SmartFilteringRAG
1.0.0
"오래된 흑백 코미디"를 검색했지만 현대 액션 영화가 혼합되어 포격을 가한 적이 있습니까? 실망스럽죠? 이것이 바로 기존 검색 엔진의 과제입니다. 검색어의 미묘한 차이를 이해하는 데 어려움을 겪는 경우가 많아 관련 없는 결과를 헤매게 만드는 경우가 많습니다.
이것이 바로 스마트 필터링이 등장하는 곳입니다. 이는 메타데이터와 벡터 검색을 사용하여 귀하의 의도와 진정으로 일치하는 검색 결과를 제공하는 획기적인 기능입니다. 번거로움 없이 당신이 갈망하는 고전 코미디를 정확하게 찾는 것을 상상해 보십시오.
스마트 필터링이 무엇인지, 어떻게 작동하는지, 더 나은 검색 경험을 구축하는 데 왜 중요한지 알아보겠습니다. 이 기술 뒤에 숨은 마법을 발견하고 이 기술이 검색 방식을 어떻게 혁신할 수 있는지 살펴보겠습니다.
벡터 검색은 컴퓨터가 단어 자체뿐만 아니라 데이터 이면의 의미를 이해하도록 돕는 강력한 도구입니다. 키워드를 일치시키는 대신 기본 개념과 관계에 중점을 둡니다. "개"를 검색하면 "강아지", "개", 심지어 개 이미지까지 포함된 결과가 나온다고 상상해 보세요. 이것이 바로 벡터 검색의 마법입니다!
어떻게 작동하나요? 데이터를 벡터라는 수학적 표현으로 변환합니다. 이러한 벡터는 지도의 좌표와 유사하며 유사한 데이터 포인트는 이 벡터 공간에서 서로 더 가깝습니다. 귀하가 무언가를 검색하면 시스템은 귀하의 쿼리에 가장 가까운 벡터를 찾아서 의미상 유사한 결과를 제공합니다.
벡터 검색은 컨텍스트를 이해하는 데는 환상적이지만 간단한 필터링 작업에서는 부족할 때가 있습니다. 예를 들어 2000년 이전에 개봉된 모든 영화를 찾으려면 의미론적 이해뿐만 아니라 정밀한 필터링이 필요합니다. 여기에서 벡터 검색을 보완하기 위해 스마트 필터링이 사용됩니다.
벡터를 사용하면 쿼리의 진정한 의미를 더 잘 이해할 수 있지만 사용자가 원하는 것과 검색 엔진이 제공하는 것 사이에는 여전히 격차가 있습니다. "2000년 이전의 가장 초기 코미디 영화"와 같은 복잡한 검색어는 여전히 어려울 수 있습니다. 의미론적 검색은 "코미디"와 "영화"의 개념을 이해할 수 있지만 "가장 빠른" 및 "2000년 이전"의 구체적인 내용에는 어려움을 겪을 수 있습니다.
여기서부터 결과가 지저분해지기 시작합니다. 오래된 코미디와 새로운 코미디가 혼합되어 있을 수도 있고, 심지어 실수로 포함된 드라마도 있을 수 있습니다. 사용자를 진정으로 만족시키려면 이러한 검색 결과를 구체화하고 더욱 정확하게 만드는 방법이 필요합니다. 이것이 바로 사전 필터가 작동하는 곳입니다.
스마트 필터링은 이러한 문제에 대한 솔루션입니다. 데이터 세트의 메타데이터를 사용하여 특정 필터를 생성하고 검색 결과를 구체화하여 더욱 정확하고 효율적으로 만드는 기술입니다. 스마트 필터링은 구조, 콘텐츠, 속성 등 데이터에 대한 정보를 분석하여 관련 기준을 식별하여 검색을 필터링할 수 있습니다.
"2000년 이전에 개봉된 코미디 영화"를 검색한다고 상상해 보세요. 스마트 필터링은 장르, 개봉일, 플롯 키워드 등의 메타데이터를 사용하여 해당 기준과 일치하는 영화만 포함하는 필터를 생성합니다. 이렇게 하면 불필요한 잡음 없이 정확히 원하는 항목의 목록을 얻을 수 있습니다.
