3DDFA
1.0.0
지안주 궈 지음.

[업데이트]
2022.5.14 : 얼굴 프로파일링의 Python 구현을 권장합니다:face_pose_augmentation.2020.8.30 : ECCV-20의 사전 훈련된 모델과 코드가 3DDFA_V2에서 공개되고 저작권은 Jianzhu Guo 및 CBSR 그룹에서 설명합니다.2020.8.2 : 이 프로젝트의 간단한 C++ 포트를 업데이트합니다.2020.7.3 : 빠르고 정확하며 안정적인 3D Dense Face Alignment를 향한 확장 작업이 ECCV 2020에서 승인되었습니다. 자세한 내용은 내 페이지를 참조하세요.2019.9.15 : 일부 업데이트, 자세한 내용은 커밋을 참조하세요.2019.6.17 : zjjMaiMai가 제공한 비디오 데모를 추가합니다.2019.5.2 : PyTorch v1.1.0을 사용하여 CPU에서 추론 속도를 평가합니다. 여기 및 speed_cpu.py를 참조하세요.2019.4.27 : ~25ms/프레임(720p)에서 실행되는 간단한 렌더 파이프라인. 자세한 내용은 render.py를 참조하세요.2019.4.24 : 오바마의 데모 구축 제공, 자세한 내용은 데모@obama/readme.md를 참조하세요.2019.3.28 : 일부 업데이트.2018.12.23 : 깊이 영상 추정, PNCC, PAF 기능, obj 직렬화 등 여러 기능을 추가했습니다. 자세한 내용은 dump_depth , dump_pncc , dump_paf , dump_obj 옵션을 참조하세요.2018.12.2 : 랜드마크 없는 얼굴 자르기를 지원합니다. dlib_landmark 옵션을 참조하세요.2018.12.1 : 코드 개선 및 포즈 추정 기능 추가. 자세한 내용은 utils/estimate_pose.py를 참조하세요.2018.11.17 : 코드를 개선하고 3D 정점을 원본 이미지 공간에 매핑합니다.2018.11.11 : 엔드투엔드 추론 파이프라인 업데이트: 하나의 임의 이미지가 제공된 경우 3D 얼굴 모양과 68개의 랜드마크를 추론/직렬화합니다. 자세한 내용은 아래 readme.md를 참조하세요.2018.10.4 : 시각화에 Matlab 페이스 메시 렌더링 데모를 추가했습니다.2018.9.9 : 벤치마크에 얼굴 자르기 전처리 추가.[토도]
이 저장소에는 pytorch 개선된 버전의 논문인 전체 포즈 범위의 얼굴 정렬: 3D 전체 솔루션이 포함되어 있습니다. 실시간 훈련, 훈련 전략을 포함하여 원본 논문 이상의 여러 작품이 추가됩니다. 따라서 이 저장소는 원본 작업의 개선된 버전입니다. 지금까지 이 저장소는 MobileNet-V1 구조의 사전 훈련된 1단계 pytorch 모델, 사전 처리된 훈련 및 테스트 데이터세트 및 코드베이스를 출시합니다. 추론 시간은 GeForce GTX TITAN X에서 이미지(입력 배치로 128개의 이미지가 포함된 입력 배치)당 약 0.27ms 입니다.
이 레포는 여가 시간에 계속 업데이트될 예정이며, 의미 있는 문제와 PR을 환영합니다.
