cassandra lucene index
2.1.20.0
Stratio Cassandra에서 파생된 Stratio의 Cassandra Lucene Index는 인덱스 기능을 확장하여 전체 텍스트 검색 기능과 무료 다변수, 지리공간 및 양측 시간 검색을 포함하여 ElasticSearch 또는 Solr과 같은 거의 실시간 검색을 제공하는 Apache Cassandra용 플러그인입니다. 이는 클러스터의 각 노드가 자체 데이터를 색인화하는 Cassandra 보조 색인의 Apache Lucene 기반 구현을 통해 달성됩니다. Stratio의 Cassandra 인덱스는 Stratio의 BigData 플랫폼의 기반이 되는 핵심 모듈 중 하나입니다.
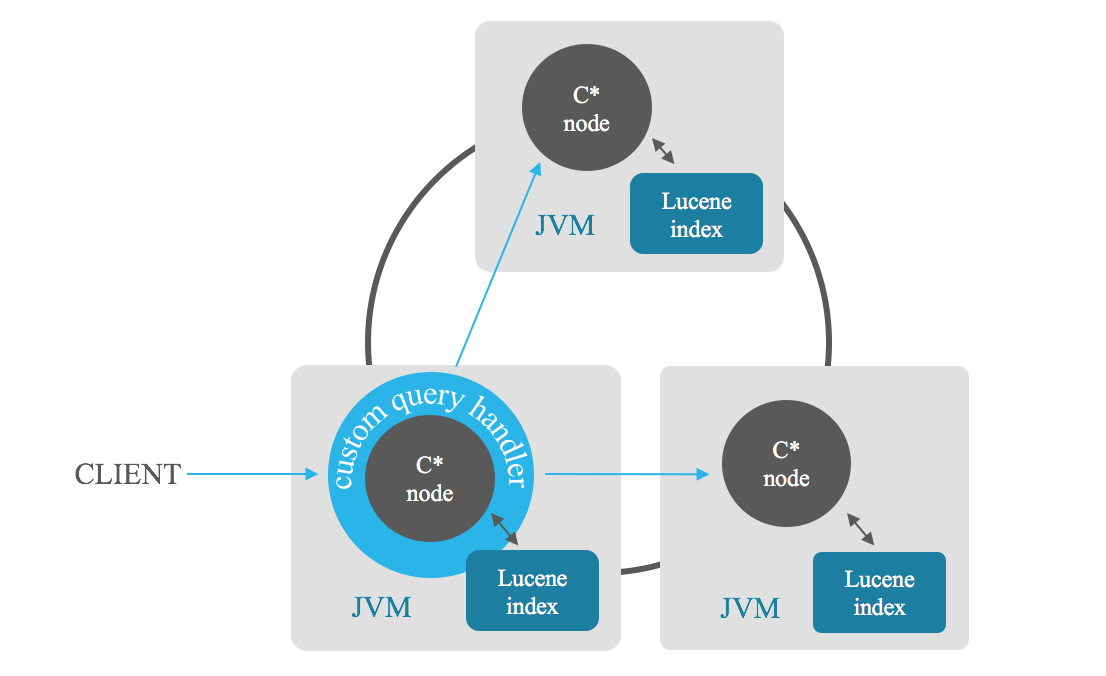
색인 관련성 검색을 사용하면 검색을 충족하는 n개의 더 관련성 높은 결과를 검색할 수 있습니다. 코디네이터 노드는 클러스터의 각 노드에 검색을 보내고 각 노드는 n 개의 최상의 결과를 반환한 다음 코디네이터는 이러한 부분 결과를 결합하여 전체 스캔을 피하면서 n 개의 최상의 결과를 제공합니다. 필드 조합을 기반으로 정렬할 수도 있습니다.
기본 키 및 컬렉션의 셀을 포함하여 테이블의 모든 셀을 인덱싱할 수 있습니다. 넓은 행도 지원됩니다. 토큰/키 범위를 스캔하고, 추가 CQL3 절을 적용하고, 필터링된 결과를 페이지로 표시할 수 있습니다.
