cherche
2.2.1
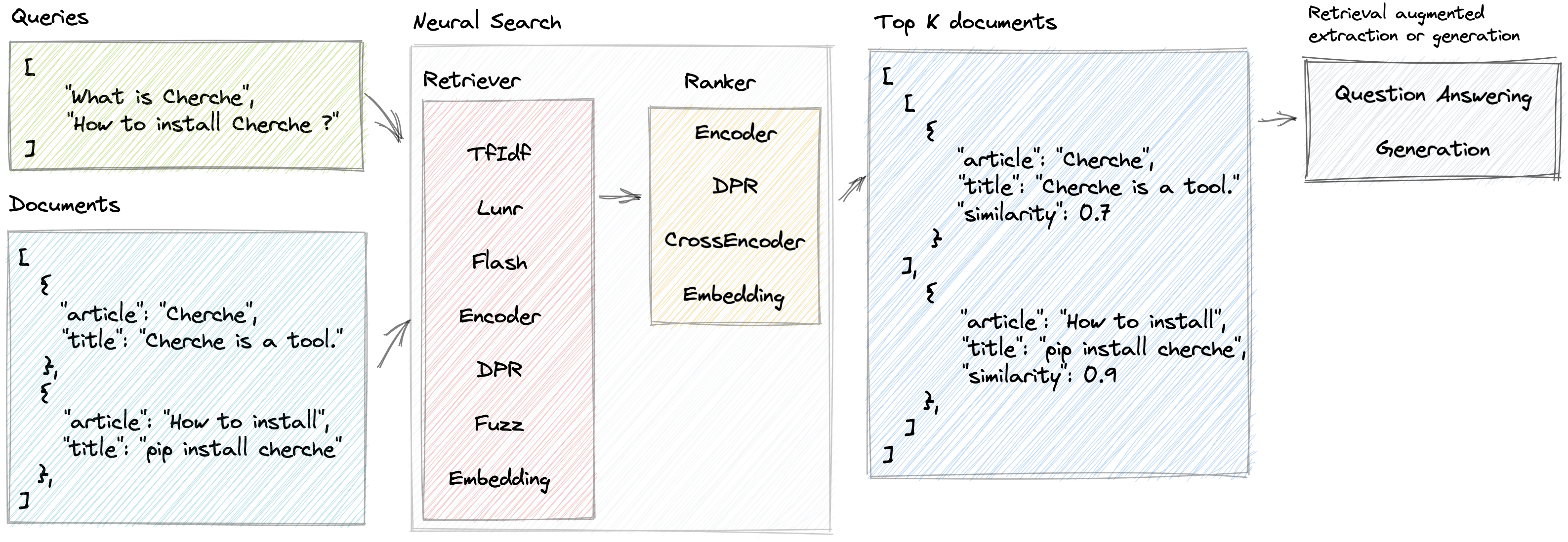
신경 검색

Cherche를 사용하면 검색기와 사전 훈련된 언어 모델을 검색기와 순위 지정자 모두로 사용하는 신경 검색 파이프라인을 개발할 수 있습니다. Cherche의 주요 장점은 엔드투엔드 파이프라인을 구성할 수 있는 능력에 있습니다. 또한 Cherche는 일괄 계산과의 호환성으로 인해 오프라인 의미 검색에 적합합니다.
Cherche가 제공하는 일부 기능은 다음과 같습니다.
Cherche가 제공하는 NLP 검색 엔진의 라이브 데모
TfIdf, Flash, Lunr, Fuzz와 같은 CPU의 단순 검색기와 함께 사용하기 위해 Cherche를 설치하려면 다음 명령을 사용하십시오.
pip install chercheCPU의 의미 검색기 또는 랭커와 함께 사용하기 위해 Cherche를 설치하려면 다음 명령을 사용하십시오.
pip install " cherche[cpu] "마지막으로 GPU에서 의미 검색기나 랭커를 사용하려는 경우 다음 명령을 사용하세요.
pip install " cherche[gpu] "이 설치 지침을 따르면 귀하의 필요에 맞는 적절한 요구 사항에 따라 Cherche를 사용할 수 있습니다.
문서는 여기에서 확인할 수 있습니다. 검색기, 랭커, 파이프라인 및 예제에 대한 세부 정보를 제공합니다.
Cherche를 사용하면 개체 목록 내에서 올바른 문서를 찾을 수 있습니다. 다음은 말뭉치의 예입니다.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]다음은 문서를 빠르게 검색하는 TF-IDF와 순위 모델로 구성된 신경 검색 파이프라인의 예입니다. 순위 모델은 쿼리와 문서 간의 의미적 유사성을 기반으로 검색기가 생성한 문서를 정렬합니다. 쿼리 목록을 사용하여 파이프라인을 호출하고 각 쿼리에 대한 관련 문서를 가져올 수 있습니다.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]파이프라인을 사용하여 문서의 내용에 액세스하기 위해 인덱스를 문서에 매핑할 수 있습니다.
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche는 쿼리를 기반으로 입력 문서를 필터링하는 검색기를 제공합니다.
Cherche는 검색기 출력에서 문서를 필터링하는 순위를 제공합니다.
Cherche 랭커는 Hugging Face 허브에서 사용할 수 있는 SentenceTransformers 모델과 호환됩니다.
Cherche는 질문 답변 전용 모듈을 제공합니다. 이 모듈은 Hugging Face의 사전 훈련된 모델과 호환되며 신경 검색 파이프라인에 완전히 통합됩니다.
Cherche는 르노를 위해/르노에 의해 만들어졌으며 이제 모두가 사용할 수 있습니다. 우리는 모든 기여를 환영합니다.

Lunr 검색기는 Lunr.py를 둘러싼 래퍼입니다. 플래시 검색기는 FlashText를 둘러싼 래퍼입니다. DPR, Encode 및 CrossEncoder 랭커는 신경 검색 파이프라인에서 SentenceTransformers의 사전 훈련된 모델을 사용하는 전용 래퍼입니다.
cherche를 사용하여 과학 출판물에 대한 결과를 생성하는 경우 SIGIR 논문을 참조하세요.
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}Cherche 개발팀은 Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero, Jose G Moreno로 구성되어 있습니다. ?


