rag with human support
1.0.0
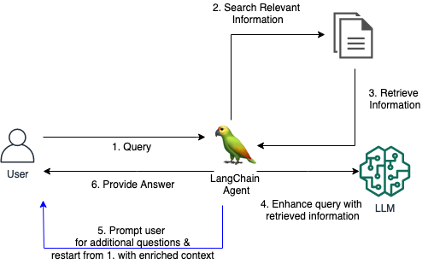
기존 RAG 시스템은 사용자가 충분한 맥락을 제공하지 않고 모호하거나 모호한 질문을 할 때 만족스러운 답변을 제공하는 데 어려움을 겪는 경우가 많습니다. 이로 인해 "모르겠어요"와 같은 도움이 되지 않는 응답이나 LLM이 제공한 부정확하고 꾸며낸 답변으로 이어집니다. 이 저장소에는 기존 RAG 에이전트를 개선하는 코드가 포함되어 있습니다.
RAG 에이전트를 위한 맞춤형 LangChain 도구를 소개합니다. 이를 통해 에이전트는 초기 질문이 불분명하거나 너무 모호할 때 사용자와 대화에 참여할 수 있습니다. 명확한 질문을 하고, 사용자에게 자세한 내용을 묻고, 상황에 맞는 정보를 통합함으로써 에이전트는 모호한 초기 쿼리에서도 정확하고 유용한 답변을 제공하는 데 필요한 상황을 수집할 수 있습니다.
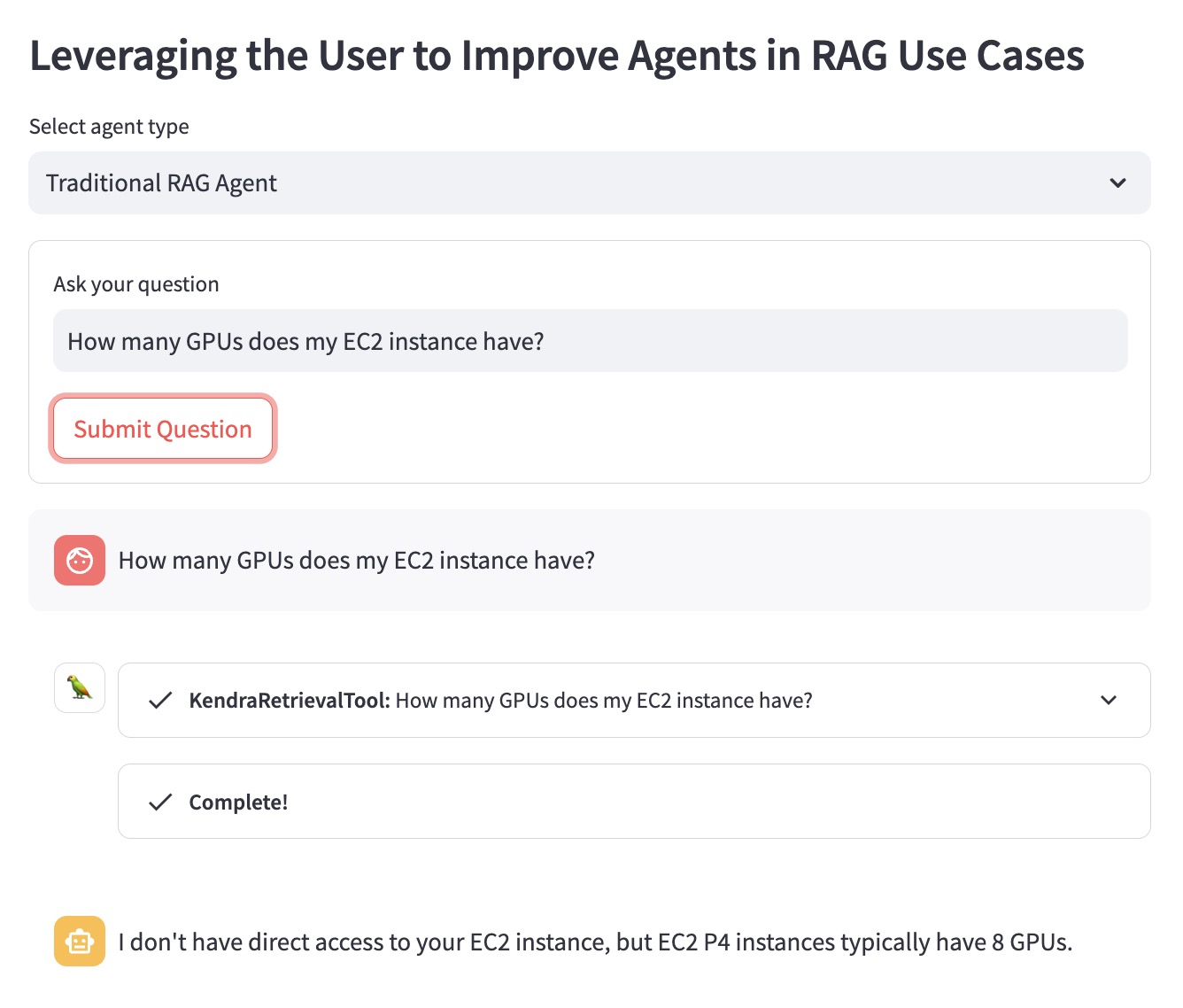
다음 질문 예를 사용하여 이점을 설명해 보겠습니다. "내 EC2 인스턴스에는 GPU가 몇 개 있습니까?"