인덱스 필터링 검색은 Apache Hadoop 또는 더 나은 Apache Spark와 같은 MapReduce 프레임워크를 사용하여 Cassandra에 저장된 데이터를 분석할 때 강력한 도움이 됩니다. 작업 입력에 Lucene 필터를 추가하면 전체 스캔을 방지하여 처리할 데이터 양을 크게 줄일 수 있습니다.
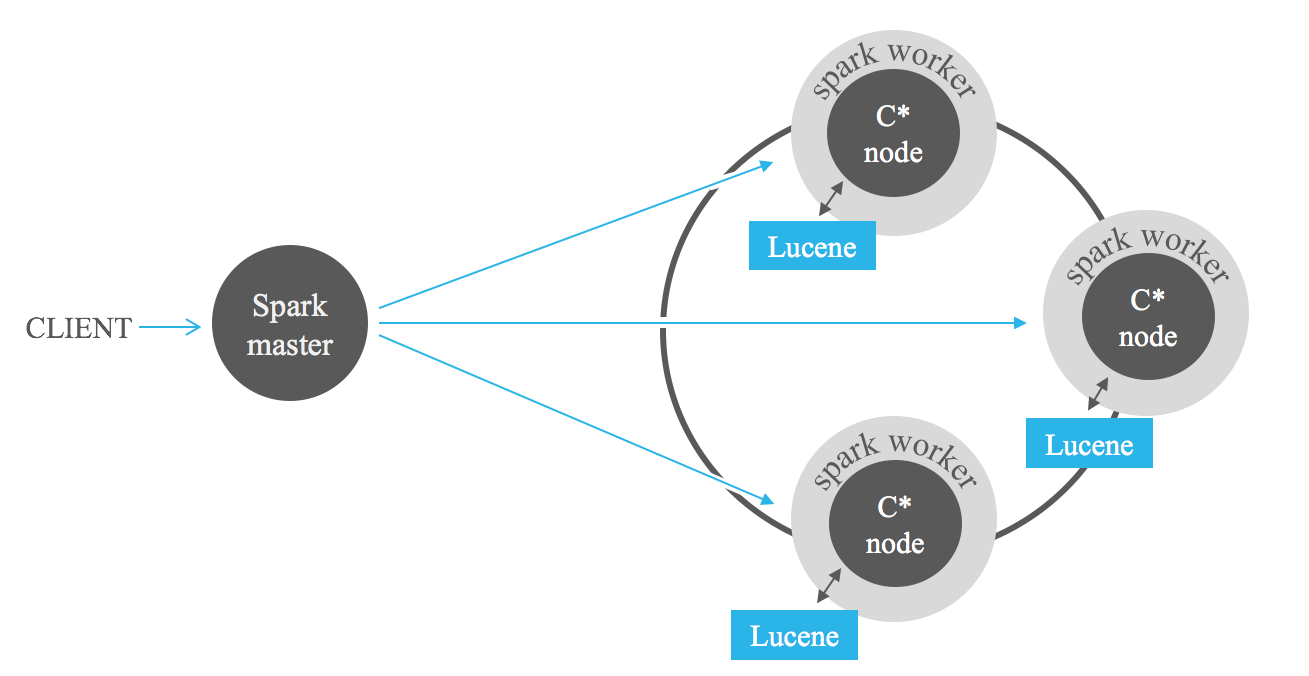
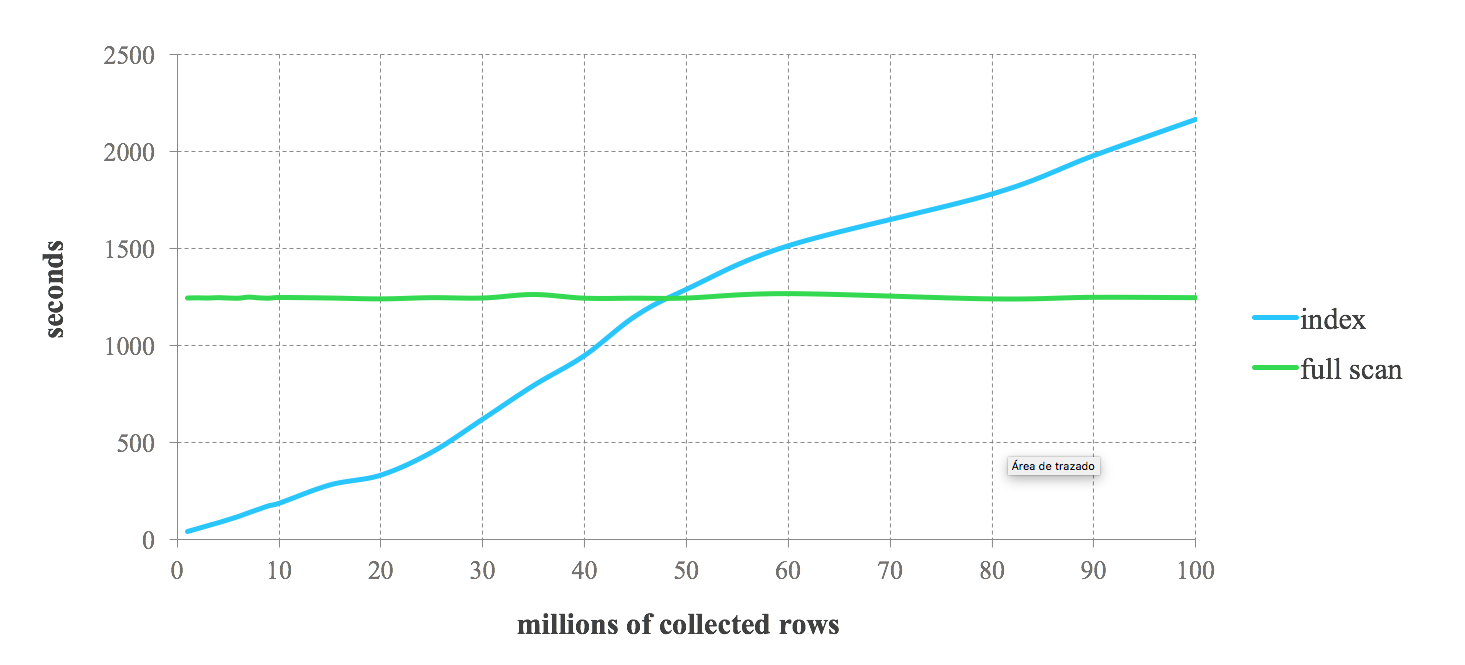
다음 벤치마크 결과는 Lucene 인덱스를 Spark와 결합할 때 예상되는 성능에 대한 아이디어를 제공합니다. 저장된 데이터의 1%부터 100%까지 요청하는 연속적인 쿼리를 수행합니다. 강력하게 필터링된 데이터를 요청하는 쿼리에 대한 인덱스의 성능이 뛰어난 것을 볼 수 있습니다. 그러나 덜 제한적인 쿼리에서는 성능이 저하됩니다. 쿼리에서 반환되는 레코드 수가 증가할수록 인덱스가 전체 스캔보다 느려지는 지점에 도달합니다. 따라서 Spark 작업에서 인덱스를 사용하기로 한 결정은 쿼리 선택성에 따라 달라집니다. 두 접근 방식 간의 균형은 특정 사용 사례에 따라 다릅니다. 일반적으로 저장된 데이터의 25% 이하를 검색하는 작업의 경우 Lucene 인덱스와 Spark를 결합하는 것이 좋습니다.
