full stack on prem cv mlops
1.0.0
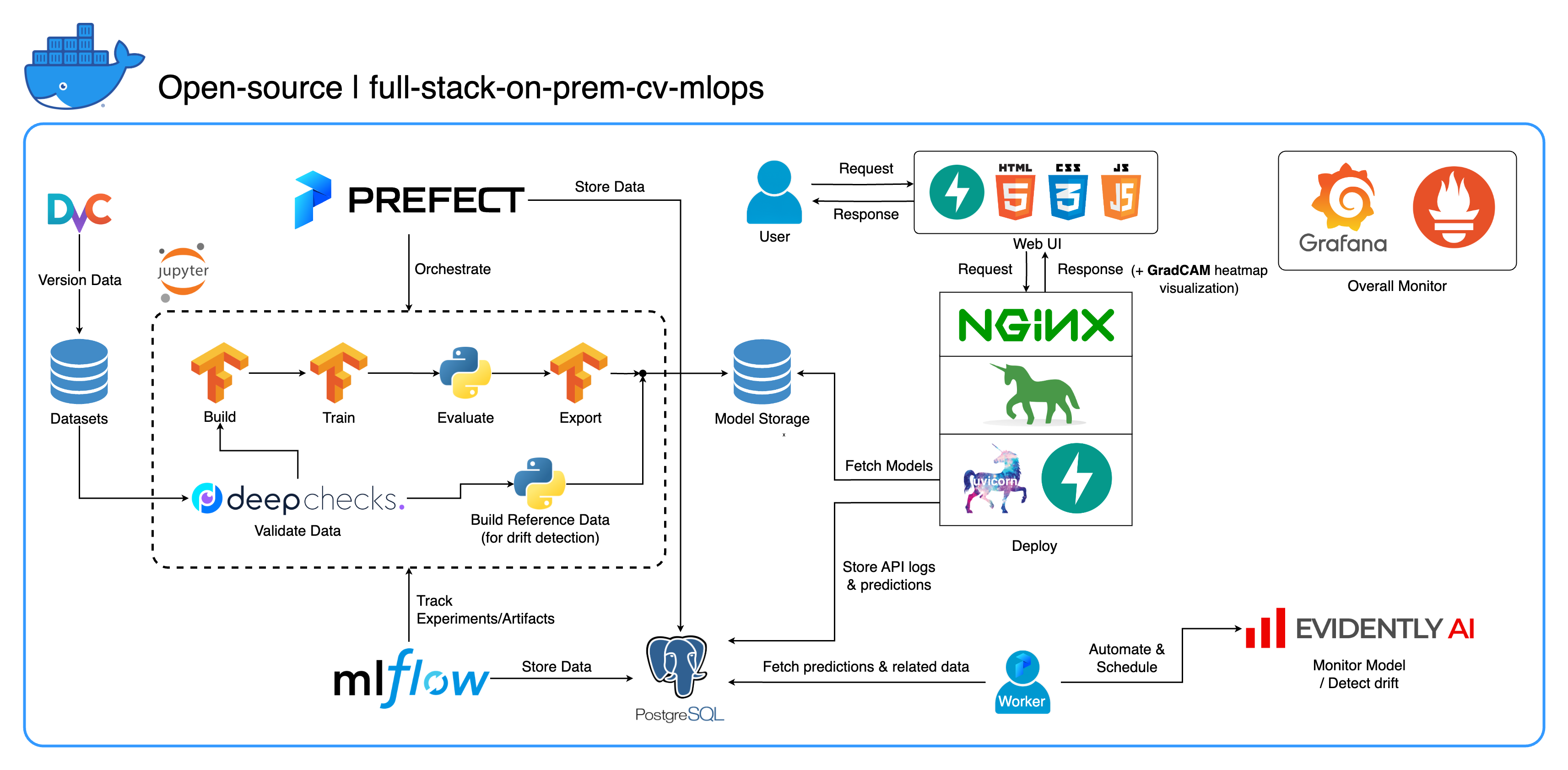
이미지 분류에 중점을 두고 컴퓨터 비전 작업을 위해 특별히 설계된 포괄적인 온프레미스 MLOps 에코시스템에 오신 것을 환영합니다. 이 리포지토리는 Jupyter Lab/Notebook의 개발 작업 공간부터 프로덕션 수준 서비스까지 필요한 모든 것을 갖추고 있습니다. 가장 좋은 부분은? 모델 구축부터 배포까지 전체 시스템을 실행하려면 "1개의 구성과 1개의 명령" 만 필요합니다! 우리는 유연성을 유지하면서 확장성과 안정성을 보장하기 위해 수많은 모범 사례를 통합했습니다. 기본 사용 사례는 이미지 분류를 중심으로 진행되지만 프로젝트 구조는 광범위한 ML/DL 개발에 쉽게 적응할 수 있으며 온프레미스에서 클라우드로 전환할 수도 있습니다!