다음 섹션에서 스마트 필터링이 작동하는 방식에 대해 자세히 살펴보겠습니다.
스마트 필터링은 데이터에서 정보를 추출하고, 분석하고, 필요에 따라 특정 필터를 생성하는 다단계 프로세스입니다. 그것을 분석해 봅시다:
메타데이터 추출: 첫 번째 단계는 데이터에 대한 관련 정보를 수집하는 것입니다. 여기에는 다음과 같은 세부정보가 포함됩니다.
사전 필터 생성: 메타데이터가 있으면 사전 필터 생성을 시작할 수 있습니다. 이는 데이터가 검색 결과에 포함되기 위해 충족해야 하는 특정 조건입니다. 예를 들어 2000년 이전에 개봉된 코미디 영화를 검색하는 경우 다음에 대한 사전 필터를 만들 수 있습니다.
벡터 검색과 통합: 마지막 단계는 이러한 사전 필터를 벡터 검색과 결합하는 것입니다. 이렇게 하면 벡터 검색에서 미리 정의된 기준과 일치하는 데이터 포인트만 고려됩니다.
이러한 단계를 따르면 스마트 필터링은 검색 결과의 정확성과 효율성을 크게 향상시킵니다.
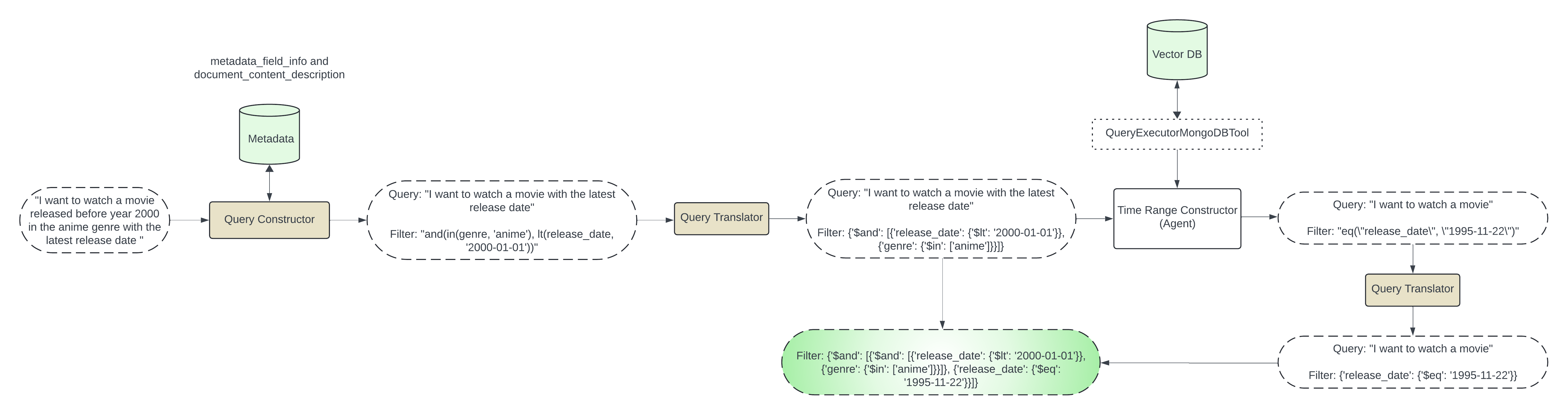
메타데이터 추출: 작업을 단순화하기 위해 샘플 데이터를 사용하고 메타데이터를 수동으로 정의합니다. 참조: prepare_test_data.py 의 get_docs_metadata.
사전 필터 생성: 사전 필터를 두 단계로 생성합니다.
1단계: 메타데이터 기반 필터
이 단계에는 메타데이터를 기반으로 필터를 생성하는 작업이 포함됩니다. 사용자 쿼리와 메타데이터를 LLM에 전달하고 메타데이터 필터를 생성하겠습니다.
이 DEFAULT_SCHEMA_PROMPT로 초기화된 query_constructor를 사용하겠습니다.