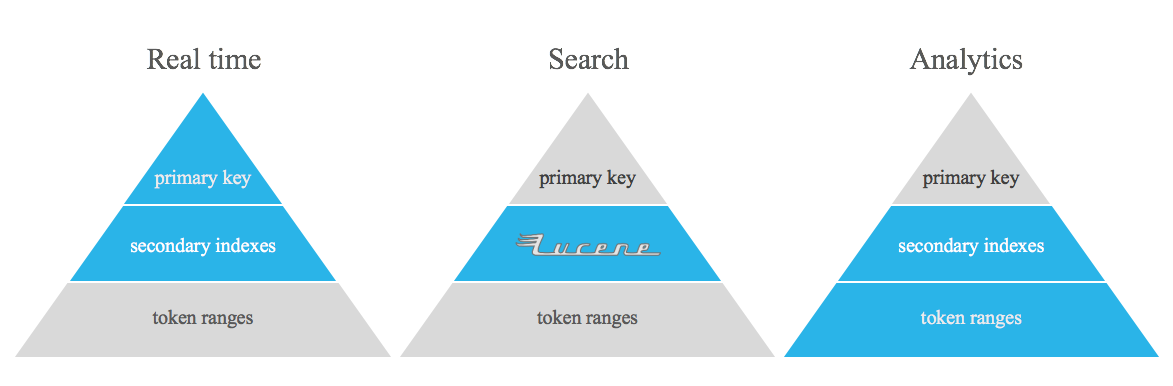
이 프로젝트는 Apache Cassandra 비정규화된 테이블, 역 인덱스 및/또는 보조 인덱스를 대체하기 위한 것이 아닙니다. 이는 Apache Cassandra의 기본 기능을 사용하여 해결하기 어려운 일종의 쿼리를 수행하여 실시간과 분석 사이의 격차를 메우는 도구일 뿐입니다.
더 자세한 정보는 Stratio의 Cassandra Lucene Index 문서에서 확인할 수 있습니다.
Cassandra에 Lucene 검색 기술 통합은 다음을 제공합니다.
Stratio의 Cassandra Lucene Index 및 Lucene 검색 기술과의 통합은 다음을 제공합니다.
아직 지원되지 않음:
counter 열Stratio의 Cassandra Lucene Index는 Apache Cassandra용 플러그인으로 배포됩니다. 따라서 플러그인이 포함된 JAR을 빌드하고 이를 Cassandra의 클래스 경로에 추가하기만 하면 됩니다.
git clone http://github.com/Stratio/cassandra-lucene-indexcd cassandra-lucene-indexgit checkout ABCXmvn clean packagecp plugin/target/cassandra-lucene-index-plugin-*.jar <CASSANDRA_HOME>/lib/특정 Cassandra Lucene 인덱스 버전은 특정 Apache Cassandra 버전을 대상으로 합니다. 따라서 cassandra-lucene-index ABCX는 Apache Cassandra ABC와 함께 사용하는 것을 목표로 합니다(예: cassandra:3.0.7의 경우 cassandra-lucene-index:3.0.7.1). 프로덕션 준비 릴리스는 버전 태그(예: 3.0.6.3)이므로 프로덕션에서 브랜치-X나 마스터 브랜치를 사용하지 마십시오.
또는 Cassandra 설치 경로를 지정하여 이 Maven 프로필을 사용하여 패치를 수행할 수도 있습니다. 이 작업은 CASSANDRA_HOME/lib/ 디렉터리에서 이전 플러그인의 JAR 버전도 삭제합니다.
mvn clean package -Ppatch -Dcassandra_home= < CASSANDRA_HOME >설치된 Cassandra 버전이 없는 경우 Maven이 적절한 Apache Cassandra 버전을 다운로드하고 패치할 수 있는 대체 프로필도 있습니다.
mvn clean package -Pdownload_and_patch -Dcassandra_home= < CASSANDRA_HOME >이제 Cassandra를 실행하고 Cassandra 쿼리 언어를 사용하여 몇 가지 테스트를 수행할 수 있습니다.