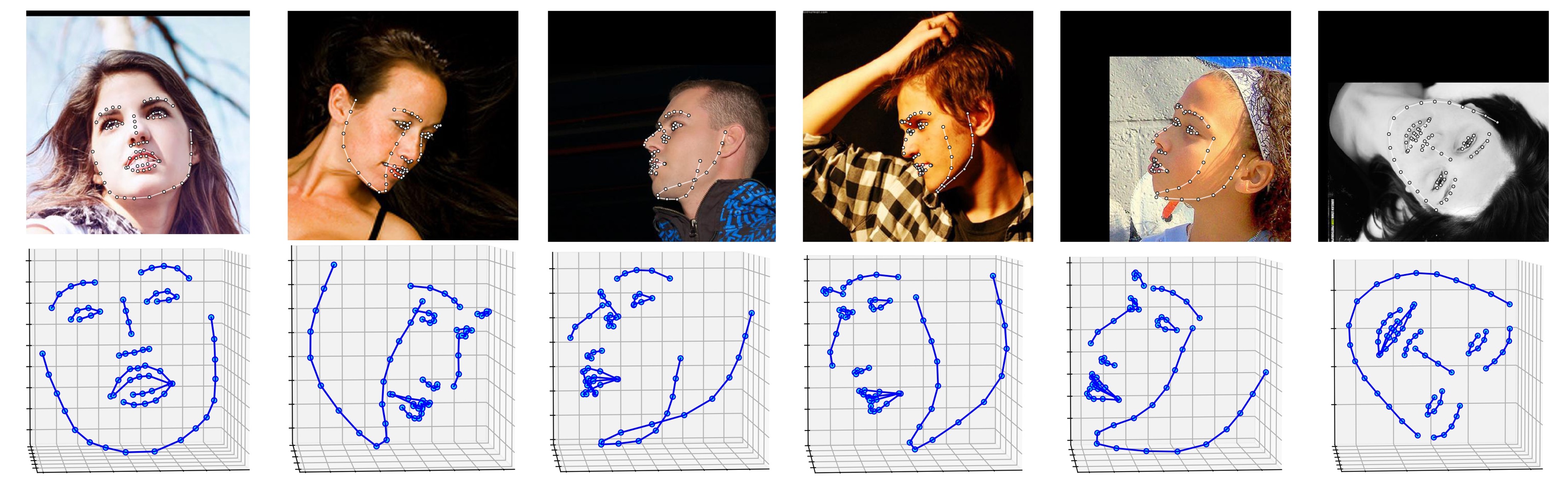
ALFW-2000 데이터 세트( phase1_wpdc_vdc.pth.tar 모델에서 추론됨)에 대한 여러 결과가 아래에 표시되어 있습니다.





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
또한 더 나은 디자인을 위해 이전 버전 대신 Python3.6+를 사용하는 것이 좋습니다.
이 저장소를 복제합니다(조금 크기 때문에 시간이 걸릴 수 있음).
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
그런 다음 Google Drive 또는 Baidu Yun에서 dlib 랜드마크 사전 학습된 모델을 다운로드하여 models 디렉터리에 넣습니다. (이 repo의 크기를 줄이기 위해 이 모델을 포함한 일부 대용량 바이너리 파일을 제거하였으므로 다운로드 받으시기 바랍니다 :) )
Cython 모듈 빌드(빌딩을 위해 한 줄만 사용)
cd utils/cython
python3 setup.py build_ext -i
이는 Python이 for 루프에서 너무 느리기 때문에 깊이 추정 및 PNCC 렌더링을 가속화하기 위한 것입니다.
임의의 이미지를 입력으로 사용하여 main.py 실행합니다.
python3 main.py -f samples/test1.jpg
터미널에서 이러한 출력 로그를 볼 수 있으면 성공적으로 실행한 것입니다.
