content dicovery platform gcp
1.0.0
이 저장소에는 VertexAI 기본 모델로 구동되는 간단한 콘텐츠 검색 플랫폼을 구축하는 데 필요한 코드와 자동화가 포함되어 있습니다. 이 플랫폼은 문서 콘텐츠(처음에는 Google Docs)를 캡처할 수 있어야 하며, 해당 콘텐츠를 사용하여 VertexAI Matching Engine으로 구동되는 벡터 데이터베이스에 저장할 임베딩 벡터를 생성합니다. 나중에 이 임베딩을 활용하여 외부 소비자의 일반 질문을 맥락화하고 해당 컨텍스트는 답변을 얻기 위해 VertexAI 기본 모델에 대한 답변을 요청합니다.
플랫폼은 액세스 서비스 계층, 콘텐츠 캡처 파이프라인, 콘텐츠 스토리지 및 LLM의 4가지 주요 구성 요소로 구분될 수 있습니다. 서비스 계층을 사용하면 외부 소비자가 문서 수집 요청을 보내고 나중에 이전에 수집된 문서에 포함된 콘텐츠에 대한 문의를 보낼 수 있습니다. 콘텐츠 캡처 파이프라인은 NRT에서 문서의 콘텐츠를 캡처하고, 임베딩을 추출하고, 나중에 외부 사용자 질문을 LLM에 맥락화하는 데 사용할 수 있는 실제 콘텐츠와 임베딩을 매핑하는 일을 담당합니다. 콘텐츠 저장소는 LLM 미세 조정, 온라인 임베딩 일치 및 청크 콘텐츠라는 3가지 목적으로 분리되며, 각 목적은 특수한 저장소 시스템에 의해 처리되며 수집 및 쿼리를 구현하기 위해 플랫폼 구성 요소에 필요한 정보를 저장하는 일반적인 목적을 가지고 있습니다. 사용 사례. 마지막으로 플랫폼은 2개의 특수 LLM을 사용하여 수집된 문서 콘텐츠에서 실시간 임베딩을 생성하고 다른 LLM은 플랫폼 사용자가 요청한 답변을 생성하는 역할을 합니다.
앞에서 설명한 모든 구성 요소는 공개적으로 사용 가능한 GCP 서비스를 사용하여 구현됩니다. 열거하려면: 콘텐츠 정보로 Google Docs 및 Google Drive와 함께 Cloud Build, Cloud Run, Cloud Dataflow, Cloud Pubsub, Cloud Storage, Cloud Bigtable, Vertex AI Matching Engine, Vertex AI 기본 모델(임베딩 및 텍스트 바이슨) 소스.
다음 이미지는 아키텍처와 기술의 다양한 구성 요소가 서로 상호 작용하는 방식을 보여줍니다.
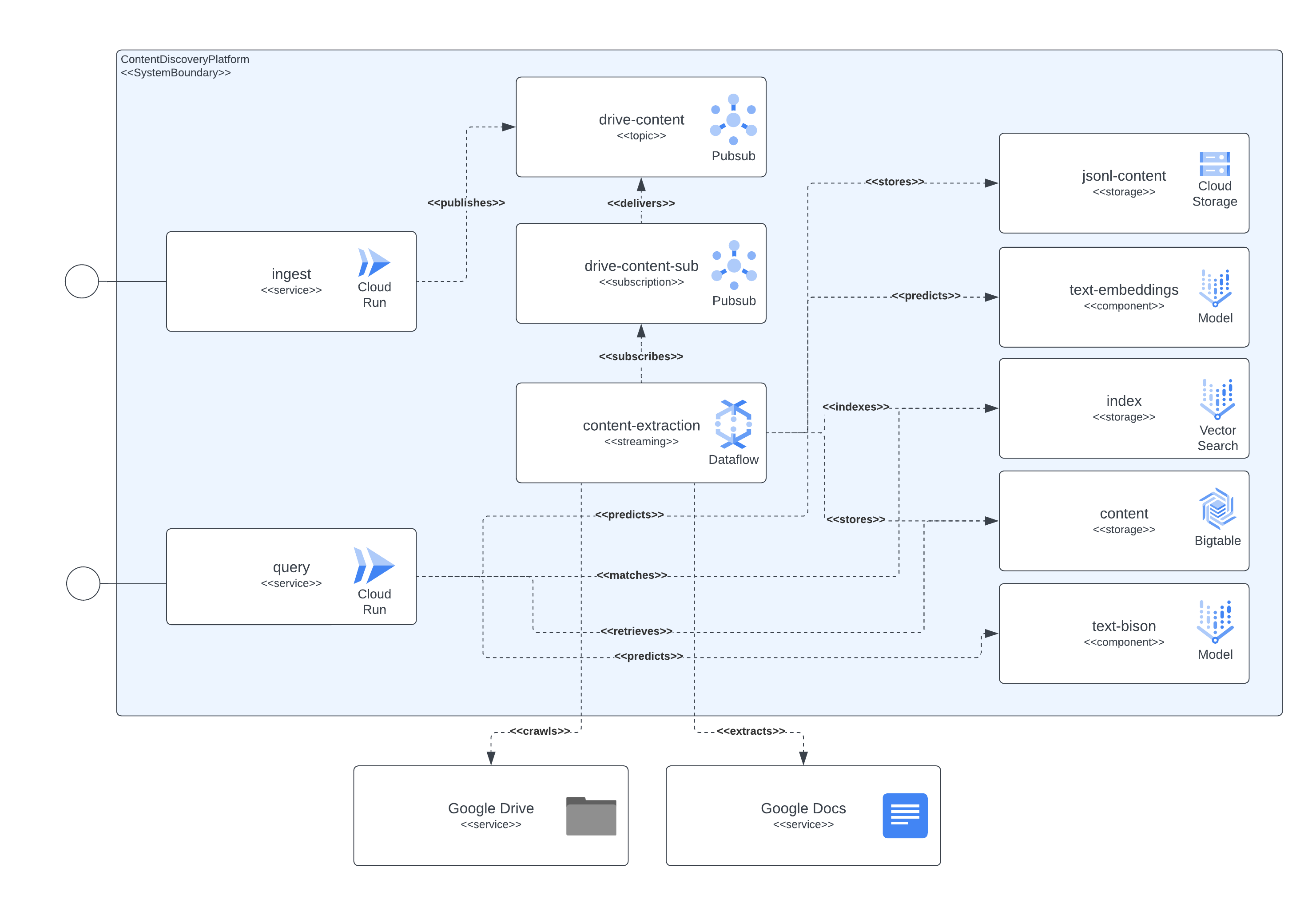
이 플랫폼은 모든 구성 요소 설정에 Terraform을 사용합니다. 현재 기본 지원이 없는 경우 null_resource 래퍼를 만들었습니다. 이는 좋은 해결 방법이지만 가장자리가 매우 거친 경향이 있으므로 잠재적인 오류에 유의하세요.