< CASSANDRA_HOME > /bin/cassandra -f
< CASSANDRA_HOME > /bin/cqlsh Lucene의 인덱스 파일은 Cassandra의 인덱스 파일과 동일한 디렉터리에 저장됩니다. 기본 데이터 디렉터리는 /var/lib/cassandra/data 이며, 각 인덱스는 인덱스된 열 계열의 SSTable 옆에 배치됩니다.
지리적 모양 검색을 사용하는 경우 JTS jar를 포함해야 한다는 점을 기억하세요.
Apache Cassandra에 대한 자세한 내용은 해당 설명서를 참조하세요.
트윗을 저장하기 위해 다음 테이블을 생성합니다.
CREATE KEYSPACE demo
WITH REPLICATION = { ' class ' : ' SimpleStrategy ' , ' replication_factor ' : 1 };
USE demo;
CREATE TABLE tweets (
id INT PRIMARY KEY ,
user TEXT ,
body TEXT ,
time TIMESTAMP ,
latitude FLOAT,
longitude FLOAT
);이제 다음 명령문을 사용하여 사용자 정의 Lucene 인덱스를 생성할 수 있습니다.
CREATE CUSTOM INDEX tweets_index ON tweets ()
USING ' com.stratio.cassandra.lucene.Index '
WITH OPTIONS = {
' refresh_seconds ' : ' 1 ' ,
' schema ' : ' {
fields: {
id: {type: "integer"},
user: {type: "string"},
body: {type: "text", analyzer: "english"},
time: {type: "date", pattern: "yyyy/MM/dd"},
place: {type: "geo_point", latitude: "latitude", longitude: "longitude"}
}
} '
}; 그러면 지정된 유형으로 테이블의 모든 열이 색인화되고 초당 한 번씩 새로 고쳐집니다. 또는 일관성이 ALL 인 빈 검색을 사용하여 모든 인덱스 샤드를 명시적으로 새로 고칠 수 있습니다.
CONSISTENCY ALL
SELECT * FROM tweets WHERE expr(tweets_index, ' {refresh:true} ' );
CONSISTENCY QUORUM이제 특정 날짜 범위 내의 트윗을 검색하려면 다음을 수행하세요.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"}
} ' );관련된 인덱스 샤드를 명시적으로 새로 고치도록 동일한 검색을 수행할 수 있습니다.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
refresh: true
} ' ) limit 100 ;이제 앞서 언급한 날짜 범위 내에서 본문 필드에 "빅 데이터가 조직에 제공합니다"라는 문구가 포함된 상위 100개의 관련 트윗을 검색하려면 다음을 수행하세요.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: {type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;이름이 "a"로 시작하는 사용자가 작성한 트윗만 가져오도록 검색을 구체화하려면 다음을 수행하세요.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1}
} ' ) LIMIT 100 ;최근에 필터링된 100개의 결과를 얻으려면 정렬 옵션을 사용할 수 있습니다.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;이전 검색은 지리적 위치에 가깝게 생성된 트윗으로 제한될 수 있습니다.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: {field: "time", reverse: true}
} ' ) limit 100 ;지리적 위치까지의 거리를 기준으로 결과를 정렬하는 것도 가능합니다.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) limit 100 ;마지막으로, 클러스터 노드의 하위 집합만 적중하는 방식으로 검색을 특정 토큰 범위나 파티션으로 라우팅하여 귀중한 리소스를 절약할 수 있습니다.
SELECT * FROM tweets WHERE expr(tweets_index, ' {
filter: [
{type: "range", field: "time", lower: "2014/04/25", upper: "2014/05/01"},
{type: "prefix", field: "user", value: "a"},
{type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"}
],
query: {type: "phrase", field: "body", value: "big data gives organizations", slop: 1},
sort: [
{field: "time", reverse: true},
{field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328}
]
} ' ) AND TOKEN(id) >= TOKEN( 0 ) AND TOKEN(id) < TOKEN( 10000000 ) limit 100 ;마지막은 Hadoop, Spark 및 기타 MapReduce 프레임워크 지원의 기초입니다.
포괄적인 Stratio의 Cassandra Lucene Index 문서를 참조하세요.


