genkitx hnsw
1.0.0

이 저장소에서 이 플러그인에 기여할 수 있습니다.
HNSW는 벡터 데이터베이스 HNSW(Hierarchical Navigable Small World) 그래프는 벡터 유사성 검색을 위한 최고 성능의 인덱스 중 하나입니다. HNSW는 초고속 검색 속도와 환상적인 재현율로 최첨단 성능을 계속해서 만들어내는 큰 인기를 누리는 기술입니다. HNSW에 대해 자세히 알아보세요.
원하는 경우 이 벡터 데이터베이스를 선호할 수 있습니다.
이를 통해 Generative AI에서 고성능 검색 증강 생성(RAG)을 달성할 수 있으므로 더 많은 컨텍스트나 지식을 얻기 위해 자체 AI 모델을 구축하거나 AI 모델을 재교육할 필요가 없습니다. 대신 컨텍스트 계층을 추가하여 다음을 수행할 수 있습니다. AI 모델은 기본 AI 모델이 아는 것보다 더 많은 지식을 이해할 수 있습니다. 이는 정의한 특정 정보나 지식을 기반으로 더 많은 컨텍스트나 지식을 얻으려는 경우에 유용합니다.
레스토랑 애플리케이션이나 웹사이트가 있고 레스토랑, 주소, 음식 메뉴 목록과 가격 및 기타 특정 사항에 대한 특정 정보를 추가할 수 있습니다. 그러면 고객이 AI에 레스토랑에 대해 질문할 때 AI가 정확하게 답변할 수 있습니다. . 이를 통해 Chatbot을 구축하려는 노력을 덜 수 있으며, 대신 특정 지식이 풍부한 Generative AI를 사용할 수 있습니다.
대화 예시:
You : 수라바야 시에 있는 우리 식당의 가격표는 얼마입니까?
AI : 가격표 :
플러그인을 설치하기 전에 다음 필수 구성 요소가 설치되어 있는지 확인하세요.
npm install -g typescript 통해 전역적으로 설치할 수 있음)이 플러그인을 설치하려면 이 명령을 실행하거나 원하는 패키지 관리자를 사용하면 됩니다.
npm install genkitx-hnsw이 플러그인에는 아래와 같은 여러 기능이 있습니다.
HNSW Indexer 귀하가 제공한 모든 데이터와 정보를 기반으로 벡터 인덱스를 생성하는 데 사용됩니다. 이 벡터 인덱스는 HNSW Retriever의 지식 참조로 사용됩니다.HNSW Retriever Gemini 모델을 기반으로 벡터 인덱스를 기반으로 추가 지식과 컨텍스트가 강화된 생성적 AI 응답을 얻는 데 사용됩니다. 이는 HNSW Vector Store, Gemini Embedder 및 Gemini LLM을 사용하여 벡터 저장소에 데이터를 저장하기 위해 Genkit 플러그인 흐름을 사용하는 것입니다.
폴더에 데이터 또는 문서 준비 
플러그인을 Genkit 프로젝트로 가져오기
import { hnswIndexer } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
hnswIndexer({ apiKey: " GOOGLE_API_KEY " })
]
}) ; Genkit UI를 열고 등록된 플러그인 HNSW Indexer 선택하세요.
입력 및 출력 필수 매개변수로 흐름을 실행합니다.