오늘(2023년 6월) 현재 전체 배포를 완료하는 데 최대 90분이 걸릴 수 있으며, 가장 큰 원인은 생성되고 즉시 사용 가능한 데 대부분의 시간이 걸리는 일치 엔진 관련 구성 요소입니다. 시간이 지나면서 이러한 확장된 런타임은 개선될 것입니다.
설정은 저장소에 포함된 스크립트에서 실행 가능해야 합니다.
이 플랫폼을 배포하려면 다음과 같은 몇 가지 요구 사항을 충족해야 합니다.
모든 구성요소를 GCP에 배포하려면 인프라를 구축하고 생성한 후 나중에 서비스와 파이프라인을 배포해야 합니다.
이를 달성하기 위해 우리는 기본적으로 전체 배포 목표를 달성하기 위해 포함된 다른 스크립트를 조정하는 스크립트 start.sh 포함했습니다.
또한 인프라를 파괴하고 수집된 데이터를 정리하는 cleanup.sh 스크립트도 포함했습니다.
일반적인 경우 Google Workspace 문서는 콘텐츠 수집 파이프라인이 실행되는 프로젝트를 호스팅하는 동일한 조직에서 생성되므로 해당 문서에 권한을 부여하려면 파이프라인을 실행하는 서비스 계정을 문서 또는 문서 폴더에 추가하세요. , 충분해야합니다.
프로젝트 조직 외부에 있는 문서나 폴더에 액세스해야 하는 경우 추가 단계를 완료해야 합니다. 인프라가 설정되면 배포 프로세스에서는 콘텐츠 추출 파이프라인을 실행하는 서비스 계정에 도메인 전체 위임을 통해 Google Workspace 문서 액세스 권한을 가장할 수 있는 권한을 부여하는 지침을 인쇄합니다. 단계를 완료하기 위한 정보는 여기에서 확인할 수 있습니다: https://developers.google.com/workspace/guides/create-credentials#Optional_set_up_domain-wide_delegation_for_a_service_account
이 솔루션은 콘텐츠 수집 및 콘텐츠 검색 쿼리를 위해 상호 작용하는 데 사용할 수 있는 GCP CloudRun 및 API 게이트웨이를 통해 몇 가지 리소스를 노출합니다. 모든 예제에서는 서비스 배포가 완료된 후 CloudRun(Terraform 출력의 backend_service_url ) 또는 API 게이트웨이(Terraform 출력의 sevice_url )에서 제공하는 URL로 대체되어야 하는 기호 <service-address> 문자열을 사용합니다.
CORS 상호 작용이 필요한 경우 실행 전 프로토콜을 완료하려고 할 때 API 게이트웨이 엔드포인트를 사용할 수 있습니다. CloudRun은 현재 인증되지 않은 OPTIONS 명령을 지원하지 않지만 API Gateway를 통해 노출된 경로는 이를 지원합니다.
