similarity
1.1.6
유사성, 텍스트 문자열 간의 유사성 점수 계산, Java 작성.
유사성 계산 툴킷인 유사성은 Java로 작성된 텍스트 유사성 계산, 감정 분석 등에 사용할 수 있습니다.
유사성은 일련의 알고리즘으로 구성된 Java 버전의 유사성 계산 툴킷으로, 유사성 계산 방법을 자연어 처리에 확산시키는 것이 목표입니다. 유사성은 실용적인 도구, 효율적인 성능, 명확한 구조, 최신 코퍼스 및 사용자 정의 가능성의 특성을 갖습니다.
유사성은 다음 기능을 제공합니다.
단어 유사성 계산
구문 유사성 계산
문장 유사성 계산
단락 유사성 계산
CNKI 이위안
감정 분석
대략적인 단어
풍부한 기능을 제공하는 동시에 유사성 내부 모듈은 낮은 결합을 요구하고, 모델은 지연 로딩을 요구하며, 사전은 일반 텍스트로 게시를 요구합니다. 이들은 사용하기 쉽고 사용자가 자신의 말뭉치를 훈련하는 데 도움이 됩니다.
Jar 패키지 소개
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Gradle 소개:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}텍스트 길이: 단어 세분성
Cilin 유사성: org.xm.Similarity.cilinSimilarity 사용하는 것이 좋습니다 . 이는 Cilin 동의어를 기반으로 한 유사성 계산 방법입니다.
예: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
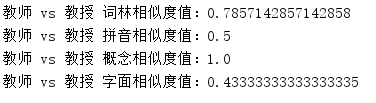
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
텍스트 길이: 구문 세분성
구문 유사성( org.xm.Similarity.phraseSimilarity 사용하는 것이 좋습니다. 이는 본질적으로 동일한 문자와 동일한 문자의 위치를 통해 두 구문의 유사성을 계산하는 방법입니다.
예: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
텍스트 길이: 문장 세분성
단어 형식 및 단어 순서 문장 유사성을 사용하는 것이 좋습니다 : org.xm.similarity.morphoSimilarity , 두 문장의 동일한 텍스트 리터럴을 고려할 뿐만 아니라 동일한 텍스트가 나타나는 순서도 고려하는 유사성 방법입니다.
예: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
텍스트 길이: 단락 단위(단락, 25자 < 길이(텍스트) < 500자)
단어 형식의 단어 순서 문장 유사성( org.xm.similarity.text.CosineSimilarity 사용하는 것이 좋습니다. 두 문단의 동일한 텍스트를 고려하여 단어 분할, 단어 빈도 및 품사 가중치를 통해 가중치를 부여하는 방법입니다. 유사도를 계산하기 위해 코사인을 사용합니다.
예: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875예: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}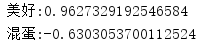
이 예는 sememe tree를 기반으로 한 단어 세분화된 감정 극성 분석으로, 더 나은 결과를 얻기 위해 심층 신경망 모델과 SVM 분류 알고리즘을 사용하는 pytextclassifier가 있습니다.
예: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

Word2vec 단어 벡터 훈련은 word2vec 훈련 도구 Word2VEC_java의 Java 버전입니다. 훈련 코퍼스는 소설 Tian Long Ba Bu이며 동의어는 단어 벡터를 통해 얻습니다. 사용자는 사용자 정의 코퍼스를 훈련하거나 중국어 Wikipedia를 사용하여 범용 단어 벡터를 훈련할 수 있습니다.
텍스트 유사성 측정

라이센스 계약은 상업용으로 무료로 제공되는 Apache 라이센스 2.0입니다. 제품 설명에 유사성 링크와 라이선스 계약을 첨부하세요.
프로젝트 코드는 아직 매우 미숙합니다. 코드에 개선 사항이 있으면 제출하기 전에 다음 두 가지 사항에 주의하시기 바랍니다.
test 에 해당 단위 테스트를 추가하세요.그런 다음 PR을 제출할 수 있습니다.


