cleanrl
v1.0.0 CleanRL Release ?
CleanRL은 연구 친화적인 기능으로 고품질 단일 파일 구현을 제공하는 심층 강화 학습 라이브러리입니다. 구현은 깔끔하고 간단하지만 AWS Batch를 사용하여 수천 번의 실험을 실행하도록 확장할 수 있습니다. CleanRL의 주요 기능은 다음과 같습니다.
ppo_atari.py 에는 340줄의 코드만 있지만 PPO가 Atari 게임과 어떻게 작동하는지에 대한 모든 구현 세부 정보가 포함되어 있으므로 전체 모듈 라이브러리를 읽고 싶지 않은 사람들이 읽을 수 있는 훌륭한 참조 구현입니다 .JMLR 문서와 문서에서 CleanRL에 대해 자세히 알아볼 수 있습니다.
주목할만한 CleanRL 관련 프로젝트:
체육관 지원 : Farama-Foundation/Gymnasium은 지속적으로 유지 관리되고 새로운 기능을 도입할 차세대
openai/gym입니다. 자세한 내용은 해당 공지를 참조하세요. 우리는gymnasium으로 이전 중이며 vwxyzjn/cleanrl#277에서 진행 상황을 추적할 수 있습니다.
️ 참고 : CleanRL은 모듈식 라이브러리가 아니므 로 가져올 수 없습니다. 중복된 코드를 사용하여 DRL 알고리즘 변형의 모든 구현 세부 사항을 이해하기 쉽게 만들었으므로 CleanRL에는 고유한 장단점이 있습니다. 1) 알고리즘 변수의 모든 구현 세부 사항을 이해하거나 2) 다른 모듈식 DRL 라이브러리가 지원하지 않는 고급 기능 프로토타입을 원하는 경우 CleanRL 사용을 고려해야 합니다(CleanRL은 코드 줄이 최소화되어 훌륭한 디버깅 경험을 제공하지만 그렇지 않은 경우). 모듈식 DRL 라이브러리처럼 서브클래싱을 많이 수행하지 않았습니다.
전제 조건:
로컬에서 실험을 실행하려면 다음을 시도해 보세요.
git clone https://github.com/vwxyzjn/cleanrl.git && cd cleanrl
poetry install
# alternatively, you could use `poetry shell` and do
# `python run cleanrl/ppo.py`
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
# open another terminal and enter `cd cleanrl/cleanrl`
tensorboard --logdir runswandb로 실험 추적을 사용하려면 다음을 실행하세요.
wandb login # only required for the first time
poetry run python cleanrl/ppo.py
--seed 1
--env-id CartPole-v0
--total-timesteps 50000
--track
--wandb-project-name cleanrltest poetry 사용하지 않는 경우, requirements.txt 를 사용하여 CleanRL을 설치할 수 있습니다.
# core dependencies
pip install -r requirements/requirements.txt
# optional dependencies
pip install -r requirements/requirements-atari.txt
pip install -r requirements/requirements-mujoco.txt
pip install -r requirements/requirements-mujoco_py.txt
pip install -r requirements/requirements-procgen.txt
pip install -r requirements/requirements-envpool.txt
pip install -r requirements/requirements-pettingzoo.txt
pip install -r requirements/requirements-jax.txt
pip install -r requirements/requirements-docs.txt
pip install -r requirements/requirements-cloud.txt
pip install -r requirements/requirements-memory_gym.txt다른 게임에서 훈련 스크립트를 실행하려면:
poetry shell
# classic control
python cleanrl/dqn.py --env-id CartPole-v1
python cleanrl/ppo.py --env-id CartPole-v1
python cleanrl/c51.py --env-id CartPole-v1
# atari
poetry install -E atari
python cleanrl/dqn_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/c51_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/ppo_atari.py --env-id BreakoutNoFrameskip-v4
python cleanrl/sac_atari.py --env-id BreakoutNoFrameskip-v4
# NEW: 3-4x side-effects free speed up with envpool's atari (only available to linux)
poetry install -E envpool
python cleanrl/ppo_atari_envpool.py --env-id BreakoutNoFrameskip-v4
# Learn Pong-v5 in ~5-10 mins
# Side effects such as lower sample efficiency might occur
poetry run python ppo_atari_envpool.py --clip-coef=0.2 --num-envs=16 --num-minibatches=8 --num-steps=128 --update-epochs=3
# procgen
poetry install -E procgen
python cleanrl/ppo_procgen.py --env-id starpilot
python cleanrl/ppg_procgen.py --env-id starpilot
# ppo + lstm
poetry install -E atari
python cleanrl/ppo_atari_lstm.py --env-id BreakoutNoFrameskip-v4
Gitpod에서 호스팅되는 사전 구축된 개발 환경을 사용할 수도 있습니다.