이 서비스는 Google 드라이브에 호스팅된 문서 또는 문서 식별자와 바이너리로 인코딩된 문서 콘텐츠를 포함하는 자체 포함 다중 부분 요청에서 데이터를 수집할 수 있습니다.
Google 드라이브 수집은 다음 예와 유사한 HTTP 요청을 전송하여 수행됩니다.
$ > curl -X POST -H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /ingest/content/gdrive
-d $' {"url":"https://docs.google.com/document/d/somevalid-googledocid"} ' 이 요청은 제공된 url 에서 문서를 가져오는 플랫폼을 나타내며, 수집을 실행하는 서비스 계정에 문서에 대한 액세스 권한이 있는 경우 해당 문서에서 콘텐츠를 추출하고 색인 생성, 향후 검색 및 검색을 위해 정보를 저장합니다.
요청에는 Google 문서 또는 Google 드라이브 폴더의 URL이 포함될 수 있으며, 마지막 경우 처리는 처리할 문서의 폴더를 크롤링합니다. 또한 각각 유효한 Google 문서 URL인 string 값의 JSONArray 기대하는 속성 urls 사용할 수도 있습니다.
수집 클라이언트가 로컬로 액세스할 수 있는 기사, 문서 또는 페이지의 콘텐츠를 포함하려는 경우 멀티파트 엔드포인트를 사용하는 것만으로도 문서를 수집하기에 충분합니다. 예를 들어 다음 curl 명령을 참조하세요. 서비스는 documentId 양식 필드가 콘텐츠를 식별하고 일의적으로 색인화하도록 설정되어 있다고 예상합니다.
$ > curl -H " Authorization: Bearer $( gcloud auth print-identity-token ) "
-F documentId= < somedocid >
-F documentContent=@ < /some/local/directory/file/to/upload >
https:// < service-address > /ingest/content/multipart이 서비스는 자연 텍스트 쿼리를 서비스에 전송하여 플랫폼 사용자에게 쿼리 기능을 노출하고 플랫폼에서 수집 후 이미 콘텐츠 인덱스가 있는 경우 서비스는 LLM 모델을 통해 요약된 정보와 함께 돌아옵니다.
서비스와의 상호 작용은 다음 예에서 볼 수 있듯이 수집 부분과 유사한 REST 교환을 통해 수행될 수 있습니다.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": ""} '
| jq .
# response from service
{
"content": "VertexAI foundational models are a set of pre-trained models that can be used to build and deploy machine learning applications. They are available in a variety of languages and frameworks, and can be used for a variety of tasks, including natural language processing, computer vision, and recommendation systems.nnVertexAI foundational models are a good choice for Generative AI applications because they provide a starting point for building these types of applications. They can be used to quickly and easily create models that can generate text, images, and other types of content.nnIn addition, VertexAI foundational models are scalable and can be used to process large amounts of data. They are also reliable and can be used to create applications that are available 24/7.nnOverall, VertexAI foundational models are a powerful tool for building Generative AI applications. They provide a starting point for building these types of applications, and they can be used to quickly and easily create models that can generate text, images, and other types of content.",
" sourceLinks " : [
]
}여기에는 특정 주제에 대해 아직 저장된 정보가 없는 특별한 경우가 있습니다. 해당 주제가 GCP 환경에 속하면 모델 요청에 이를 나타내는 프롬프트를 설정하므로 모델이 전문가 역할을 하게 됩니다.
서비스와의 컨텍스트 인식 유형 교환을 더 원하는 경우 대화 교환 키로 사용할 서비스에 세션 식별자(JSON 요청의 sessionId 속성)를 제공해야 합니다. 이 대화 키는 (이전 교환을 요약하여) 모델에 대한 올바른 컨텍스트를 설정하고 (적어도) 마지막 5개의 교환을 추적하는 데 사용됩니다. 또한 교환 내역은 24시간 동안 유지되며 이는 플랫폼 내 BigTable 스토리지의 gc 정책의 일부로 변경될 수 있다는 점에 유의할 가치가 있습니다.
다음은 상황 인식 대화의 예입니다.
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.nnUsing VertexAI Foundational Models can help you to:nn* Reduce the time and effort required to develop Generative AI applicationsn* Improve the accuracy and quality of your modelsn* Access the latest research and development in Generative AInnVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"describe the available LLM models?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models suite includes a variety of LLM models, including:nn* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.nnThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools. " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits). " ,
" sourceLinks " : [
]
}
$ > curl -X POST
-H " Content-Type: application/json "
-H " Authorization: Bearer $( gcloud auth print-identity-token ) "
https:// < service-address > /query/content
-d $' {"text":"care to share the price?", "sessionId": "some-session-id"} '
| jq .
# response from service
{
" content " : " The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models). " ,
" sourceLinks " : [
]
}

