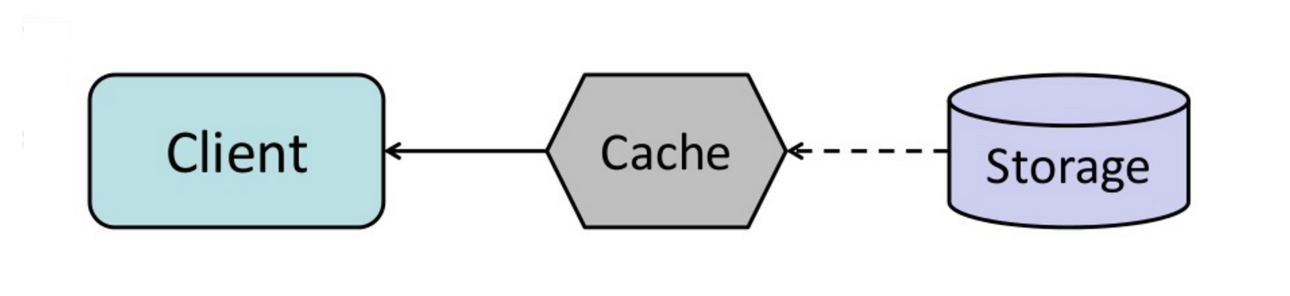
출처 : 캐시에서 메모리 내 데이터 그리드까지
만료 전에 최근에 액세스 한 캐시 항목을 자동으로 새로 고치도록 캐시를 구성 할 수 있습니다.
새로 고침을 사용하면 캐시가 향후 필요한 항목을 정확하게 예측할 수 있다면 대기 시간이 감소 할 수 있습니다.
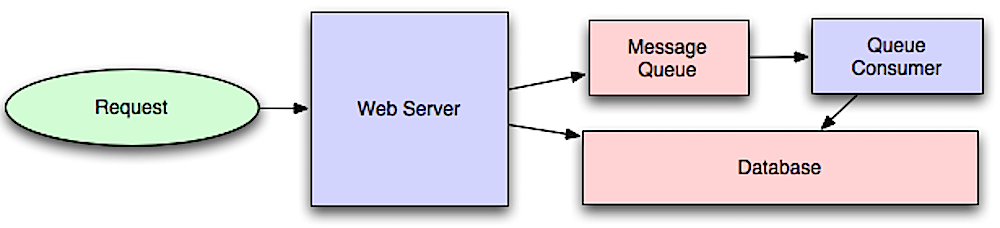
출처 : 스케일을위한 아키텍처 시스템에 대한 소개
비동기 워크 플로우는 인라인으로 수행되는 고가의 작업에 대한 요청 시간을 줄이는 데 도움이됩니다. 또한주기적인 데이터 집계와 같은 시간에 소비하는 작업을 미리 수행함으로써 도움을 줄 수 있습니다.
메시지 대기열은 메시지를 수신, 잡고 전달합니다. 연산이 인라인을 수행하기에는 너무 느리면 다음 워크 플로우와 함께 메시지 큐를 사용할 수 있습니다.
사용자가 차단되지 않고 작업이 백그라운드에서 처리됩니다. 이 기간 동안 클라이언트는 선택적으로 작업이 완료된 것처럼 보이도록 소량의 처리를 수행 할 수 있습니다. 예를 들어, 트윗을 게시하면 트윗을 즉시 타임 라인에 게시 할 수 있지만 트윗이 실제로 모든 팔로워에게 전달되기까지 시간이 걸릴 수 있습니다.
Redis는 간단한 메시지 중개인으로 유용하지만 메시지를 잃을 수 있습니다.
RabbitMQ 는 인기가 있지만 'AMQP'프로토콜에 적응하고 자신의 노드를 관리해야합니다.
Amazon SQS 는 호스팅되지만 대기 시간이 높을 수 있으며 메시지가 두 번 전달 될 가능성이 있습니다.
작업 대기열은 작업을 수신하고 관련 데이터를 실행 한 다음 결과를 전달합니다. 그들은 스케줄링을 지원할 수 있으며 백그라운드에서 계산 집약적 인 작업을 실행하는 데 사용될 수 있습니다.
Celery는 스케줄링을 지원하며 주로 Python 지원이 있습니다.