dataPath : AI가 학습할 데이터 및 기타 문서 경로indexOutputPath : 귀하가 제공한 데이터 및 문서를 기반으로 처리되는 벡터 스토어 인덱스의 예상 출력 경로 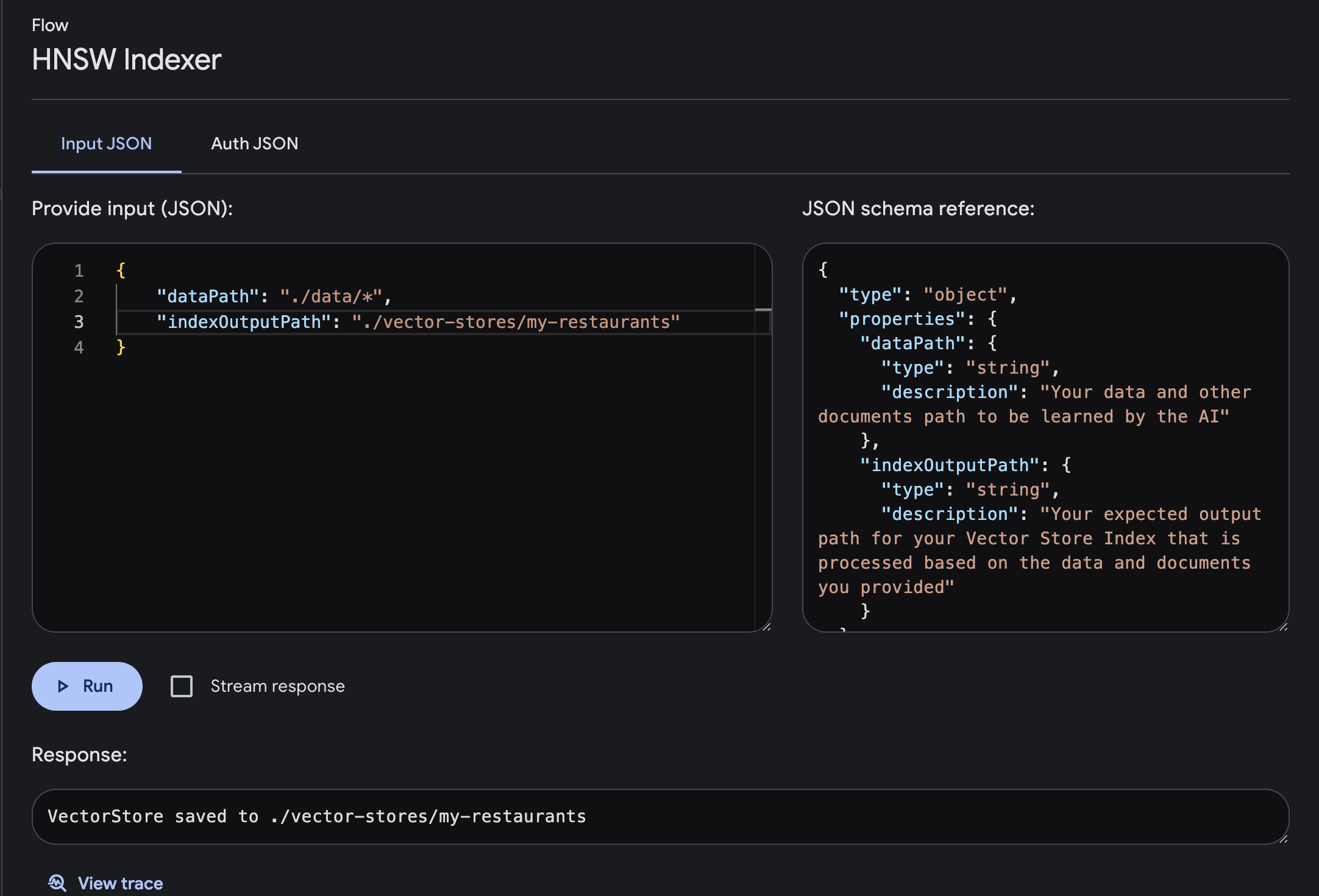
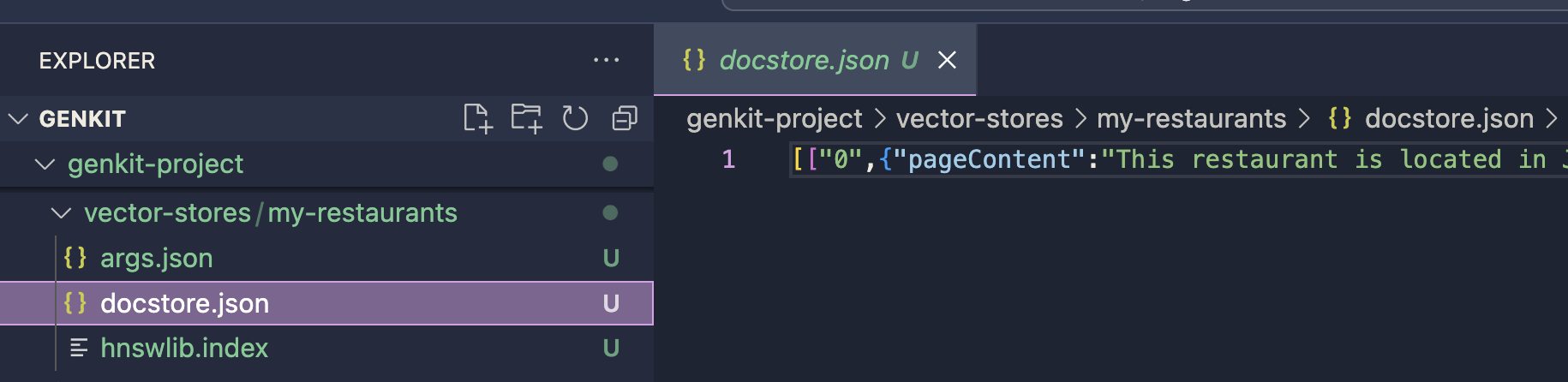 벡터 저장소는 정의된 출력 경로에 저장됩니다. 이 인덱스는 HNSW Retriever 플러그인을 사용한 프롬프트 생성 프로세스에 사용됩니다. HNSW Retriever 플러그인을 사용하여 구현을 계속할 수 있습니다.
