vector search api
1.0.0
프로젝트를 설정하고 실행하려면 다음 단계를 따르세요.
PostgreSQL 설치
admin 으로 변경하십시오.프로젝트 구성
config 폴더로 이동합니다.db.js 열고 라인 3을 업데이트합니다.mayanksharma 에서 시스템 사용자 이름으로 변경합니다.데이터베이스 설정
CREATE EXTENSION vector;올라마 설치
ollama pull snowflake-arctic-embed프로젝트 종속성 설치
npm install
node server.jsREST 클라이언트 확장 설치
API 테스트
api.http 파일을 열어 API 엔드포인트를 테스트합니다. {
"query" : " your_search_query "
}{
"title" : " magazine_title " ,
"author" : " author_name " ,
"category" : " magazine_category " ,
"content" : " magazine_content "
}저는 PostgreSQL을 pgVector(임베딩 벡터 저장) 및 tsVector(콘텐츠 텍스트 저장)와 함께 사용했습니다.
요구 사항: 100만 건의 기록에서 검색
콘텐츠 임베딩에 대한 벡터 검색을 위해 HNSW(Hierarchical Navigable Small Worlds) 인덱스를 추가했습니다. 이유: 검색에는 높은 재현율이 필요하므로 hnsw가 ivfflat보다 우수합니다.
제목, 저자 및 내용에 대한 색인이 추가되었습니다.
로드 시간을 줄이기 위해 페이지 매김이 추가되었습니다.
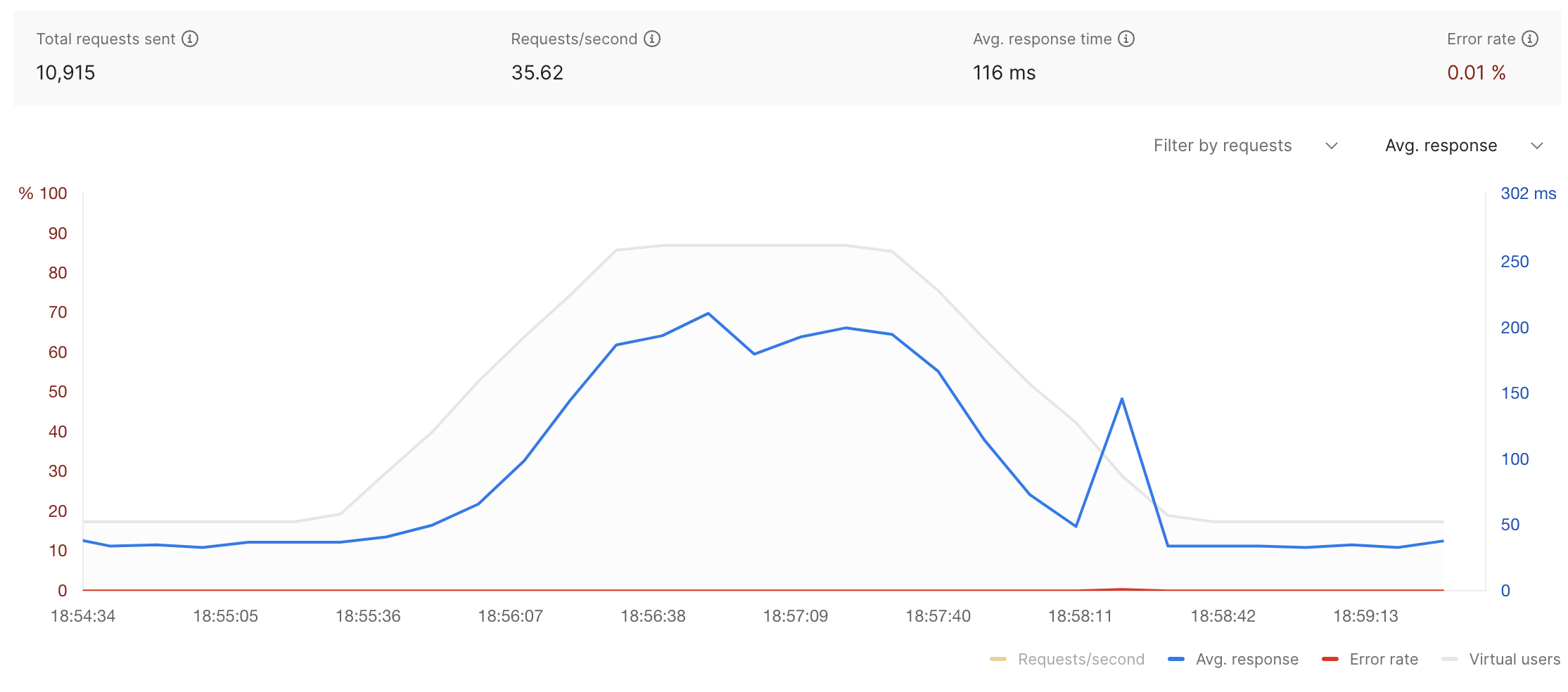
프로필: 피크
가상 사용자: 20
테스트 시간: 5분
엔드포인트 히트: POST /api/v1/magazine/hybridsearch/1 ("glasgow", "game", "business", "shubham", "food" 및 "modern")
전송된 총 요청 수: 10,915
초당 요청: 35.62
평균 응답 시간: 116ms
텍스트 검색과 벡터 검색을 위한 두 가지 개별 서비스가 사용됩니다.
임베딩은 경량인 Meta llama "snowflake-arctic-embed" 모델에 의해 생성됩니다.
1단계: 벡터 및 전체 텍스트 검색 결과의 공통 개체가 먼저 표시됩니다.
2단계: 텍스트 검색만으로 개체가 이어지며,
3단계: 벡터 검색의 나머지 개체.
쿼리: 벡터 "glasgow", "Scotland write in content"가 있는 "Celtic Feast Journal"을 반환합니다.
쿼리: 벡터 "shortbread"는 "shortbread"가 "scotland"와 관련되어 있으므로 "Celtic Feast Journal"을 반환합니다.
쿼리: 키워드/전체 텍스트 "shubham", 작성자 이름이 "Shubham Thorve"인 "Physics Refresher"를 반환합니다.
쿼리: 키워드/전체 텍스트 "mayank", 작성자 이름이 "Mayank Khurana"인 "Digit Gaming"을 반환합니다.
쿼리: 키워드/전체 텍스트 "월", "이번 달 비디오 게임에 관한 모든 것"이라는 콘텐츠가 포함된 "달랄 스트리트 저널"을 반환합니다.
/model 에 있습니다.