대기열이 크게 증가하기 시작하면 큐 크기가 메모리보다 커질 수있어 캐시 미스, 디스크 읽기 및 성능이 느려질 수 있습니다. 등 압력은 대기열 크기를 제한함으로써 도움이 될 수 있으므로 이미 큐에있는 작업에 대한 높은 처리량 속도와 좋은 응답 시간을 유지할 수 있습니다. 대기열이 채워지면 클라이언트는 서버를 바쁘게 또는 HTTP 503 상태 코드를 얻을 수 있도록 나중에 다시 시도합니다. 클라이언트는 나중에 지수 백 오프를 통해 요청을 재 시도 할 수 있습니다.
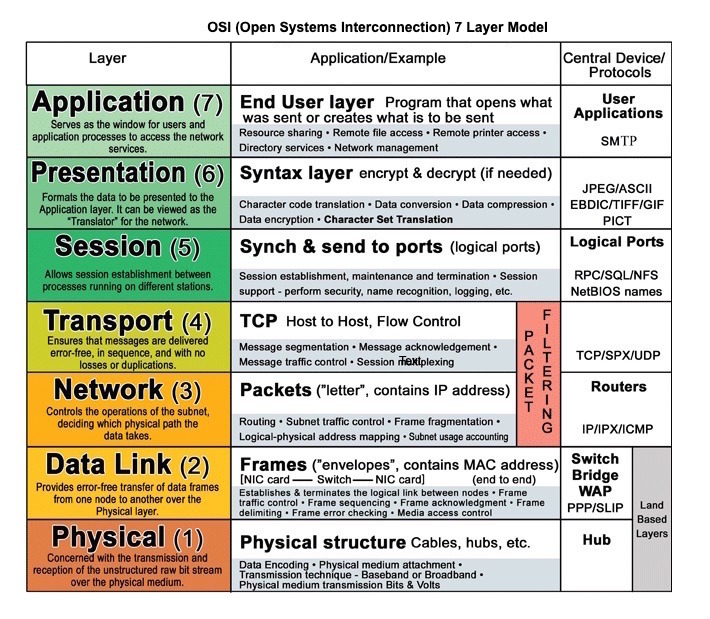
출처 : OSI 7 층 모델
HTTP는 클라이언트와 서버간에 데이터를 인코딩하고 전송하는 방법입니다. 요청/응답 프로토콜입니다. 클라이언트는 요청 및 서버를 발행하여 관련 컨텐츠 및 요청에 대한 완료 상태 정보를 발행합니다. HTTP는 자체 포함하여로드 밸런싱, 캐싱, 암호화 및 압축을 수행하는 많은 중간 라우터 및 서버를 통해 요청 및 응답이 흐를 수 있습니다.
기본 HTTP 요청은 동사 (메소드)와 리소스 (endpoint)로 구성됩니다. 아래는 일반적인 HTTP 동사입니다.
| 동사 | 설명 | idempotent* | 안전한 | 캐시 가능 |
|---|---|---|---|---|
| 얻다 | 리소스를 읽습니다 | 예 | 예 | 예 |
| 우편 | 자원을 생성하거나 데이터를 처리하는 프로세스를 트리거합니다. | 아니요 | 아니요 | 응답에 신선도 정보가 포함 된 경우 예 |
| 놓다 | 자원을 생성하거나 교체합니다 | 예 | 아니요 | 아니요 |
| 반점 | 리소스를 부분적으로 업데이트합니다 | 아니요 | 아니요 | 응답에 신선도 정보가 포함 된 경우 예 |
| 삭제 | 리소스를 삭제합니다 | 예 | 아니요 | 아니요 |
*다른 결과없이 여러 번 호출 할 수 있습니다.
HTTP는 TCP 및 UDP 와 같은 하위 레벨 프로토콜에 의존하는 응용 프로그램 계층 프로토콜입니다.
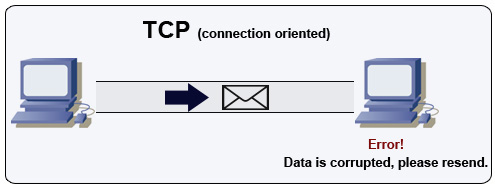
출처 : 멀티 플레이어 게임을 만드는 방법
TCP는 IP 네트워크를 통한 연결 지향 프로토콜입니다. 핸드 셰이크를 사용하여 연결이 설정되어 종료됩니다. 전송 된 모든 패킷은 원래 순서로 목적지에 도달 할 수 있으며 부패없이 :
발신자가 올바른 응답을받지 않으면 패킷을 재판매합니다. 여러 타임 아웃이 있으면 연결이 삭제됩니다. TCP는 또한 흐름 제어 및 정체 제어를 구현합니다. 이러한 보증은 지연을 일으키고 일반적으로 UDP보다 효율적인 전송을 초래합니다.