| 연산 | 구현된 변형 |
|---|---|
| ✅ 근위 정책 그라데이션(PPO) | ppo.py , 문서 |
ppo_atari.py , 문서 | |
ppo_continuous_action.py , 문서 | |
ppo_atari_lstm.py , 문서 | |
ppo_atari_envpool.py , 문서 | |
ppo_atari_envpool_xla_jax.py , 문서 | |
ppo_atari_envpool_xla_jax_scan.py , 문서) | |
ppo_procgen.py , 문서 | |
ppo_atari_multigpu.py , 문서 | |
ppo_pettingzoo_ma_atari.py , 문서 | |
ppo_continuous_action_isaacgym.py , 문서 | |
ppo_trxl.py , 문서 | |
| ✅ 심층 Q 학습(DQN) | dqn.py , 문서 |
dqn_atari.py , 문서 | |
dqn_jax.py , 문서 | |
dqn_atari_jax.py , 문서 | |
| ✅ 범주형 DQN (C51) | c51.py , 문서 |
c51_atari.py , 문서 | |
c51_jax.py , 문서 | |
c51_atari_jax.py , 문서 | |
| ✅ 소프트 배우 비평가(SAC) | sac_continuous_action.py , 문서 |
sac_atari.py , 문서 | |
| ✅ 심층 결정론적 정책 그라데이션(DDPG) | ddpg_continuous_action.py , 문서 |
ddpg_continuous_action_jax.py , 문서 | |
| ✅ 트윈 지연 심층 결정론적 정책 변화도(TD3) | td3_continuous_action.py , 문서 |
td3_continuous_action_jax.py , 문서 | |
| ✅ PPG(단계적 정책 변화도) | ppg_procgen.py , 문서 |
| ✅ 무작위 네트워크 증류(RND) | ppo_rnd_envpool.py , 문서 |
| ✅ Q단검 | qdagger_dqn_atari_impalacnn.py , 문서 |
qdagger_dqn_atari_jax_impalacnn.py , 문서 |
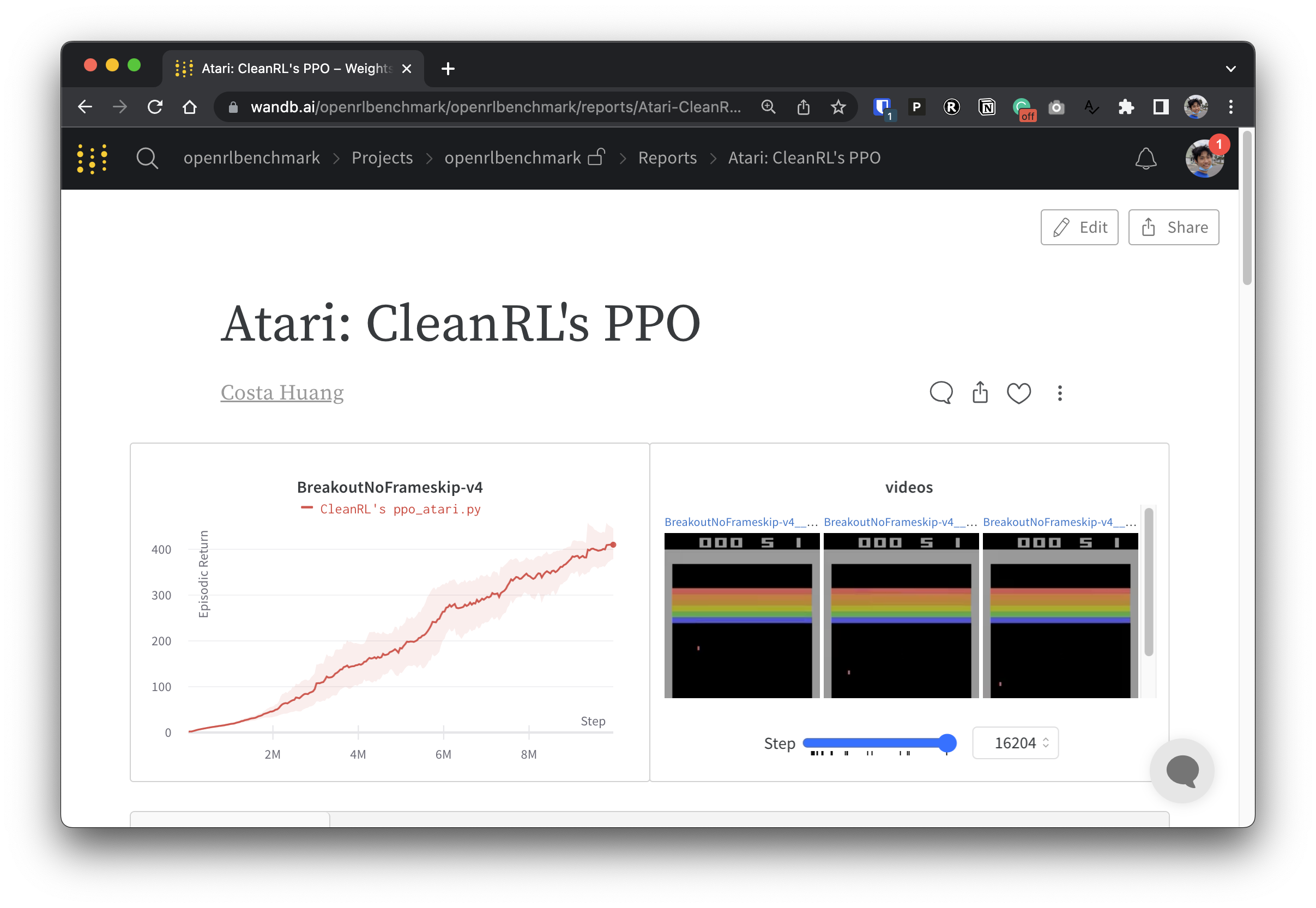
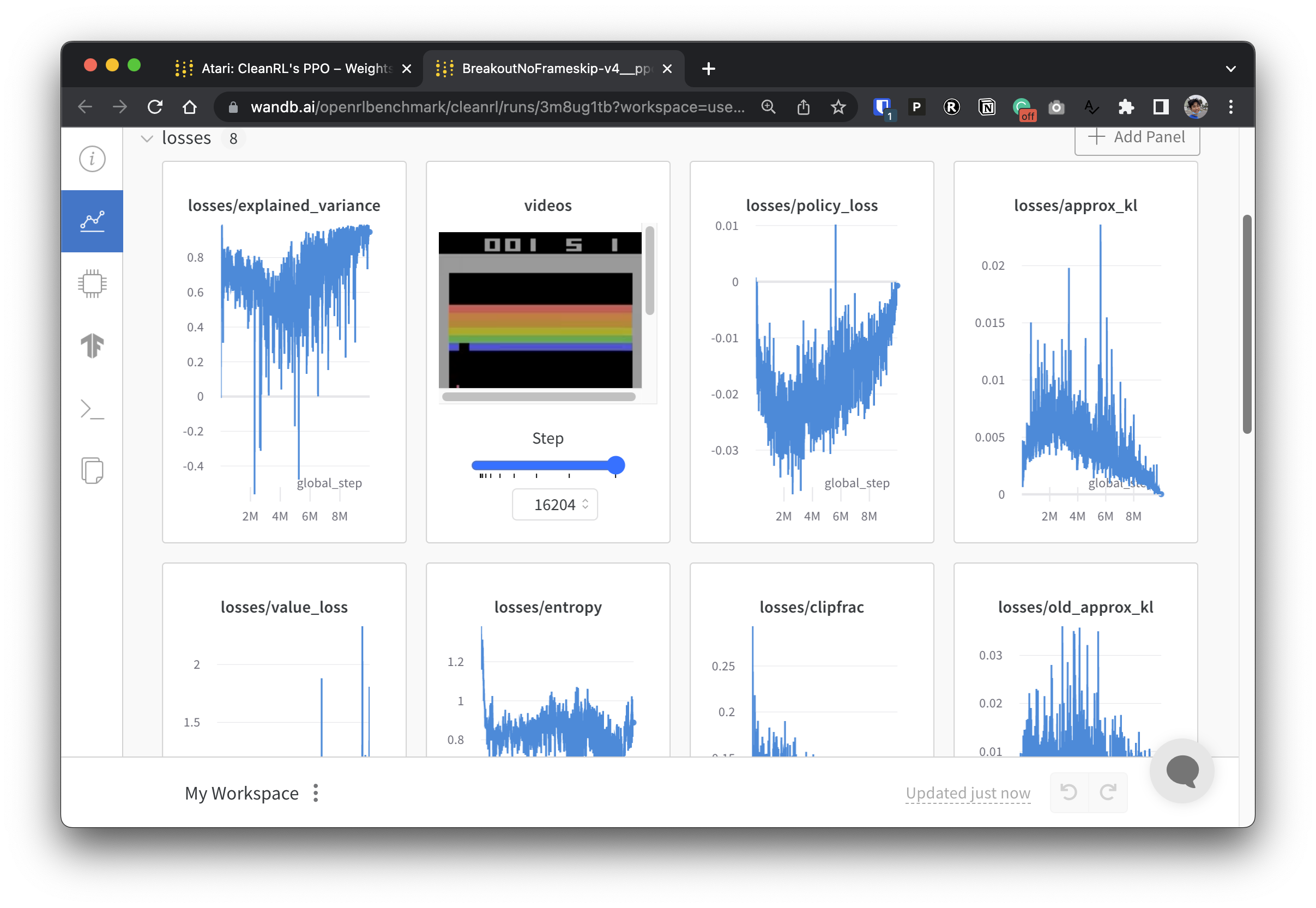
실험 데이터를 투명하게 만들기 위해 CleanRL은 Open RL Benchmark라는 관련 프로젝트에 참여합니다. 이 프로젝트에는 Stable-baselines3, openai/baselines, jaxrl 등과 같은 인기 있는 DRL 라이브러리에서 추적된 실험이 포함되어 있습니다.
