GenAI GeoGuesser
AI가 생성한 조회수에서 국가 이름을 추측하세요
이 프로젝트는 Google 지도의 무작위 세계 위치에 배치되고 시간 카운트다운 동안 위치를 추측해야 하는 인기 있는 GeoGuessr 게임을 다르게 해석한 것입니다. 여기에서는 AI 모델이 생성한 다중 모드 힌트를 기반으로 국가 이름을 추측해야 합니다. 국가에 대한 텍스트 설명을 제공하는 텍스트 , 국가와 유사한 이미지를 제공하는 이미지 및 오디오를 제공하는 3가지 형식 중에서 선택할 수 있습니다. 해당 국가와 관련된 오디오 샘플입니다.
HuggingFace 공간에서 이 앱의 온라인 데모를 확인할 수 있습니다. 이 데모는 성능상의 이유로 이미지 힌트만 생성하도록 제한되었습니다.
이 프로젝트의 작동 방식과 생성 방법에 대해 좀 더 자세히 알아보려면 "생성 AI 기반 GeoGuesser 구축" 기사를 확인하세요.
작업 흐름
- 원하는 힌트 양식을 선택하세요.
- 각 양식에 대한 힌트 수를 선택합니다.
- "게임 시작" 버튼을 클릭하세요.
- 모든 힌트를 보고 '국가 추측' 필드에 추측을 입력하세요.
- "추측하기" 버튼을 클릭하세요.
데모
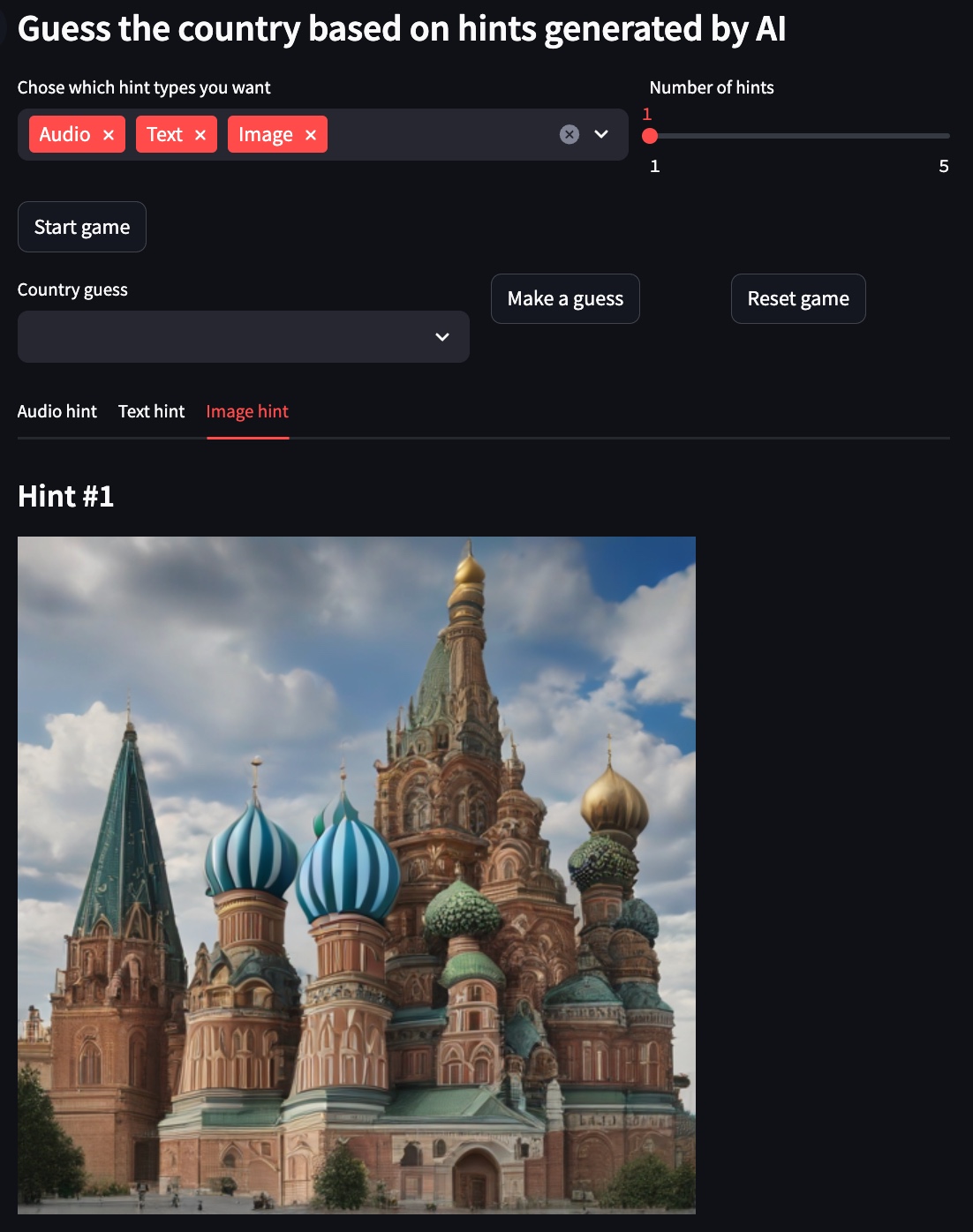
아래 예에서는 선택한 국가 가 러시아 입니다.
