textgenrnn
T
몇 줄의 코드로 모든 텍스트 데이터 세트에서 크기와 복잡성에 관계없이 자체 텍스트 생성 신경망을 쉽게 훈련하거나 사전 훈련된 모델을 사용하여 텍스트에 대해 빠르게 훈련할 수 있습니다.
textgenrnn은 char-rnns를 생성하기 위한 Keras/TensorFlow 위에 있는 Python 3 모듈로, 많은 멋진 기능을 갖추고 있습니다.
이 Colaboratory Notebook에서 무료로 textgenrnn을 사용하고 GPU를 사용하여 모든 텍스트 파일을 학습시킬 수 있습니다! 자세한 내용을 알아보려면 이 블로그 게시물을 읽거나 이 비디오를 시청하세요!
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate () [Spoiler] Anyone else find this post and their person that was a little more than I really like the Star Wars in the fire or health and posting a personal house of the 2016 Letter for the game in a report of my backyard.
포함된 모델은 새로운 텍스트에 대해 쉽게 학습할 수 있으며 입력 데이터가 한 번 전달된 후에도 적절한 텍스트를 생성할 수 있습니다.
textgen . train_from_file ( 'hacker_news_2000.txt' , num_epochs = 1 )
textgen . generate () Project State Project Firefox
모델 가중치는 상대적으로 작으며(디스크의 경우 2MB) 새 textgenrnn 인스턴스에 쉽게 저장하고 로드할 수 있습니다. 결과적으로 수백 번의 데이터 전달을 통해 훈련된 모델을 가지고 놀 수 있습니다. (사실 textgenrnn은 학습을 너무 잘 해서 창의적인 출력을 위해서는 온도를 크게 높여야 합니다!)
textgen_2 = textgenrnn ( '/weights/hacker_news.hdf5' )
textgen_2 . generate ( 3 , temperature = 1.0 ) Why we got money “regular alter”
Urburg to Firefox acquires Nelf Multi Shamn
Kubernetes by Google’s Bern
학습 함수에 new_model=True 추가하면 단어 수준 임베딩 및 양방향 RNN 레이어를 지원하여 새 모델을 학습할 수도 있습니다.
출력이 어떻게 전개되는지 단계별로 참여하는 것도 가능합니다. 대화형 모드에서는 다음 문자/단어에 대한 상위 N 개 옵션을 제안하고 하나를 선택할 수 있습니다.
터미널에서 generate 을 실행할 때 interactive=True 및 top=N 전달하여 . N의 기본값은 3입니다.
from textgenrnn import textgenrnn
textgen = textgenrnn ()
textgen . generate ( interactive = True , top_n = 5 )
이렇게 하면 출력에 사람의 손길을 더할 수 있습니다. 마치 작가가 된 것 같은 느낌이에요! (참조)
textgenrnn은 pip 를 통해 pypi에서 설치할 수 있습니다.
pip3 install textgenrnn최신 textgenrnn의 경우 최소 TensorFlow 버전 2.1.0이 있어야 합니다 .
이 Jupyter Notebook에서 일반적인 기능 및 모델 구성 옵션에 대한 데모를 볼 수 있습니다.
/datasets 에는 textgenrnn 교육을 위해 Hacker News/Reddit 데이터를 사용하는 예제 데이터세트가 포함되어 있습니다.
/weights textgenrnn에 로드할 수 있는 앞서 언급한 데이터 세트에 대한 사전 훈련된 모델이 포함되어 있습니다.
/outputs 에는 위의 사전 학습된 모델에서 생성된 텍스트의 예가 포함되어 있습니다.
textgenrnn은 Andrej Karpathy의 char-rnn 프로젝트를 기반으로 하며 매우 작은 텍스트 시퀀스로 작업하는 기능과 같은 몇 가지 현대적인 최적화 기능을 갖추고 있습니다.