기존 RAG 에이전트는 사용자가 어떤 EC2 인스턴스를 염두에 두고 있는지 알지 못합니다. 따라서 별로 도움이 되지 않는 답변을 제공합니다.
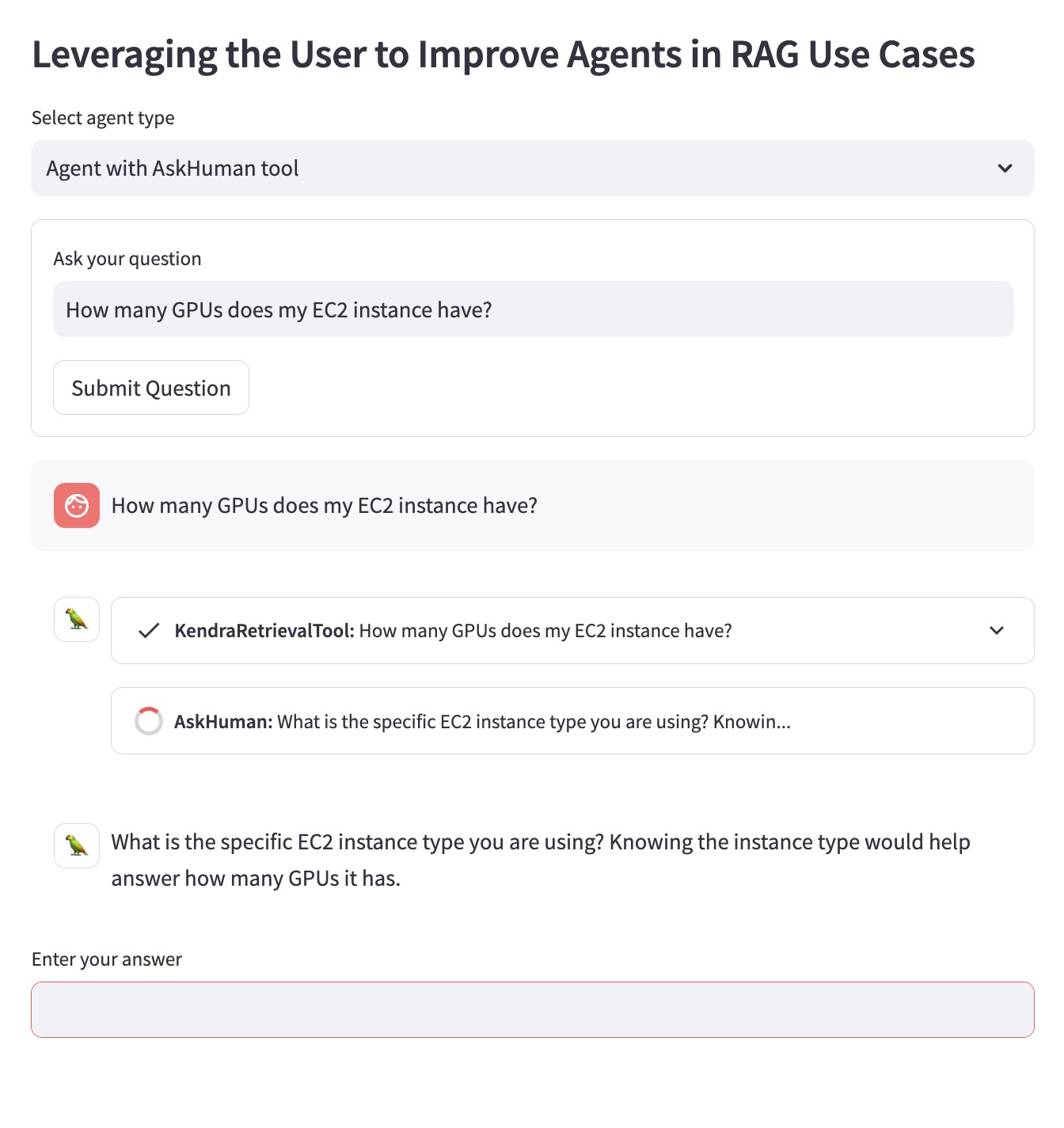
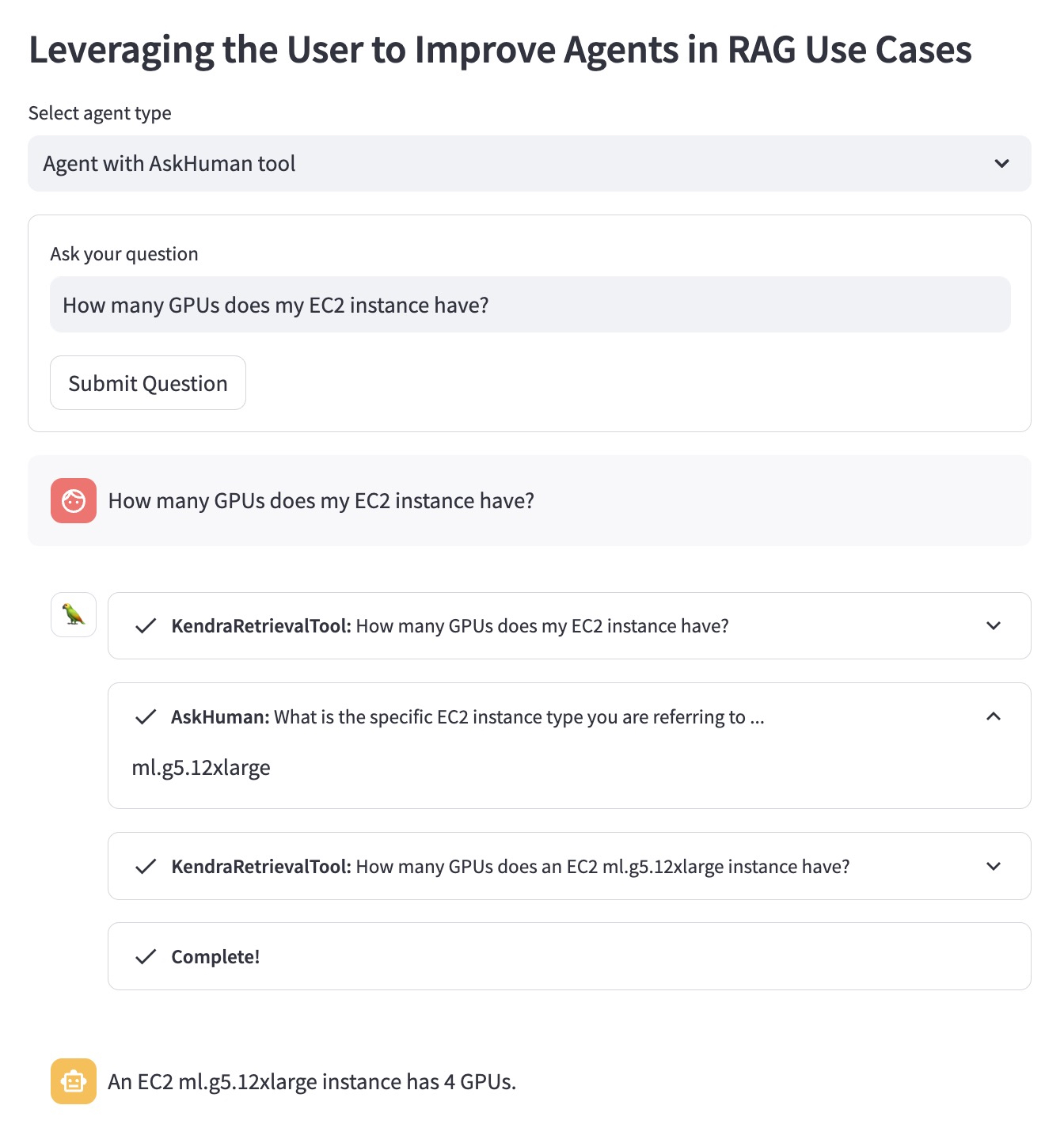
AskHuman 도구를 사용하여 향상된 RAG 에이전트는 두 가지 추가 단계를 수행합니다.
이는 개선된 에이전트가 구체적이고 유용한 답변을 제공하는 데 도움이 됩니다.
AWS 계정에서 이 데모를 실행하려면 다음 단계를 따라야 합니다.
demo.py 의 LangChain 에이전트에 사용된 llm LangChain에서 지원하는 LLM으로 교체하세요.sh dependencies.sh 실행하여 종속성을 설치합니다.demo.py 에 해당 KENDRA_INDEX_ID 지정하세요.streamlit run demo.py 실행하여 Streamlit 앱을 시작하세요. 새로운 Kendra 인덱스를 배포하고 데모를 실행하면 청구서에 추가 요금이 추가될 수 있습니다. 불필요한 비용 발생을 방지하려면 더 이상 사용하지 않는 Amazon Kendra Index를 삭제하고, 데모 실행에 사용한 SageMaker Studio 인스턴스를 종료하십시오.