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
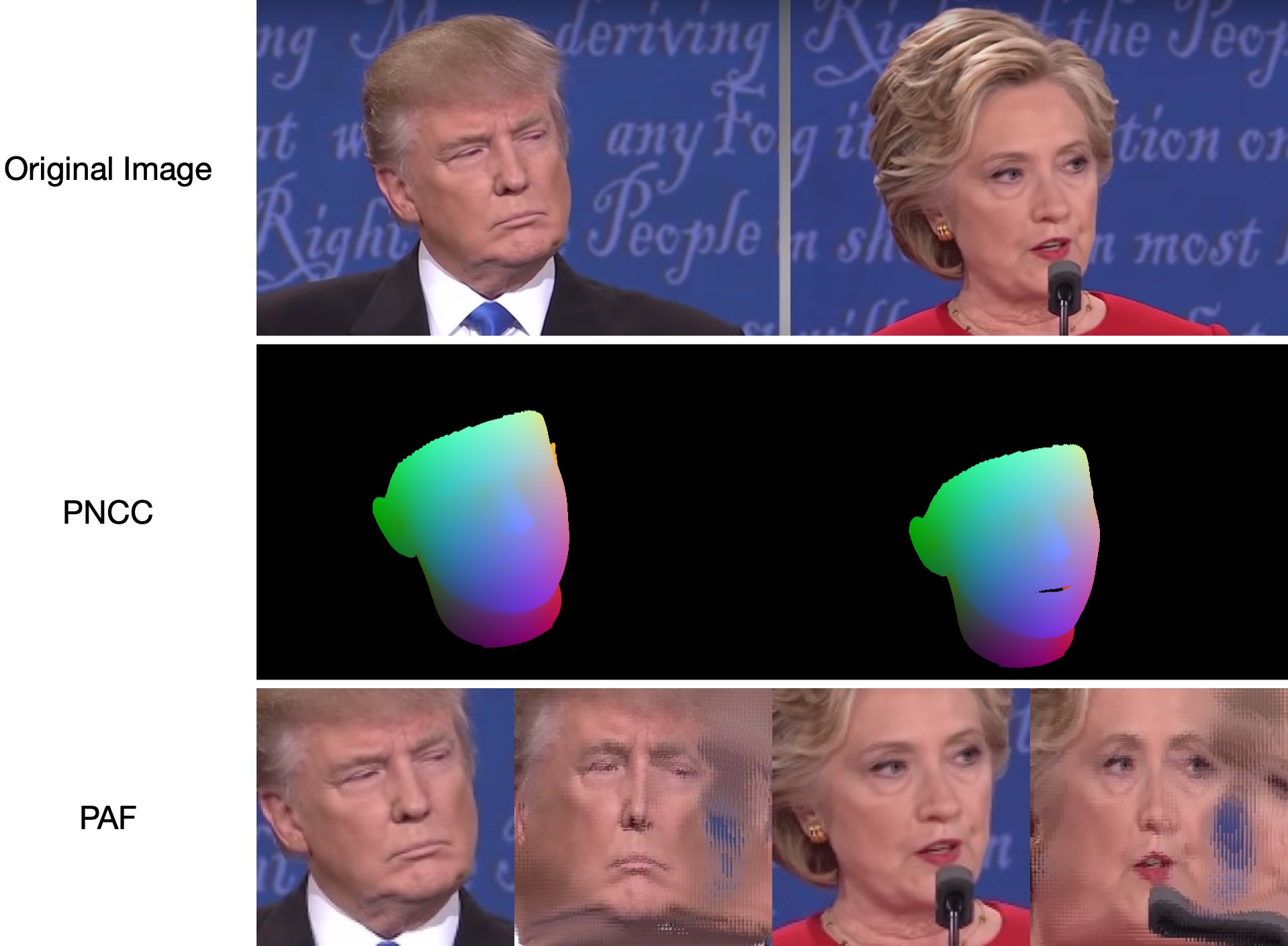
test1.jpg 에는 두 개의 면이 있으므로 두 개의 .ply 및 .obj 파일(Meshlab 또는 Microsoft 3D Builder로 렌더링 가능)이 예측됩니다. 깊이, PNCC, PAF 및 포즈 추정은 모두 기본적으로 true로 설정됩니다. 자세한 내용은 python3 main.py -h 실행하거나 코드를 검토하세요.