추적된 DRL 실험을 보여주는 가중치 및 편향 보고서 모음을 보려면 https://benchmark.cleanrl.dev/를 확인하세요. 보고서는 대화형이므로 연구원은 일반적으로 다른 RL 벤치마크에서 얻기 어려운 GPU 사용률 및 에이전트 게임 플레이 비디오와 같은 정보를 쉽게 쿼리할 수 있습니다. 앞으로 Open RL Benchmark는 연구자가 데이터에 쉽게 액세스할 수 있도록 데이터 세트 API를 제공할 것입니다(저장소 참조).
지원을 위한 Discord 커뮤니티가 있습니다. 자유롭게 질문하세요. Github 이슈 및 PR에 게시하는 것도 환영합니다. 또한 우리의 과거 비디오 녹화물은 YouTube에서 볼 수 있습니다
작업에 CleanRL을 사용하는 경우 기술 문서를 인용해 주세요.
@article { huang2022cleanrl ,
author = { Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo } ,
title = { CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms } ,
journal = { Journal of Machine Learning Research } ,
year = { 2022 } ,
volume = { 23 } ,
number = { 274 } ,
pages = { 1--18 } ,
url = { http://jmlr.org/papers/v23/21-1342.html }
}CleanRL은 프로젝트 기반 커뮤니티이며 기여자들은 다양한 하드웨어에서 실험을 실행합니다.