또 다른 목표는 이러한 모든 도구를 통합하고 하나의 전체 시스템에서 함께 작동하도록 만드는 방법을 보여주는 것입니다. 특정 구성 요소나 도구에 관심이 있다면 프로젝트 요구 사항에 맞는 것을 자유롭게 선택하세요.
전체 시스템은 단일 Docker Compose 파일로 컨테이너화됩니다. 이를 설정하려면 docker-compose up 실행하기만 하면 됩니다! 이는 완전한 온프레미스 시스템이므로 클라우드 계정이 필요하지 않으며 전체 시스템을 사용하는 데 한 푼도 비용이 들지 않습니다 !
포괄적인 개요를 얻고 이 시스템을 프로젝트에 적용하는 방법을 이해하려면 데모 비디오 섹션의 데모 비디오를 시청하는 것이 좋습니다. 이 비디오에는 너무 길고 여기서 다루기에는 명확하지 않을 수 있는 중요한 세부 정보가 포함되어 있습니다.
데모: https://youtu.be/NKil4uzmmQc
심층 기술 연습: https://youtu.be/l1S5tHuGBA8
영상에 나오는 자료:
이 리포지토리를 사용하려면 Docker만 있으면 됩니다. 참고로 우리는 Mac M1에서 Docker 버전 24.0.6, 빌드 ed223bc 및 Docker Compose 버전 v2.21.0-desktop.1을 사용합니다.
우리는 이 프로젝트에서 몇 가지 모범 사례를 구현했습니다.
tf.data 사용하는 효율적인 데이터 로더/파이프라인imgaug lib를 사용한 이미지 보강os.env 사용print 대신 logging 모듈을 사용하여 로깅docker-compose.yml 의 변수에 대해 .env 통한 동적 구성default.conf.template 사용하여 Nginx 구성에서 환경 변수를 우아하게 적용(Nginx 1.19의 새로운 기능)대부분의 포트는 이 저장소 루트에 있는 .env 파일에서 사용자 정의할 수 있습니다. 기본값은 다음과 같습니다.
123456789 )[email protected] , 비밀번호: SuperSecurePwdHere )admin , 비밀번호: admin ) ARM 기반 컴퓨터를 사용하지 않는 경우(우리는 개발을 위해 Mac M1을 사용하고 있습니다) 해당 플랫폼에 대한 주석을 고려해야 합니다: docker-compose.yml 의 platform: linux/arm64 라인. 그렇지 않으면 이 시스템이 작동하지 않을 것입니다.