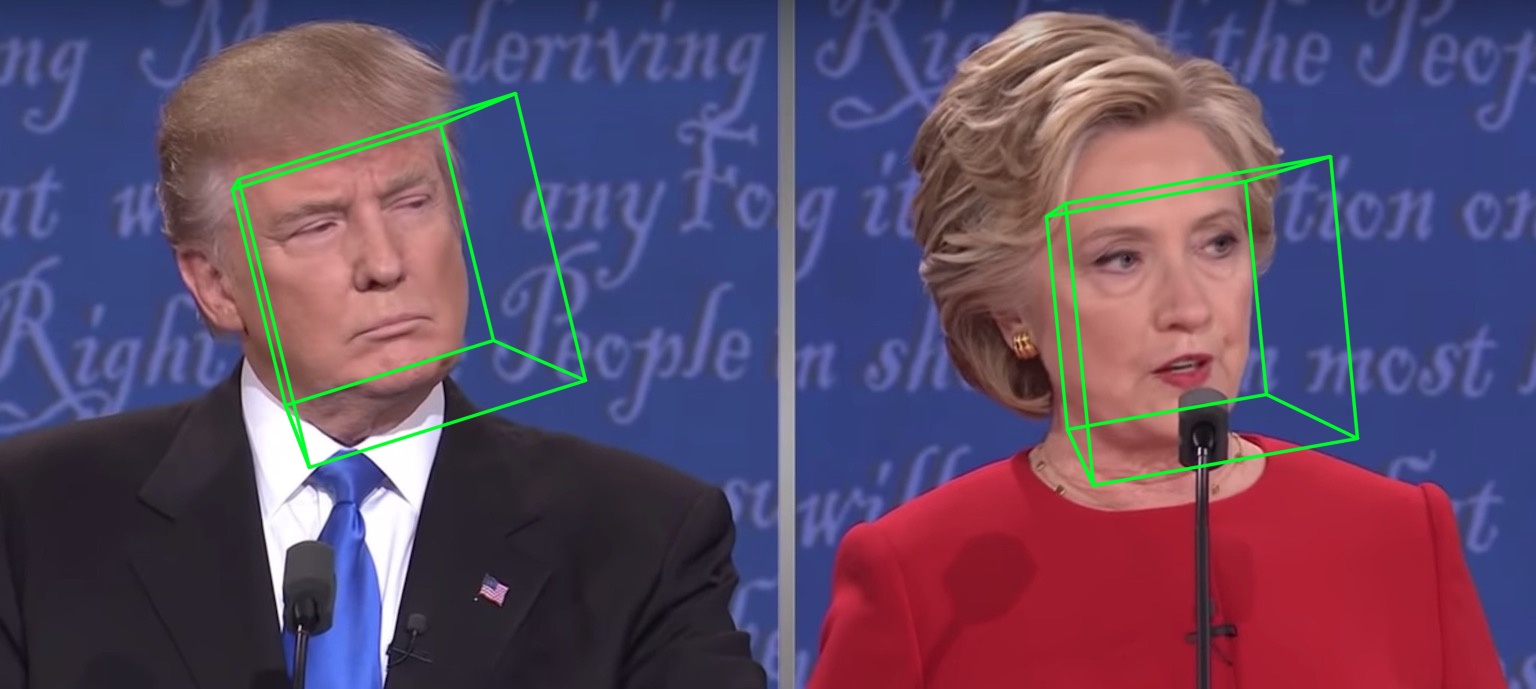
68개의 랜드마크 시각화 결과 samples/test1_3DDFA.jpg 및 자세 추정 결과 samples/test1_pose.jpg 다음과 같습니다.