참고: 사용 사례에 따라 프롬프트와 몇 가지 샷 예시를 업데이트하세요.
예: 메타데이터에 genre 및 release_date 있고 사용자가 2020년 이전에 출시된 action 장르 영화를 요청하는 경우 LLM을 사용하여 아래와 같은 필터를 생성할 수 있습니다.
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
2단계: 시간 기반 필터링
이 단계에서는 사용자가 latest , most recent , earliest 유형의 정보를 요청하는 경우를 처리합니다. 이 정보를 가져오려면 실제 데이터를 쿼리해야 합니다. 이 단계에서는 LLM 에이전트를 사용하여 실행 도구인 QueryExecutorMongoDBTool을 사용하여 mongodb 컬렉션을 쿼리합니다. generate_time_based_filter에서 시간 기반 필터를 생성합니다. 또한 집계 단계의 $match 첫 번째 단계에서 생성된 pre_filter를 사용합니다. 예: 사용자가 최신 영화를 원하는 경우 LLM 에이전트는 실행 도구를 사용하여 집계 쿼리 아래에서 실행됩니다.
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
벡터 검색과 통합: 생성된 사전 필터는 MongoDBAtlasVectorSearch 검색기와 함께 사용됩니다.
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)새로운 Python 환경 만들기
python3 -m venv env
source env/bin/activate요구사항 설치
pip3 install -r requirements.txtconfig.yaml에서 구성을 설정합니다.
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002환경 변수 설정
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "샘플 데이터로 mongodb 컬렉션을 초기화합니다. 이 명령은 일부 샘플 데이터를 색인화하고 컬렉션에 대한 벡터 검색 색인도 생성합니다.
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] '생성된 사전 필터:
입력 쿼리: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
산출: 
입력 쿼리: "Recommend a thriller or action movie release after Feb, 2010"
산출: 
입력 쿼리: "Recommend an anime movie released before 2023 with the latest release date"
산출: 
스마트 필터링은 테이블에 다양한 이점을 제공하여 검색 경험을 향상시키는 데 유용한 도구가 됩니다.
향상된 검색 정확도: 스마트 필터링은 쿼리와 일치하는 데이터를 정확하게 타겟팅함으로써 관련 결과를 찾을 가능성을 크게 높입니다. 더 이상 관련 없는 정보를 헤매지 마세요.
더 빠른 검색 결과: 스마트 필터링은 검색 범위를 좁히므로 시스템이 정보를 보다 효율적으로 처리하여 더 빠른 결과를 얻을 수 있습니다.
향상된 사용자 경험: 사용자가 원하는 것을 빠르고 쉽게 찾을 때 만족도가 높아지고 전반적인 경험이 향상됩니다.
다용성: 스마트 필터링은 전자상거래 제품 검색부터 콘텐츠 추천까지 다양한 도메인에 적용할 수 있어 다재다능한 도구입니다.
메타데이터를 활용하고 타겟 사전 필터를 생성함으로써 스마트 필터링을 통해 사용자 기대에 진정으로 부합하는 검색 결과를 제공할 수 있습니다.
스마트 필터링은 사용자 의도와 결과 사이의 격차를 해소하여 경험을 변화시키는 강력한 도구입니다. 메타데이터와 벡터 검색의 강력한 기능을 활용하여 보다 정확하고 관련성이 높으며 효율적인 검색 결과를 제공합니다.
전자 상거래 플랫폼, 콘텐츠 추천 시스템 또는 효과적인 검색에 의존하는 모든 애플리케이션을 구축하는 경우 스마트 필터링을 통합하면 사용자 만족도를 크게 높이고 더 나은 결과를 얻을 수 있습니다.
스마트 필터링의 기본 사항을 이해하면 그 잠재력을 탐색하고 프로젝트에 구현할 수 있습니다. 그럼 왜 기다려? 지금부터 스마트 필터링의 강력한 기능을 활용하여 검색 게임에 혁명을 일으키십시오!
LangChain의 Self Query Retriever에서 영감을 얻었습니다.