높은 처리량을 보장하기 위해 웹 서버는 많은 수의 TCP 연결을 열어 두어 메모리 사용이 높아질 수 있습니다. 웹 서버 스레드와 멤버 서버 사이에 많은 수의 열린 연결이 있으면 비용이 많이들 수 있습니다. 연결 풀링은 해당되는 경우 UDP로 전환하는 것 외에도 도움이 될 수 있습니다.
TCP는 높은 신뢰성이 필요하지만 시간이 적은 응용 프로그램에 유용합니다. 몇 가지 예로는 웹 서버, 데이터베이스 정보, SMTP, FTP 및 SSH가 있습니다.
UDP를 통해 TCP를 사용하십시오.
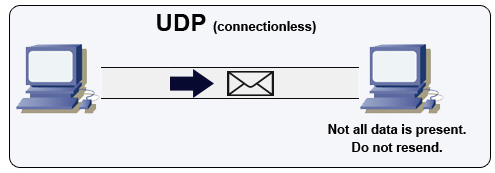
출처 : 멀티 플레이어 게임을 만드는 방법
UDP는 연결이 없습니다. 데이터 그램 (패킷과 유사)은 데이터 그램 수준에서만 보장됩니다. 데이터 그램은 순서대로 목적지에 도달 할 수 있습니다. UDP는 정체 제어를 지원하지 않습니다. TCP 지원을 보장하지 않으면 UDP가 일반적으로 더 효율적입니다.
UDP는 방송 될 수 있으며 서브넷의 모든 장치에 데이터 그램을 전송할 수 있습니다. 클라이언트가 아직 IP 주소를 수신하지 않았으므로 IP 주소없이 TCP가 스트리밍하는 방법을 방지하기 때문에 DHCP에 유용합니다.
UDP는 신뢰성이 떨어지지 만 VoIP, 화상 채팅, 스트리밍 및 실시간 멀티 플레이어 게임과 같은 실시간 사용 사례에서 잘 작동합니다.
다음과 같은 경우 TCP를 통해 UDP를 사용하십시오.
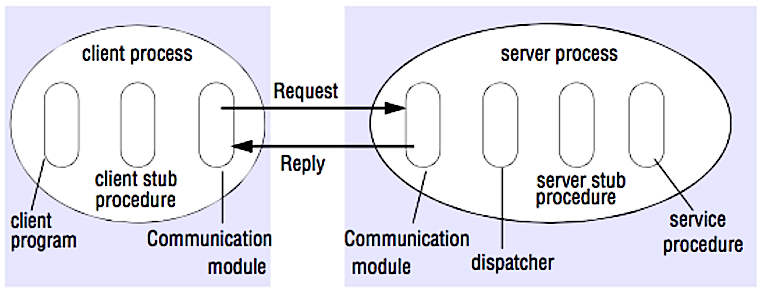
출처 : 시스템 설계 인터뷰를 크랙하십시오
RPC에서 클라이언트는 프로 시저가 다른 주소 공간, 일반적으로 원격 서버에서 실행됩니다. 절차는 현지 절차 호출 인 것처럼 코딩되어 클라이언트 프로그램에서 서버와 통신하는 방법에 대한 세부 사항을 추상화합니다. 원격 통화는 일반적으로 로컬 통화보다 느리고 신뢰성이 떨어지므로 RPC 통화를 로컬 통화와 구별하는 데 도움이됩니다. 인기있는 RPC 프레임 워크에는 Protobuf, Thrift 및 Avro가 포함됩니다.
RPC는 요청-응답 프로토콜입니다.
샘플 rpc 호출 :
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC는 행동 노출에 중점을 둡니다. RPC는 사용 사례에 더 잘 맞도록 기본 통화를 손으로 크래프 할 수 있으므로 내부 통신의 성능 이유에 종종 사용됩니다.
다음과 같은 경우 기본 라이브러리 (일명 SDK)를 선택하십시오.
휴식 후 HTTP API는 공개 API에 더 자주 사용되는 경향이 있습니다.