벡터 저장소는 정의된 출력 경로에 저장됩니다. 이 인덱스는 HNSW Retriever 플러그인을 사용한 프롬프트 생성 프로세스에 사용됩니다. HNSW Retriever 플러그인을 사용하여 구현을 계속할 수 있습니다.
chunkSize: number 한 번에 처리되는 데이터의 양입니다. 이는 큰 작업을 더 작은 조각으로 나누어 관리하기 쉽게 만드는 것과 같습니다. 청크 크기를 설정하여 AI가 한 번에 처리하는 정보의 양을 결정하며, 이는 AI 학습 프로세스의 속도와 정확성 모두에 영향을 미칠 수 있습니다.
default value : 12720
separator: string 벡터 인덱스를 생성하는 동안 입력 데이터의 다양한 정보를 구분하는 데 사용되는 기호나 문자가 사용됩니다. 이는 AI가 한 데이터 단위가 끝나고 다른 단위가 시작되는 위치를 이해하여 데이터를 보다 효과적으로 처리하고 학습할 수 있도록 도와줍니다.
default value : "n"
이는 귀하가 제공한 HNSW 벡터 데이터베이스 내의 추가적이고 구체적인 정보나 지식이 풍부한 Gemini LLM 모델로 프롬프트를 처리하기 위해 Genkit 플러그인 흐름을 사용하는 것입니다. 이 플러그인을 사용하면 추가적인 특정 컨텍스트가 포함된 LLM 응답을 얻을 수 있습니다.
플러그인을 Genkit 프로젝트로 가져오기
import { googleAI } from " @genkit-ai/googleai " ;
import { hnswRetriever } from " genkitx-hnsw " ;
export default configureGenkit({
plugins: [
googleAI (),
hnswRetriever({ apiKey: " GOOGLE_API_KEY " })
]
}) ;Gemini LLM 모델 공급자용 GoogleAI 플러그인을 가져와야 합니다. 현재 이 플러그인은 Gemini만 지원하며 곧 더 많은 모델을 제공할 예정입니다!
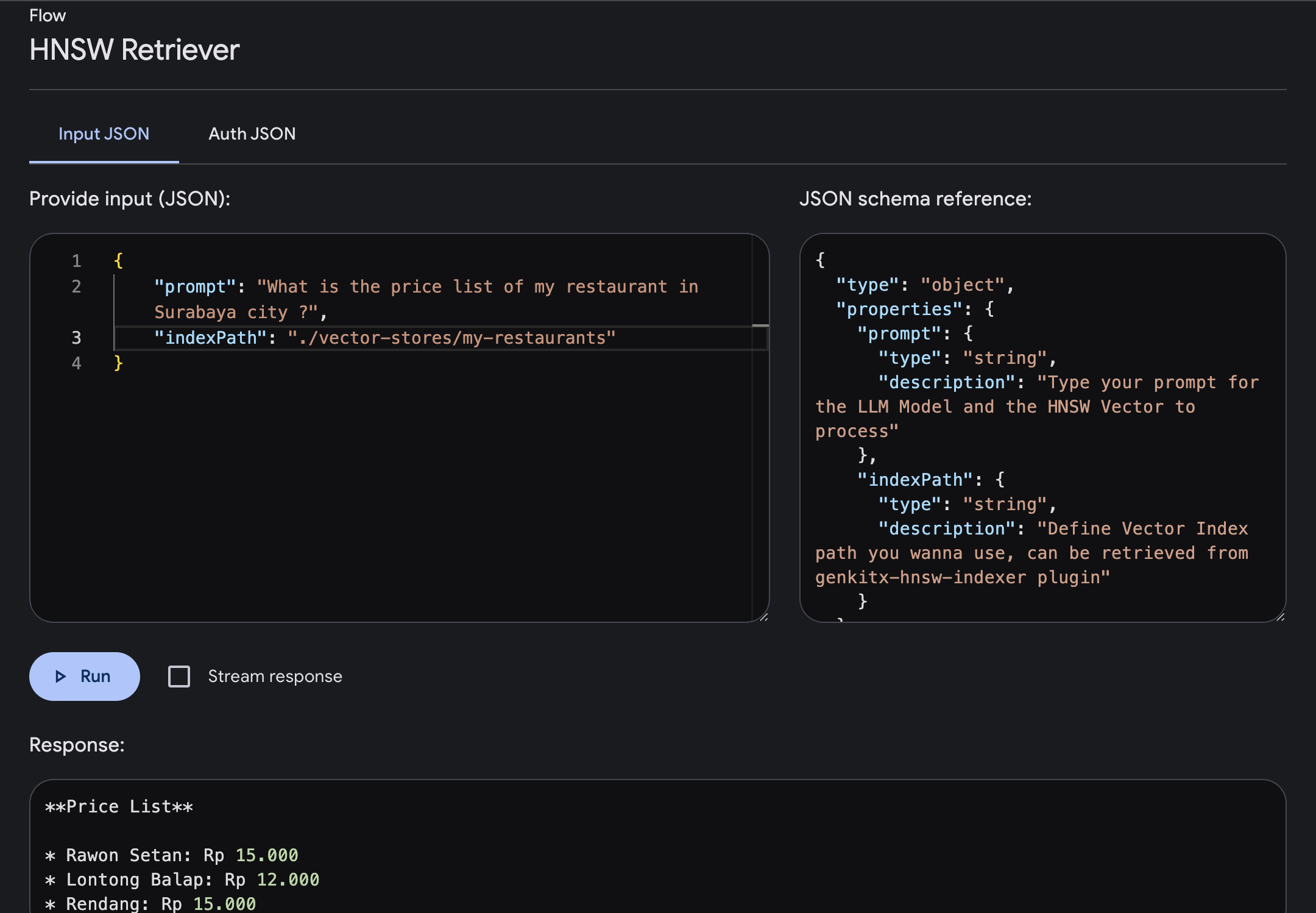
Genkit UI를 열고 등록된 Plugin HNSW Retriever 선택합니다. 필수 매개변수로 흐름을 실행합니다.