--recurse-submodules 플래그를 사용하는 것이 좋습니다. git clone --recurse-submodules https://github.com/jomariya23156/full-stack-on-prem-cv-mlopsdocker-compose.yml 의 jupyter 서비스에서 deploy 섹션의 주석 처리를 제거하고 services/jupyter/Dockerfile 의 기본 이미지를 ubuntu:18.04 에서 nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 로 변경할 수 있습니다. nvidia/cuda:11.4.3-cudnn8-devel-ubuntu20.04 (텍스트는 파일에 있으므로 주석을 달고 주석을 제거하면 됩니다) GPU를 활용합니다. 작동하려면 호스트 시스템에 nvidia-container-toolkit 설치해야 할 수도 있습니다. Windows/WSL2 사용자에게는 이 문서가 매우 유용하다고 생각합니다.docker-compose up 또는 docker-compose up -d 실행하여 터미널을 분리합니다.datasets/animals10-dvc 에 있는 DvC 하위 모듈로 이동하여 사용 방법 섹션의 단계를 따르세요. http://localhost:8888/lab 에서 Jupyter 랩을 엽니다.cd ~/workspace/conda activate computer-viz-dl (이름은 docker-compose.yml 에서 구성 가능).python run_flow.py --config configs/full_flow_config.yaml 실행합니다.tasks 디렉터리 내에 생성되어야 합니다.flows 디렉터리 내부에 생성된 흐름에서 호출되어야 합니다.run_flow.py 사용하여 흐름을 호출해야 합니다.start(config) 함수를 구현해야 합니다. 이 함수는 구성을 Python dict로 받아들인 다음 기본적으로 해당 파일의 특정 흐름을 호출합니다.datasets 디렉터리 내에 있어야 하며 모두 이 저장소 내부의 것과 동일한 디렉터리 구조를 가져야 합니다.~/ariya/ 의 central_storage 에는 models 및 ref_data 라는 하위 디렉터리가 2개 이상 포함되어야 합니다. 이 central_storage 개발 및 배포 환경 전반에서 사용할 모든 스테이징된 파일을 저장하는 객체 스토리지 목적으로 사용됩니다. (클라우드에 배포하고 확장성을 높이려는 경우 클라우드 스토리지 서비스로 변경하는 것을 고려할 수 있는 사항 중 하나입니다.)변경하려는 경우 매우 조심해야 하는 중요한 규칙(이러한 사항은 시스템의 다른 부분에서 연결되어 사용되기 때문입니다):
central_storage 경로 -> 내부에는 models/ ref_data/ 하위 디렉터리가 있어야 합니다.<model_name>.yaml , <model_name>_uae , <model_name>_bbsd , <model_name>_ref_data.parquetcurrent_model_metadata_file 및 monitor_pool_name 의 키/이름computer-viz-dl (기본값)이라는 사전 설치된 Conda 환경이 포함되어 있습니다. 모든 Python 명령/코드는 이 Jupyter 내에서 실행되어야 합니다.central_storage 볼륨은 개발 및 배포 전반에 걸쳐 사용되는 중앙 파일 저장소 역할을 합니다. 여기에는 주로 모델 파일(드리프트 감지기 포함)과 Parquet 형식의 참조 데이터가 포함되어 있습니다. 모델 훈련 단계가 끝나면 새 모델이 여기에 저장되고 배포 서비스는 이 위치에서 모델을 가져옵니다. ( 참고 : 확장성을 위해 클라우드 스토리지 서비스로 대체하기에 이상적인 장소입니다.)model 섹션을 사용하세요. 모델은 TensorFlow 로 구축되었으며 해당 아키텍처는 tasks/model.py:build_model 에 하드코딩되어 있습니다.dataset 섹션을 사용하세요. 