REST는 클라이언트가 서버가 관리하는 일련의 리소스에서 작용하는 클라이언트/서버 모델을 시행하는 아키텍처 스타일입니다. 서버는 새로운 리소스를 조작하거나 얻을 수있는 리소스 및 조치의 표현을 제공합니다. 모든 커뮤니케이션은 상태가없고 캐시 가능해야합니다.
편안한 인터페이스의 네 가지 특성이 있습니다.
샘플 휴식 전화 :
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
REST는 데이터 노출에 중점을 둡니다. 클라이언트/서버 간의 커플 링을 최소화하며 종종 공개 HTTP API에 사용됩니다. REST는 URI, 헤더를 통한 표현 및 Get, Post, Put, Delete 및 Patch와 같은 동사를 통한 동작을 통해 리소스를 노출시키는보다 일반적이고 균일 한 방법을 사용합니다. 상태가없는 상태에서 휴식은 수평 스케일링 및 분할에 좋습니다.
| 작업 | RPC | 나머지 |
|---|---|---|
| 가입 | 게시 /가입 | 게시물 /사람 |
| 사직하다 | 우편 /사임 { "personid": "1234" } | 삭제 /사람 /1234 |
| 사람을 읽으십시오 | Get /Readperson? personid = 1234 | GET /PENSES /1234 |
| 사람의 항목 목록을 읽으십시오 | get /readusersitemslist? personid = 1234 | GET /PENSES/1234/항목 |
| 사람의 항목에 항목을 추가하십시오 | post /additemtousersitemslist { "personid": "1234"; "itemid": "456" } | Post /Persons/1234/항목 { "itemid": "456" } |
| 항목을 업데이트하십시오 | 게시 /modifyitem { "itemid": "456"; "키": "가치" } | /항목 /456 을 넣습니다 { "키": "가치" } |
| 항목을 삭제하십시오 | Post /RemodItem { "itemid": "456" } | 삭제 /항목 /456 |
출처 : RPC보다 휴식을 선호하는 이유를 정말로 알고 있습니까?
이 섹션에서는 일부 업데이트를 사용할 수 있습니다. 기여를 고려하십시오!
보안은 광범위한 주제입니다. 상당한 경험, 보안 배경이 있거나 보안에 대한 지식이 필요한 직책을 신청하지 않는 한, 기본보다 더 많은 것을 알 필요가 없을 것입니다.
때때로 '뒷좌석'추정치를 요구할 것입니다. 예를 들어, 디스크에서 100 개의 이미지 썸네일을 생성하는 데 걸리는 시간 또는 데이터 구조가 얼마나 많은 메모리를 사용하는지 결정해야 할 수도 있습니다. 모든 프로그래머가 알아야 할 두 개의 테이블 및 대기 시간 번호의 힘은 편리한 참조입니다.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
위의 숫자를 기반으로 한 편리한 메트릭 :
일반적인 시스템 설계 인터뷰 질문, 각각을 해결하는 방법에 대한 리소스에 대한 링크.
| 질문 | 참고자료 |
|---|---|
| Dropbox와 같은 파일 동기화 서비스를 설계하십시오 | youtube.com |
| Google과 같은 검색 엔진을 설계하십시오 | queue.acm.org stackexchange.com ardendertat.com Stanford.edu |
| Google과 같은 확장 가능한 웹 크롤러를 설계하십시오 | quora.com |
| Google Docs를 디자인하십시오 | code.google.com Neil.fraser.name |
| Redis와 같은 키 가치 상점을 설계하십시오 | Slideshare.net |
| Memcached와 같은 캐시 시스템을 설계하십시오 | Slideshare.net |
| 아마존과 같은 추천 시스템을 설계하십시오 | hulu.com ijcai13.org |
| 약간 같은 작은 시스템을 설계하십시오 | n00tc0d3r.blogspot.com |
| WhatsApp과 같은 채팅 앱을 디자인하십시오 | HighScalability.com |
| Instagram과 같은 그림 공유 시스템을 설계하십시오 | HighScalability.com HighScalability.com |
| Facebook 뉴스 피드 기능을 설계하십시오 | quora.com quora.com Slideshare.net |
| Facebook 타임 라인 기능을 설계하십시오 | facebook.com HighScalability.com |
| Facebook 채팅 기능을 설계하십시오 | Erlang-factory.com facebook.com |
| Facebook과 같은 그래프 검색 기능을 설계하십시오 | facebook.com facebook.com facebook.com |
| CloudFlare와 같은 콘텐츠 전달 네트워크를 설계하십시오 | figshare.com |
| 트위터와 같은 트렌드 주제 시스템을 설계하십시오 | Michael-noll.com snikolov .wordpress.com |
| 임의의 ID 생성 시스템을 설계하십시오 | blog.twitter.com github.com |
| 시간 간격 동안 상단 K 요청을 반환합니다 | cs.ucsb.edu wpi.edu |
| 여러 데이터 센터의 데이터를 제공하는 시스템 설계 | HighScalability.com |
| 온라인 멀티 플레이어 카드 게임을 디자인하십시오 | indieflashblog.com buildnewgames.com |
| 쓰레기 수집 시스템을 설계하십시오 | wittswithstuff.com Washington.edu |
| API 속도 리미터를 설계하십시오 | https://stripe.com/blog/ |
| 증권 거래소 설계 (NASDAQ 또는 BINANCE와 같은) | 제인 스트리트 Golang 구현 GO 구현 |
| 시스템 설계 질문을 추가하십시오 | 기여하다 |
실제 시스템 설계 방법에 대한 기사.