추가 예
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
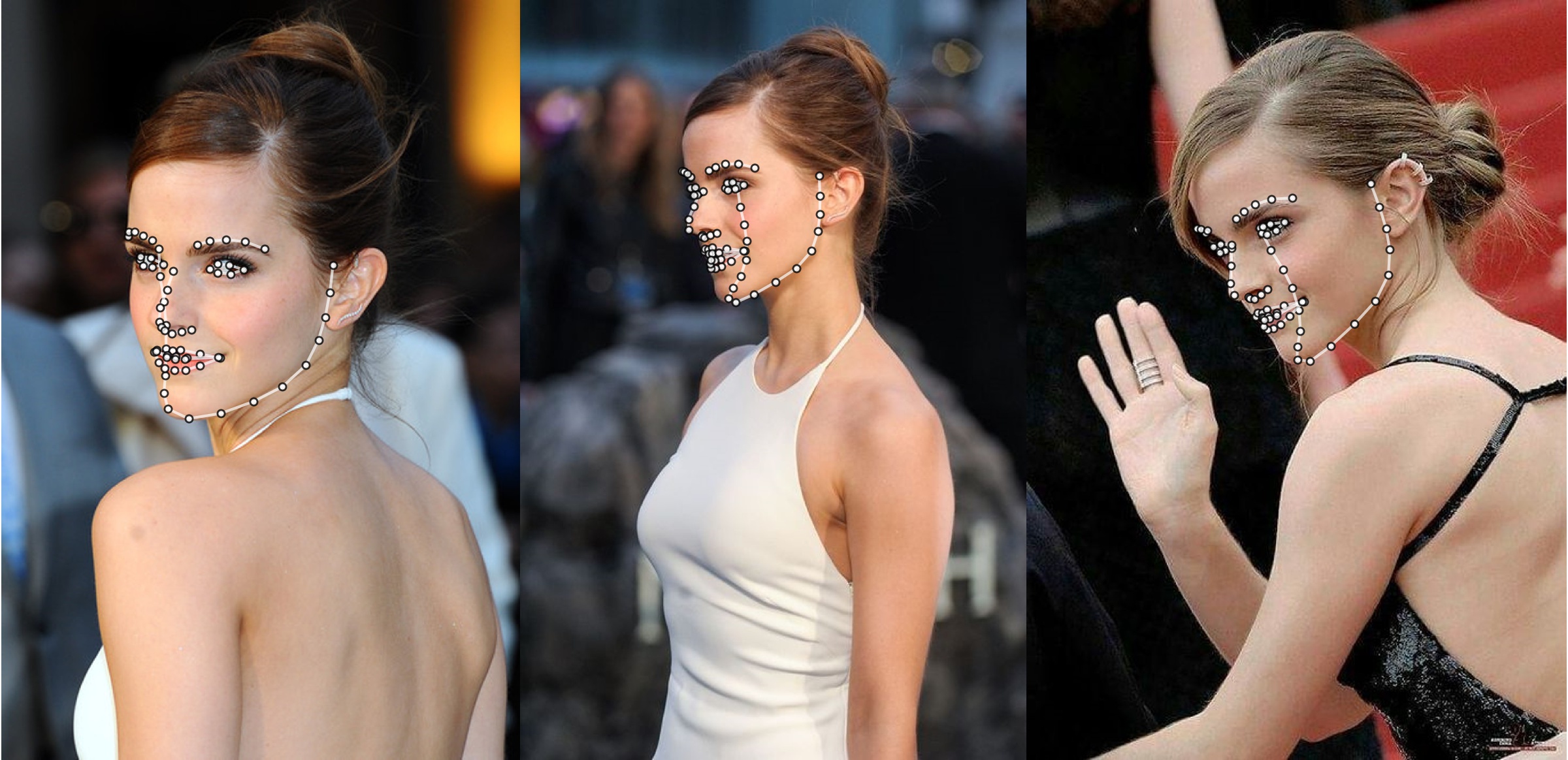
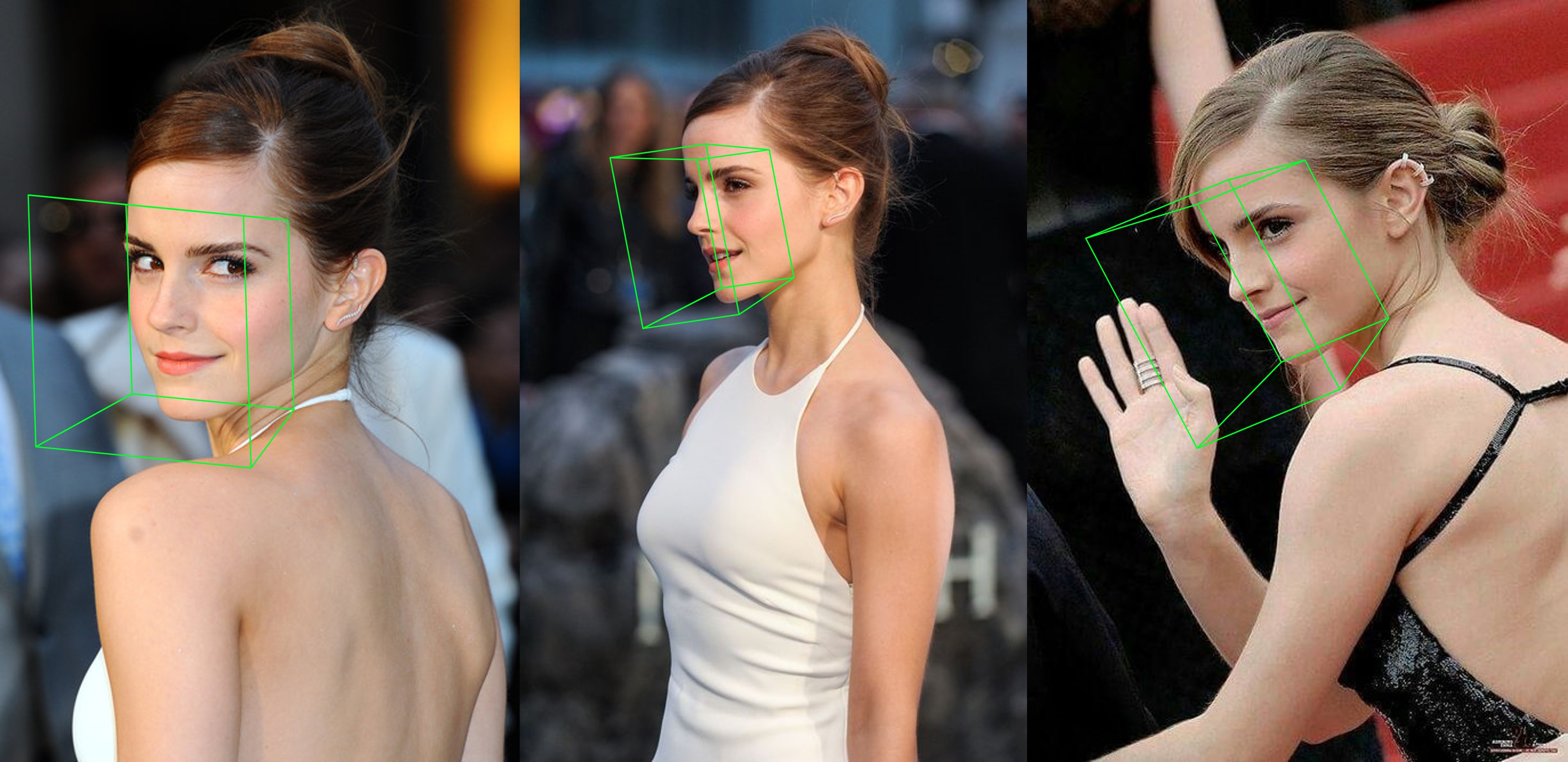
그냥 실행
python3 speed_cpu.py
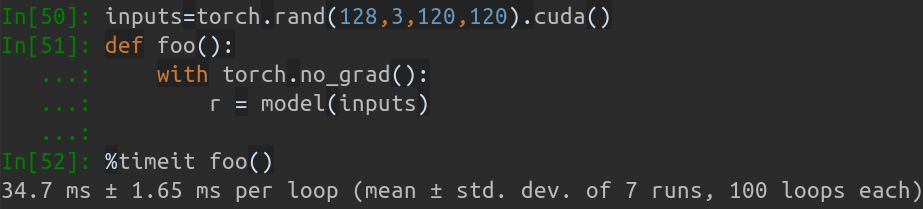
내 MBP(13인치 MacBook Pro의 i5-8259U CPU @ 2.30GHz)에서 PyTorch v1.1.0을 기반으로 단일 입력을 사용하면 실행 출력은 다음과 같습니다.
Inference speed: 14.50±0.11 ms
입력 배치 크기가 128일 때 MobileNet-V1의 총 추론 시간은 약 34.7ms가 소요됩니다. 평균 속도는 약 0.27ms/pic 입니다.