이 단계에서는 DvC를 사용하여 구성에 지정된 버전과 비교하여 디스크에 있는 데이터의 일관성을 확인합니다. 변경 사항이 있으면 프로그래밍 방식으로 지정된 버전으로 다시 변환합니다. 변경 사항을 유지하려면 데이터 세트를 실험하는 경우 구성의 dvc_checkout 필드를 false 로 설정하여 DvC가 해당 작업을 수행하지 않도록 할 수 있습니다.train 섹션을 사용하십시오. 실험 정보 및 아티팩트는 MLflow를 사용하여 추적되고 기록됩니다. 참고: DeepChecks의 결과 보고서( .html 파일)는 규칙을 위해 MLflow의 교육 실험에도 업로드됩니다.model 섹션에서 모델 메타데이터 파일을 빌드합니다.central_storage 에 업로드합니다. (이 경우에는 central_storage 위치에 복사본을 만드는 것뿐입니다. 이는 파일을 클라우드 스토리지에 업로드하도록 변경할 수 있는 단계입니다.)model/drift_detection 섹션을 기반으로 드리프트 감지기를 구축합니다.central_storage 에 저장하고 업로드하세요.central_storage 에 업로드합니다.central_storage 에서 새로 훈련된 모델을 가져오기 위해 실행 중인 서비스( FastAPI + Uvicorn + Gunicorn + Nginx 와 함께 제공)를 트리거하는 PUT 요청입니다. (이것은 튜토리얼 데모 비디오에서 논의된 문제 중 하나입니다. 자세한 내용은 시청하세요)current_model_metadata_file 과 Prefect 작업자 및 흐름 배포를 위한 작업 풀 이름을 저장하는 monitor_pool_name 2개의 변수입니다.deployments/prefect-deployments 에 cd 넣고 구성의 deploy/prefect 섹션에 있는 입력을 사용하여 prefect --no-prompt deploy --name {deploy_name} 실행합니다. 이 리포지토리에는 모든 것이 이미 고정화되고 컨테이너화되어 있으므로 서비스를 온프레미스에서 온클라우드로 전환하는 것은 매우 간단합니다. 서비스 API 개발 및 테스트가 끝나면 Dockerfile에서 컨테이너를 구축하여 services/dl_service를 분리하고 이를 클라우드 컨테이너 레지스트리 서비스(예: AWS ECR)에 푸시할 수 있습니다. 그게 다야!
참고: 실제 프로덕션 환경에서 사용하려는 경우 서비스 코드에 한 가지 잠재적인 문제가 있습니다. 심도있는 영상에서 다뤘으니, 영상 전체를 천천히 시청해 보시기를 권해드립니다. 
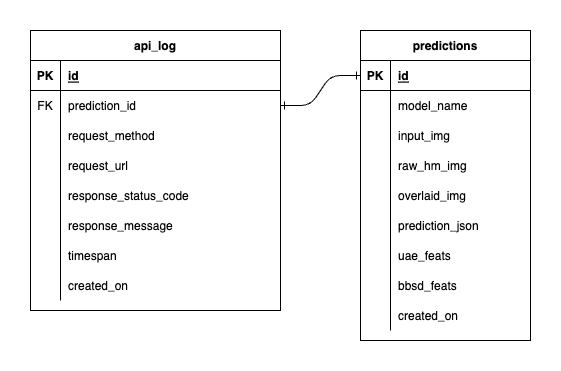
PostgreSQL에는 3개의 데이터베이스가 있습니다. 하나는 MLflow용이고, 하나는 Prefect용이고, 다른 하나는 ML 모델 서비스용으로 생성한 것입니다. 처음 두 개는 해당 도구로 자체 관리되므로 자세히 다루지 않겠습니다. ML 모델 서비스용 데이터베이스는 우리가 직접 설계한 것입니다.
압도적인 복잡성을 피하기 위해 테이블 두 개만 사용하여 단순하게 유지했습니다. 관계와 속성은 아래 ERD에 표시됩니다. 본질적으로 우리는 들어오는 요청과 서비스의 응답에 대한 필수 세부 정보를 저장하는 것을 목표로 합니다. 이 모든 테이블은 자동으로 생성되고 조작되므로 수동 설정에 대해 걱정할 필요가 없습니다.
참고 사항: input_img , raw_hm_img 및 overlaid_img 는 문자열로 저장된 base64 인코딩 이미지입니다. uae_feats 및 bbsd_feats 는 드리프트 감지 알고리즘을 위한 임베딩 기능 배열입니다.
ImportError: /lib/aarch64-linux-gnu/libGLdispatch.so.0: cannot allocate memory in static TLS block . export LD_PRELOAD=/lib/aarch64-linux-gnu/libGLdispatch.so.0 시도한 다음 다시 실행하세요. 스크립트.