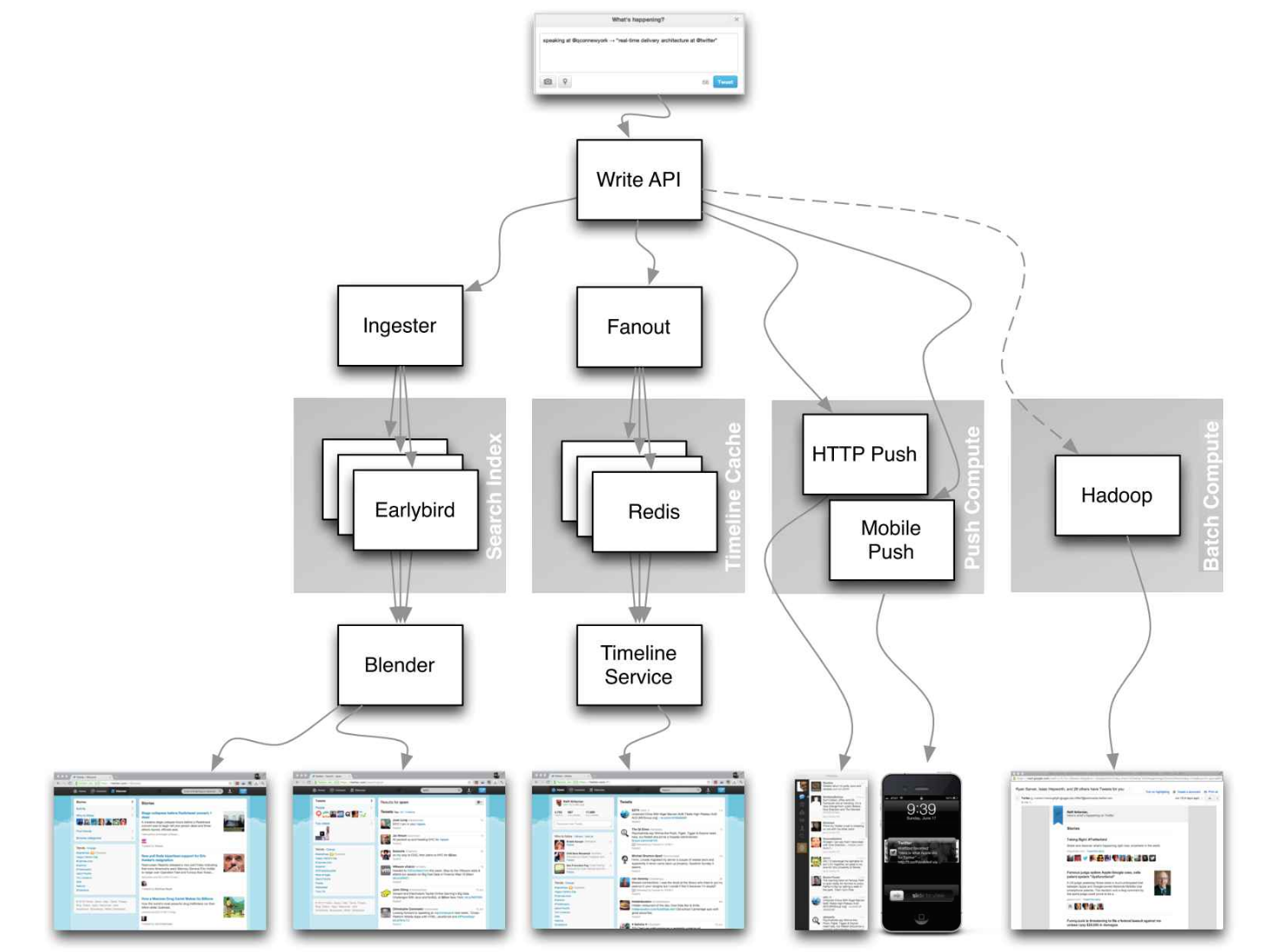
출처 : 스케일의 트위터 타임 라인
대신 다음 기사에 대한 끔찍한 세부 사항에 초점을 맞추지 마십시오.