훈련 스크립트는 training 디렉토리에 있습니다. 관련 자료는 아래 표와 같습니다.
| 데이터 | 다운로드 링크 | 설명 |
|---|---|---|
| 열차.구성 | BaiduYun 또는 Google 드라이브, 217M | 3DMM 매개변수와 훈련 데이터 세트의 파일 목록이 포함된 디렉터리 |
| train_aug_120x120.zip | BaiduYun 또는 Google 드라이브, 2.15G | 증강 훈련 데이터 세트의 자른 이미지 |
| 테스트.데이터.zip | BaiduYun 또는 Google 드라이브, 151M | AFLW 및 ALFW-2000-3D 테스트 세트의 잘린 이미지 |
훈련 데이터 세트와 구성 파일을 준비한 후 training 디렉터리로 이동하여 bash 스크립트를 실행하여 훈련합니다. train_wpdc.sh , train_vdc.sh 및 train_pdc.sh 는 훈련 스크립트의 예입니다. 학습 및 테스트 세트를 구성한 후 학습을 위해 실행하면 됩니다. 예를 들어 아래와 같이 train_wpdc.sh 사용합니다.
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
학습률, 미니 배치 크기, 에포크 등을 포함한 특정 훈련 매개변수는 모두 bash 스크립트에 표시됩니다.
먼저 test.data.zip에서 잘라낸 테스트 세트 ALFW 및 ALFW-2000-3D를 다운로드한 다음 압축을 풀고 루트 디렉터리에 넣어야 합니다. 다음으로 훈련된 모델 경로를 제공하여 벤치마크 코드를 실행합니다. 나는 이미 models 디렉토리에 5개의 사전 훈련된 모델을 제공했습니다(아래 표 참조). 이 모델은 첫 번째 단계에서 다양한 손실을 사용하여 학습됩니다. MobileNet-V1 구조의 높은 효율성으로 인해 모델 크기는 약 13M입니다.
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
사전 훈련된 모델의 성능은 아래와 같습니다. 첫 번째 단계에서는 다양한 손실의 효율성이 순서대로 나타납니다: WPDC > VDC > PDC. WPDC를 미세 조정하기 위해 VDC를 사용하는 전략이 최상의 결과를 달성합니다.
| 모델 | AFLW (21점) | AFLW 2000-3D (68점) | 다운로드 링크 |
|---|---|---|---|
| Phase1_pdc.pth.tar | 6.956±0.981 | 5.644±1.323 | Baidu Yun 또는 Google 드라이브 |
| Phase1_vdc.pth.tar | 6.717±0.924 | 5.030±1.044 | Baidu Yun 또는 Google 드라이브 |
| Phase1_wpdc.pth.tar | 6.348±0.929 | 4.759±0.996 | Baidu Yun 또는 Google 드라이브 |
| Phase1_wpdc_vdc.pth.tar | 5.401±0.754 | 4.252±0.976 | 이 저장소에서. |
이 저장소의 프레임워크는 계산 예산을 늘리지 않고도 PRNet보다 더 나은 성능을 달성할 수 있다고 믿습니다. 관련 작업이 검토 중이며 승인되면 코드가 공개됩니다.