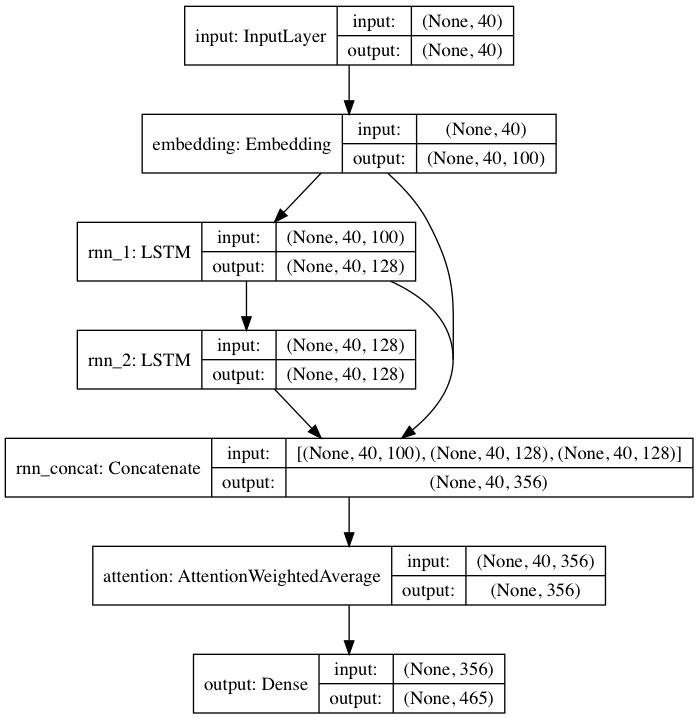
포함된 사전 훈련 모델은 DeepMoji에서 영감을 받은 신경망 아키텍처를 따릅니다. 기본 모델의 경우 textgenrnn은 최대 40자의 입력을 받아 각 문자를 100차원 문자 임베딩 벡터로 변환하고 이를 128셀 LSTM(장단기 메모리) 순환 계층에 공급합니다. 그런 다음 해당 출력은 다른 128셀 LSTM에 공급됩니다. 그런 다음 세 레이어 모두 Attention 레이어에 입력되어 가장 중요한 시간적 특징에 가중치를 부여하고 함께 평균을 냅니다. (그리고 임베딩 + 첫 번째 LSTM이 어텐션 레이어로 건너뛰어 연결되므로 모델 업데이트가 더 쉽게 역전파되어 사라지는 것을 방지할 수 있습니다. 그라데이션). 해당 출력은 대문자, 소문자, 구두점 및 이모티콘을 포함하여 최대 394개의 서로 다른 문자가 시퀀스의 다음 문자일 확률에 매핑됩니다. (새 데이터 세트에서 새 모델을 훈련하는 경우 위의 모든 숫자 매개 변수를 구성할 수 있습니다)
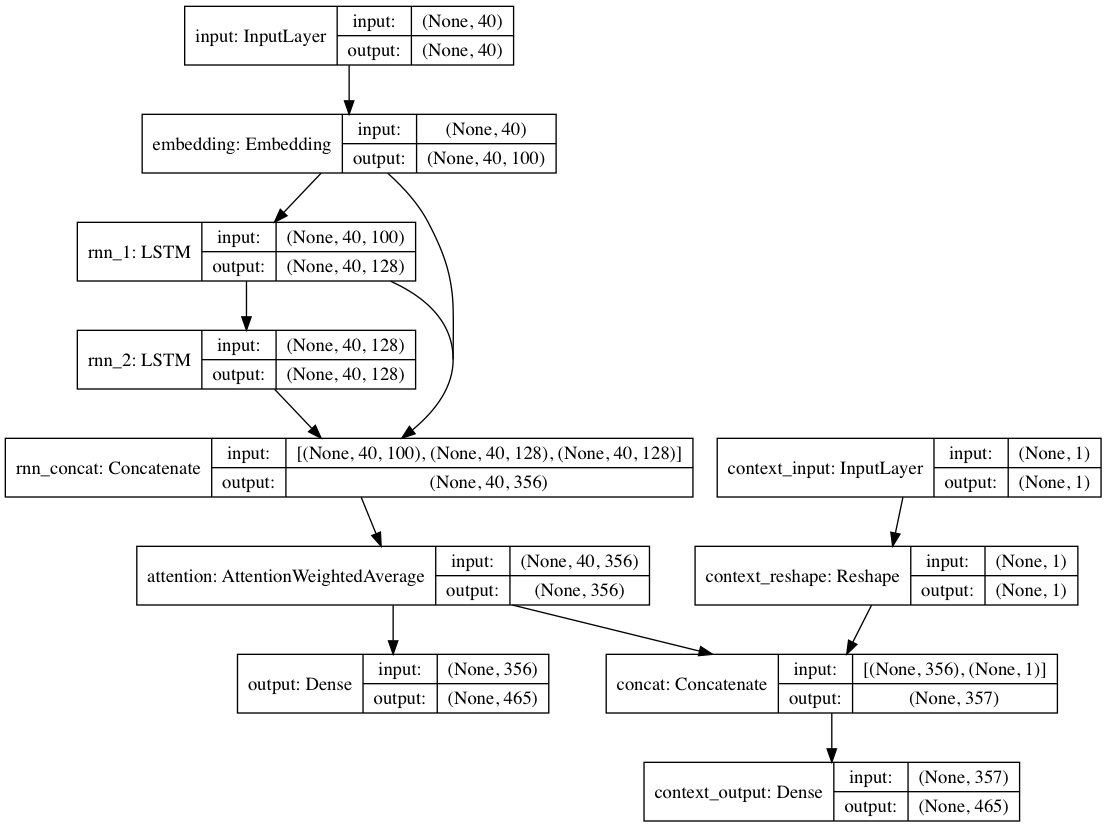
또는 컨텍스트 레이블이 각 텍스트 문서에 제공되는 경우 모델은 컨텍스트 모드에서 훈련될 수 있습니다. 여기서 모델은 컨텍스트에 따라 텍스트를 학습하므로 반복 레이어는 컨텍스트 해제된 언어를 학습합니다. 텍스트 전용 경로는 비맥락화된 레이어를 피기백할 수 있습니다. 전체적으로 이는 텍스트만 사용하여 모델을 훈련하는 것보다 훨씬 더 빠른 훈련과 더 나은 정량적, 질적 모델 성능을 제공합니다.