텍스트 힌트
이미지 힌트
오디오 힌트
용법
이 리포지토리를 사용하는 데 권장되는 접근 방식은 Docker를 사용하는 것이지만 사용자 지정 venv를 사용할 수도 있습니다. 모든 종속성을 설치했는지 확인하세요.
구성
local:
to_use: true
text:
model_id: google/gemma-1.1-2b-it
device: cpu
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
image:
model_id: stabilityai/sdxl-turbo
device: mps
num_inference_steps: 1
guidance_scale: 0.0
audio:
model_id: cvssp/audioldm2-music
device: cpu
num_inference_steps: 200
audio_length_in_s: 10
vertex:
to_use: false
project: {VERTEX_AI_PROJECT}
location: {VERTEX_AI_LOCALTION}
text:
model_id: gemini-1.5-pro-preview-0409
max_output_tokens: 50
temperature: 1
top_p: 0.95
top_k: 32
- 현지의
- to_use: 프로젝트가 이 설정 구성을 사용해야 하는지 여부
- 텍스트
- model_id: 텍스트 힌트를 생성하는 데 사용되는 모델
- device: 모델에서 사용하는 장치로, 일반적으로 (cpu, cuda, mps) 중 하나입니다.
- max_output_tokens: 모델에서 생성된 최대 토큰 수
- 온도: 온도는 토큰 선택의 무작위성 정도를 제어합니다. 더 낮은 온도는 참되거나 정확한 응답을 기대하는 프롬프트에 적합하고, 더 높은 온도는 더 다양하거나 예상치 못한 결과로 이어질 수 있습니다. 온도가 0이면 항상 확률이 가장 높은 토큰이 선택됩니다.
- top_p: Top-p는 모델이 출력을 위해 토큰을 선택하는 방법을 변경합니다. 토큰은 확률의 합이 top-p 값과 같아질 때까지 가장 가능성이 높은 것부터 가장 작은 것부터 선택됩니다. 예를 들어 토큰 A, B, C의 확률이 .3, .2, .1이고 top-p 값이 .5인 경우 모델은 A 또는 B를 다음 토큰으로 선택합니다(온도 사용). )
- top_k: Top-k는 모델이 출력을 위해 토큰을 선택하는 방법을 변경합니다. top-k 1은 선택된 토큰이 모델 어휘의 모든 토큰 중에서 가장 가능성이 높다는 것을 의미하며(탐욕스러운 디코딩이라고도 함), top-k 3은 다음 토큰이 가장 가능성이 높은 3개의 토큰 중에서 선택된다는 것을 의미합니다( 온도 사용)
- 영상
- model_id: 이미지 힌트를 생성하는 데 사용되는 모델
- device: 모델에서 사용하는 장치로, 일반적으로 (cpu, cuda, mps) 중 하나입니다.
- num_inference_steps: 모델의 추론 단계 수
- Guidance_scale: 잠재적으로 이미지 품질이나 다양성을 희생하면서 생성이 프롬프트와 더 잘 일치하도록 강제합니다.
- 오디오
- model_id: 오디오 힌트를 생성하는 데 사용되는 모델
- device: 모델에서 사용하는 장치로, 일반적으로 (cpu, cuda, mps) 중 하나입니다.
- num_inference_steps: 모델의 추론 단계 수
- audio_length_in_s: 오디오 힌트의 지속 시간 길이
- 꼭지점
- to_use: 프로젝트가 이 설정 구성을 사용해야 하는지 여부
- 프로젝트: Vertex AI에서 사용하는 프로젝트 이름
- location: Vertex AI에서 사용하는 프로젝트 위치
- 텍스트
- model_id: 텍스트 힌트를 생성하는 데 사용되는 모델
- max_output_tokens: 모델에서 생성된 최대 토큰 수
- 온도: 온도는 토큰 선택의 무작위성 정도를 제어합니다. 더 낮은 온도는 참되거나 정확한 응답을 기대하는 프롬프트에 적합하고, 더 높은 온도는 더 다양하거나 예상치 못한 결과로 이어질 수 있습니다. 온도가 0이면 항상 확률이 가장 높은 토큰이 선택됩니다.
- top_p: Top-p는 모델이 출력을 위해 토큰을 선택하는 방법을 변경합니다. 토큰은 확률의 합이 top-p 값과 같아질 때까지 가장 가능성이 높은 것부터 가장 작은 것부터 선택됩니다. 예를 들어, 토큰 A, B, C의 확률이 .3, .2, .1이고 top-p 값이 .5인 경우 모델은 A 또는 B를 다음 토큰으로 선택합니다(온도 사용). )
- top_k: Top-k는 모델이 출력을 위해 토큰을 선택하는 방법을 변경합니다. top-k 1은 선택된 토큰이 모델 어휘의 모든 토큰 중에서 가장 가능성이 높다는 것을 의미하며(탐욕스러운 디코딩이라고도 함), top-k 3은 다음 토큰이 가장 가능성이 높은 3개의 토큰 중에서 선택된다는 것을 의미합니다( 온도 사용)
명령
게임 앱을 시작하세요.
Docker 이미지를 빌드합니다.
코드에 린트 및 서식을 적용합니다(개발에만 필요함).