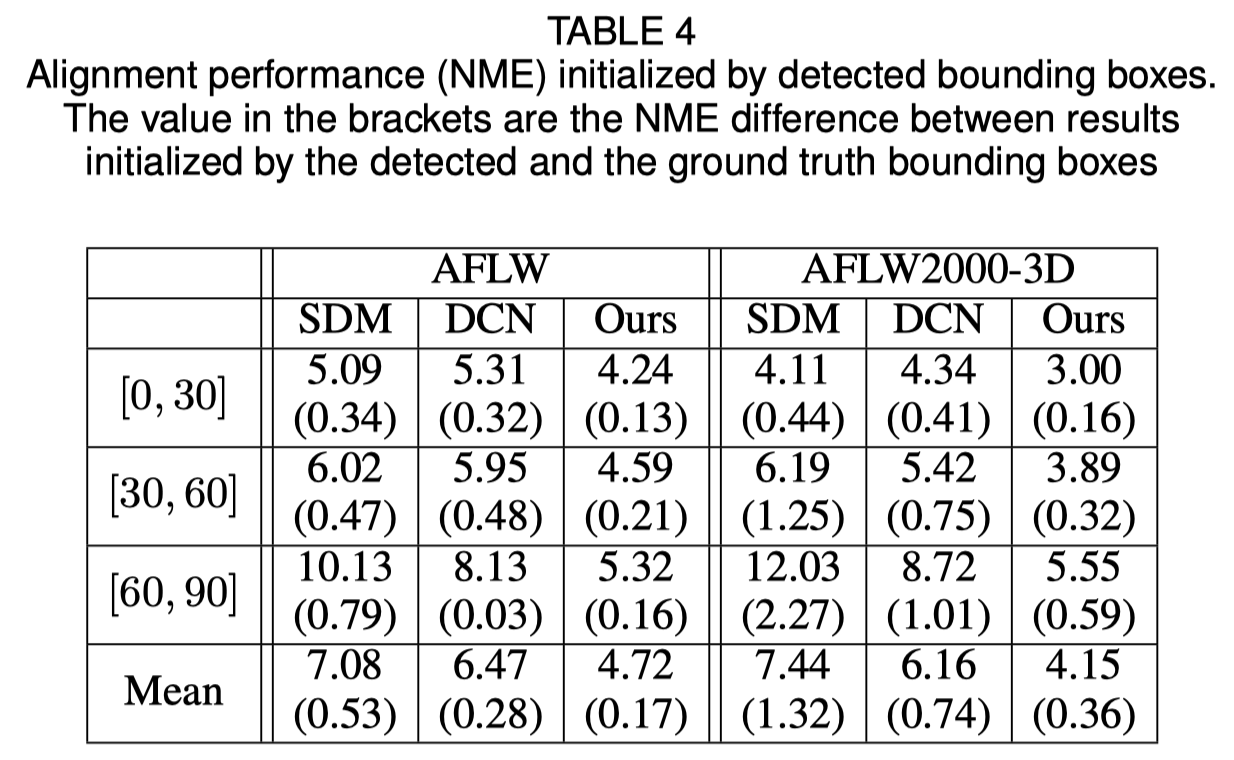
면 경계 상자 초기화
원본 논문에서는 Ground Truth 상자 대신 감지된 경계 상자를 사용하면 성능이 약간 저하될 수 있음을 보여줍니다. 따라서 현재의 얼굴 자르기 방법이 가장 강력합니다. 정량적 결과는 아래 표에 나와 있습니다.
얼굴 재구성
보이지 않는 영역의 질감은 자체 폐색으로 인해 왜곡되어 보이지 않는 얼굴 영역이 이상하게(약간 끔찍하게) 보일 수 있습니다.
모양 및 표현 매개변수 클리핑 정보
매개변수 클리핑은 훈련 및 재구성을 가속화하지만 특히 눈을 감는 것과 같은 세부 사항의 정확도를 저하시킵니다. 아래는 매개변수 크기가 40+10, 60+29 및 199+29(원본)인 이미지입니다. 모양에 비해 표정 클리핑은 감정이 포함될 때 재구성 정확도에 더 많은 영향을 미칩니다. 따라서 속도/매개변수 크기와 정확도 사이에서 절충점을 선택할 수 있습니다. 클리핑 트레이드 오프의 권장 사항은 60+29입니다.

이 저장소에 관심을 가져주셔서 감사합니다. 귀하의 작업이나 연구가 이 저장소로부터 이익을 얻는다면 별표를 표시해 주세요.
3D 얼굴 관련 작업인 MeGlass 및 Face Anti-Spoofing에 집중해 주셔서 감사합니다.
귀하의 업무가 이 저장소로부터 이익을 얻는다면 아래에 세 가지 턱받이를 인용해 주십시오.
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo(郭建珠) [홈페이지, Google 학술검색]: [email protected] 또는 [email protected] .


