optuna
v4.1.0
? 웹사이트 | ? 문서 | 설치 가이드 | 튜토리얼 | 예 | 트위터 | 링크드인 | 중간
Optuna 는 특히 기계 학습을 위해 설계된 자동 하이퍼파라미터 최적화 소프트웨어 프레임워크입니다. 필수적이고 실행별로 정의되는 스타일의 사용자 API가 특징입니다. 실행별 정의 API 덕분에 Optuna로 작성된 코드는 높은 모듈성을 누리며 Optuna 사용자는 하이퍼파라미터에 대한 검색 공간을 동적으로 구성할 수 있습니다.
Terminator 에 대한 기사를 게시했습니다.JournalStorage 에 대한 기사를 게시했습니다.pip install -U optuna 로 설치할 수 있습니다. 여기에서 최신 정보를 찾아보고 기사를 확인하세요. Optuna는 다음과 같은 최신 기능을 갖추고 있습니다.
우리는 연구 와 시험이라는 용어를 다음과 같이 사용합니다.
아래 샘플코드를 참고해주세요. 연구 의 목표는 여러 번의 시도 (예: n_trials=100 )를 통해 최적의 하이퍼파라미터 값 세트(예: regressor 및 svr_c )를 찾는 것입니다. Optuna는 최적화 연구 의 자동화 및 가속화를 위해 설계된 프레임워크입니다.
import ...
# Define an objective function to be minimized.
def objective ( trial ):
# Invoke suggest methods of a Trial object to generate hyperparameters.
regressor_name = trial . suggest_categorical ( 'regressor' , [ 'SVR' , 'RandomForest' ])
if regressor_name == 'SVR' :
svr_c = trial . suggest_float ( 'svr_c' , 1e-10 , 1e10 , log = True )
regressor_obj = sklearn . svm . SVR ( C = svr_c )
else :
rf_max_depth = trial . suggest_int ( 'rf_max_depth' , 2 , 32 )
regressor_obj = sklearn . ensemble . RandomForestRegressor ( max_depth = rf_max_depth )
X , y = sklearn . datasets . fetch_california_housing ( return_X_y = True )
X_train , X_val , y_train , y_val = sklearn . model_selection . train_test_split ( X , y , random_state = 0 )
regressor_obj . fit ( X_train , y_train )
y_pred = regressor_obj . predict ( X_val )
error = sklearn . metrics . mean_squared_error ( y_val , y_pred )
return error # An objective value linked with the Trial object.
study = optuna . create_study () # Create a new study.
study . optimize ( objective , n_trials = 100 ) # Invoke optimization of the objective function. 메모
더 많은 예제는 optuna/optuna-examples에서 찾을 수 있습니다.
예제에서는 다중 목표 최적화, 제한된 최적화, 가지치기 및 분산 최적화와 같은 다양한 문제 설정을 다룹니다.
Optuna는 Python Package Index 및 Anaconda Cloud에서 사용할 수 있습니다.
# PyPI
$ pip install optuna # Anaconda Cloud
$ conda install -c conda-forge optuna중요한
Optuna는 Python 3.8 이상을 지원합니다.
또한 DockerHub에서 Optuna 도커 이미지를 제공합니다.
Optuna에는 다양한 타사 라이브러리와의 통합 기능이 있습니다. 통합은 optuna/optuna-integration에서 찾을 수 있으며 문서는 여기에서 볼 수 있습니다.
Optuna 대시보드는 Optuna의 실시간 웹 대시보드입니다. 최적화 이력, 하이퍼파라미터 중요도 등을 그래프와 표로 확인할 수 있습니다. Optuna의 시각화 기능을 호출하기 위해 Python 스크립트를 만들 필요가 없습니다. 기능 요청 및 버그 보고서를 환영합니다!