prompt : 제공한 벡터를 기반으로 더욱 풍부한 컨텍스트로 답변을 얻을 수 있는 프롬프트를 입력합니다.indexPath : 지식 참조로 사용하려는 폴더 벡터 인덱스 경로를 정의합니다. 여기서 이 파일 경로는 HNSW Indexer 플러그인에서 가져옵니다.이 예에서는 벡터 인덱스 내에서 제공되는 수라바야(Surabaya) 시내 레스토랑의 가격표 정보에 대해 질문해 보겠습니다.
프롬프트를 입력하고 실행하면 흐름이 완료된 후 벡터 인덱스를 기반으로 특정 지식이 풍부한 응답을 받게 됩니다.
temperature: number 온도는 생성된 출력의 무작위성을 제어합니다. 온도가 낮을수록 모델이 각 단계에서 가장 가능성이 높은 토큰을 선택하여 더 결정적인 출력이 생성됩니다. 온도가 높을수록 무작위성이 증가하여 모델이 가능성이 낮은 토큰을 탐색할 수 있게 되어 잠재적으로 더 창의적이지만 일관성이 떨어지는 텍스트를 생성할 수 있습니다.
default value : 0.1
maxOutputTokens: number 이 매개변수는 모델이 단일 추론 단계에서 생성해야 하는 토큰(단어 또는 하위 단어)의 최대 수를 지정합니다. 생성된 텍스트의 길이를 제어하는 데 도움이 됩니다.
default value : 500
topK: number Top-K 샘플링은 모델의 선택을 각 단계에서 가장 가능성이 높은 상위 K개 토큰으로 제한합니다. 이는 모델이 지나치게 희귀하거나 가능성이 낮은 토큰을 고려하는 것을 방지하여 생성된 텍스트의 일관성을 향상시키는 데 도움이 됩니다.
default value : 1
topP: number 핵 샘플링이라고도 하는 Top-P 샘플링은 토큰의 누적 확률 분포를 고려하고 누적 확률이 사전 정의된 임계값(종종 P로 표시됨)을 초과하는 가장 작은 토큰 집합을 선택합니다. 이를 통해 토큰의 가능성에 따라 각 단계에서 고려되는 토큰 수를 동적으로 선택할 수 있습니다.
default value : 0
stopSequences: string[] 이는 생성 시 모델에 텍스트 생성을 중지하라는 신호를 보내는 토큰 시퀀스입니다. 이는 문장이나 단락의 끝에 도달한 후 모델 생성이 중지되도록 하는 등 생성된 출력의 길이나 내용을 제어하는 데 유용할 수 있습니다.
default value : []
라이센스 : 아파치 2.0