| 유형 | 체계 | 참고자료 |
|---|---|---|
| 데이터 처리 | MapReduce- Google의 분산 데이터 처리 | research.google.com |
| 데이터 처리 | SPARK- 데이터 사업에서 분산 데이터 처리 | Slideshare.net |
| 데이터 처리 | 폭풍 - 트위터에서 분산 데이터 처리 | Slideshare.net |
| 데이터 저장소 | Bigtable- Google의 배포 된 열 중심 데이터베이스 | Harvard.edu |
| 데이터 저장소 | HBASE- BigTable의 오픈 소스 구현 | Slideshare.net |
| 데이터 저장소 | Cassandra- Facebook에서 배포 된 열 중심 데이터베이스 | Slideshare.net |
| 데이터 저장소 | DynamoDB- Amazon의 문서 지향 데이터베이스 | Harvard.edu |
| 데이터 저장소 | MongoDB- 문서 지향 데이터베이스 | Slideshare.net |
| 데이터 저장소 | 스패너 - Google에서 전 세계적으로 분산 된 데이터베이스 | research.google.com |
| 데이터 저장소 | Memcached- 분산 메모리 캐싱 시스템 | Slideshare.net |
| 데이터 저장소 | Redis- 지속성 및 가치 유형을 갖는 분산 메모리 캐싱 시스템 | Slideshare.net |
| 파일 시스템 | GFS (Google 파일 시스템) - 분산 파일 시스템 | research.google.com |
| 파일 시스템 | Hadoop 파일 시스템 (HDFS) - GFS의 오픈 소스 구현 | apache.org |
| 기타 | Chubby- Google에서 느슨하게 결합 된 분산 시스템을위한 잠금 서비스 | research.google.com |
| 기타 | DAPPER- 분산 시스템 추적 인프라 | research.google.com |
| 기타 | Kafka- LinkedIn의 Pub/Sub Message Deue | Slideshare.net |
| 기타 | Zookeeper- 중앙 집중식 인프라 및 서비스 동기화 가능 | Slideshare.net |
| 아키텍처를 추가하십시오 | 기여하다 |
| 회사 | 참고자료 |
|---|---|
| 아마존 | 아마존 아키텍처 |
| CINCHCAST | 매일 1,500 시간의 오디오를 생산합니다 |
| DataSift | 초당 120,000 개의 트윗에서 실시간 데이터 미닝 |
| 드롭박스 | Dropbox를 축소하는 방법 |
| ESPN | 초당 100,000 DUH NUH NUHS에서 작동합니다 |
| Google 아키텍처 | |
| 인스타그램 | 1,400 만 명의 사용자, 테라 바이트 사진 인스 타 그램의 힘 |
| Justin.tv | Justin.TV의 라이브 비디오 방송 아키텍처 |
| 페이스북 | Facebook에서 Memcached Scaling TAO : 소셜 그래프를위한 Facebook의 분산 데이터 저장 Facebook의 사진 저장 Facebook이 800,000 명의 동시 시청자에게 라이브 스트리밍하는 방법 |
| 플리커 | 플리커 아키텍처 |
| 사서함 | 6 주 동안 0 ~ 백만 명의 사용자 |
| 넷플릭스 | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| 핀터레스트 | From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| 세일즈포스 | How they handle 1.3 billion transactions a day |
| 스택 오버플로 | Stack Overflow architecture |
| 트립어드바이저 | 40M visitors, 200M dynamic page views, 30TB data |
| 텀블러 | 15 billion page views a month |
| 지저귀다 | Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second |
| 우버 | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| 왓츠앱 | The WhatsApp architecture Facebook bought for $19 billion |
| 유튜브 | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress? 기여하다!
Credits and sources are provided throughout this repo.
특별히 감사드립니다:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