패키지에 포함된 모델 가중치는 매우 다양한 하위 레딧의 Reddit 제출(BigQuery를 통해)에서 가져온 수십만 개의 텍스트 문서에 대해 훈련되었습니다. 또한 네트워크는 훈련 성능을 향상시키고 저자의 편견을 완화하기 위해 위에서 언급한 비맥락적 접근 방식을 사용하여 훈련되었습니다.
textgenrnn을 사용하여 새로운 텍스트 데이터 세트에서 모델을 미세 조정하면 모든 레이어가 다시 학습됩니다. 그러나 원래의 사전 훈련된 네트워크는 처음에 훨씬 더 강력한 "지식"을 갖기 때문에 새로운 textgenrnn은 결국 더 빠르고 정확하게 훈련하고 원래 데이터 세트에 없는 새로운 관계를 잠재적으로 학습할 수 있습니다(예: 사전 훈련된 문자 임베딩에는 컨텍스트가 포함됩니다). 가능한 모든 유형의 현대 인터넷 문법에 대한 문자).
또한 재교육은 모멘텀 기반 최적화 프로그램과 선형적으로 감소하는 학습률을 사용하여 수행됩니다. 두 가지 모두 경사도 폭발을 방지하고 오랜 시간 동안 교육한 후 모델이 분기될 가능성을 훨씬 줄여줍니다.
고도로 훈련된 신경망을 사용하더라도 품질이 100% 생성된 텍스트를 얻을 수는 없습니다 . 이것이 NN 텍스트 생성을 활용하는 바이러스성 블로그 게시물/트위터 트윗이 종종 많은 텍스트를 생성하고 나중에 가장 좋은 텍스트를 선별/편집하는 주된 이유입니다.
결과는 데이터 세트마다 크게 다릅니다 . 사전 훈련된 신경망은 상대적으로 작기 때문에 일반적으로 블로그 게시물에서 자랑하는 RNN만큼 많은 데이터를 저장할 수 없습니다. 최상의 결과를 얻으려면 최소 2,000~5,000개의 문서가 포함된 데이터세트를 사용하세요. 데이터 세트가 더 작은 경우 훈련 방법을 호출하거나 새 모델을 처음부터 훈련할 때 num_epochs 더 높게 설정하여 더 오랫동안 훈련해야 합니다. 그럼에도 불구하고 현재 "좋은" 모델을 결정하기 위한 좋은 경험적 방법은 없습니다.
textgenrnn을 재교육하는 데 GPU가 필요하지 않지만 CPU에서 교육하는 데는 훨씬 더 오랜 시간이 걸립니다. GPU를 사용하는 경우 더 나은 하드웨어 활용을 위해 batch_size 매개변수를 늘리는 것이 좋습니다.
더 공식적인 문서
tensorflow.js를 사용한 웹 기반 구현(네트워크의 작은 크기로 인해 특히 잘 작동함)
네트워크가 어떻게 "학습"하는지 확인하기 위해 주의 계층 출력을 시각화하는 방법입니다.
모델 아키텍처를 챗봇 대화에 사용할 수 있는 모드(별도의 프로젝트로 출시될 수 있음)
컨텍스트에 대한 더 깊은 깊이(위치 컨텍스트 + 여러 컨텍스트 레이블 허용)
더 긴 문자 시퀀스와 언어에 대한 더 심층적인 이해를 수용하여 더 나은 문장을 생성할 수 있는 대규모 사전 훈련된 네트워크입니다.
단어 수준 모델을 위한 계층적 소프트맥스 활성화(Keras가 이를 잘 지원하는 경우)
Volta/TPU에 대한 초고속 훈련을 위한 FP16(Keras가 이를 잘 지원한다면)
맥스 울프(@minimaxir)
Max의 오픈 소스 프로젝트는 Patreon의 지원을 받습니다. 이 프로젝트가 도움이 되었다면 Patreon에 대한 금전적인 기여에 감사드리며 창의적으로 활용될 것입니다.
Andrej Karpathy는 블로그 게시물 The Unreasonable Effectiveness of Recurrent Neural Networks를 통해 char-rnn의 원래 제안을 제공했습니다.
대화형 모드에 기여한 Daniel Grijalva.
MIT
DeepMoji에서 사용된 주의 계층 코드(MIT 라이선스)