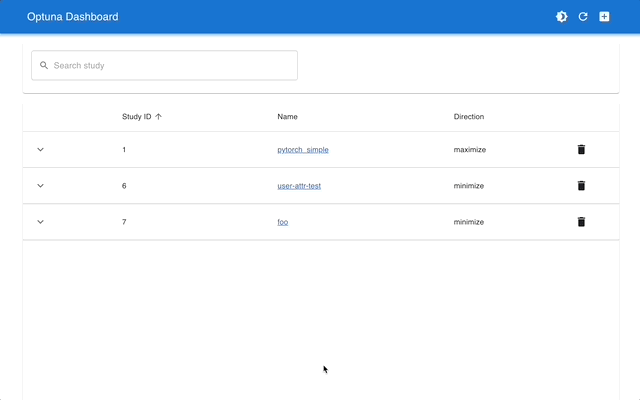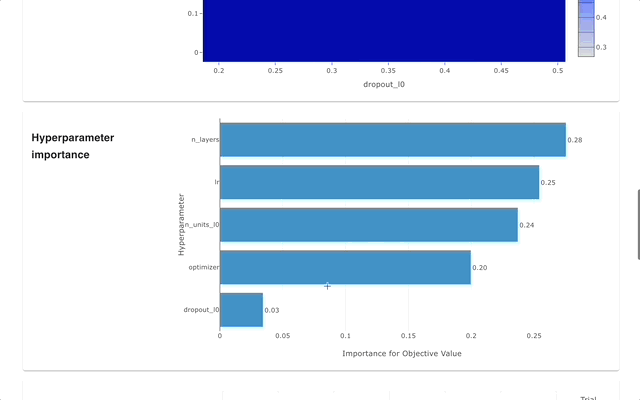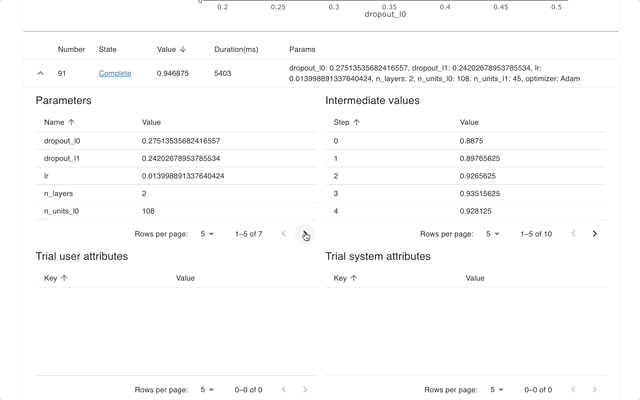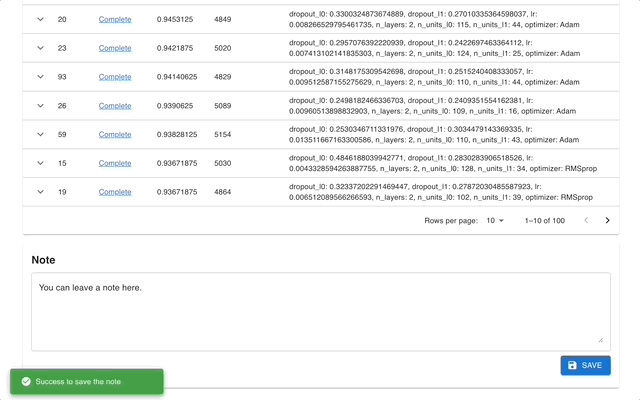
optuna-dashboard pip를 통해 설치할 수 있습니다.
$ pip install optuna-dashboard팁
아래 샘플코드를 통해 Optuna Dashboard의 편리함을 확인해보세요.
다음 코드를 optimize_toy.py 로 저장하세요.
import optuna
def objective ( trial ):
x1 = trial . suggest_float ( "x1" , - 100 , 100 )
x2 = trial . suggest_float ( "x2" , - 100 , 100 )
return x1 ** 2 + 0.01 * x2 ** 2
study = optuna . create_study ( storage = "sqlite:///db.sqlite3" ) # Create a new study with database.
study . optimize ( objective , n_trials = 100 )그런 다음 아래 명령을 시도해 보십시오.
# Run the study specified above
$ python optimize_toy.py
# Launch the dashboard based on the storage `sqlite:///db.sqlite3`
$ optuna-dashboard sqlite:///db.sqlite3
...
Listening on http://localhost:8080/
Hit Ctrl-C to quit.OptunaHub는 Optuna의 기능 공유 플랫폼입니다. 등록된 기능을 사용하고 패키지를 게시할 수 있습니다.
optunahub pip를 통해 설치할 수 있습니다.
$ pip install optunahub
# Install AutoSampler dependencies (CPU only is sufficient for PyTorch)
$ pip install cmaes scipy torch --extra-index-url https://download.pytorch.org/whl/cpu optunahub.load_module 사용하여 등록된 모듈을 로드할 수 있습니다.
import optuna
import optunahub
def objective ( trial : optuna . Trial ) -> float :
x = trial . suggest_float ( "x" , - 5 , 5 )
y = trial . suggest_float ( "y" , - 5 , 5 )
return x ** 2 + y ** 2
module = optunahub . load_module ( package = "samplers/auto_sampler" )
study = optuna . create_study ( sampler = module . AutoSampler ())
study . optimize ( objective , n_trials = 10 )
print ( study . best_trial . value , study . best_trial . params )자세한 내용은 optunahub 설명서를 참조하세요.
optunahub-registry를 통해 패키지를 게시할 수 있습니다. OptunaHub 튜토리얼을 참조하세요.
Optuna에 대한 어떤 기여도 환영합니다!
옵투나를 처음 접하시는 분들은 좋은 첫 이슈를 꼭 확인해 보세요. 비교적 간단하고 잘 정의되어 있으며 기여 작업 흐름과 다른 개발자에 익숙해지기 위한 좋은 출발점이 되는 경우가 많습니다.
이미 Optuna에 기여한 경우 다른 기여 환영 이슈를 권장합니다.
프로젝트에 기여하는 방법에 대한 일반적인 지침은 CONTRIBUTING.md를 살펴보세요.
연구 프로젝트 중 하나에서 Optuna를 사용하는 경우 KDD 논문 "Optuna: 차세대 하이퍼파라미터 최적화 프레임워크"를 인용해 주세요.
@inproceedings { akiba2019optuna ,
title = { {O}ptuna: A Next-Generation Hyperparameter Optimization Framework } ,
author = { Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori } ,
booktitle = { The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining } ,
pages = { 2623--2631 } ,
year = { 2019 }
}MIT 라이센스(라이센스 참조).
Optuna는 SciPy 및 fdlibm 프로젝트의 코드를 사용합니다(LICENSE_THIRD_PARTY 참조).


