SESREC SIGIR 2023
1.0.0
이는 PyTorch를 기반으로 한 SIGIR 2023 논문 "검색이 권장 사항을 충족할 때: 권장 사항을 위한 분리된 검색 표현 학습"의 공식 구현입니다.
[arXiv] [ACM 디지털 라이브러리]
SESRec의 주요 구현은 models/SESRec.py 파일에서 찾을 수 있습니다. SESRec의 아키텍처는 다음 그림에 나와 있습니다.
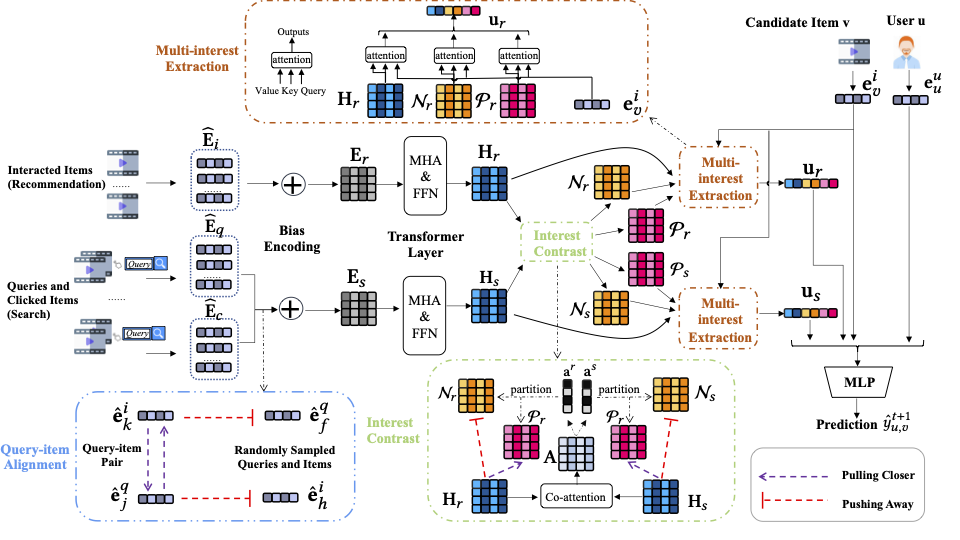
자주 묻는 질문 몇 가지를 FAQ.md 파일에 정리했습니다.
실험을 재현하려면 다음 지침을 확인하세요.
두 데이터 세트 모두에 대한 SESRec의 모든 하이퍼 매개변수 설정은 config/SESRec_commercial.yaml 및 config/SESRec_amazon.yaml 파일에서 찾을 수 있습니다. 두 데이터 세트의 설정은 config/const.py 파일에서 찾을 수 있습니다.
Kuaishou 데이터세트는 독점 산업 데이터세트이므로 여기서는 바로 사용할 수 있는 Amazon(Kindle Store) 데이터세트의 데이터를 공개합니다. 바로 사용할 수 있는 데이터는 링크에서 다운로드할 수 있습니다.
이 링크에서 데이터를 다운로드하고 압축을 해제하세요. data 폴더에 데이터 파일을 넣습니다.
우리의 실험은 다음 Python 패키지를 사용하여 수행되었습니다.
python==3.8.13
torch==1.9.0
numpy==1.23.2
pandas==1.4.4
scikit-learn==1.1.2
tqdm==4.64.0
PyYAML==6.0
명령줄에서 코드를 실행합니다.
python3 main.py --name SESRec --workspace ./workspace/SESRec --gpu_id 0 --epochs 30 --model SESRec --batch_size 256 --dataset_name amazon 학습 후 로그 파일(예: workspace/SESRec/log/default.log 을 확인하세요.
우리는 다음과 같은 환경을 기반으로 실험을 진행했습니다.
이 저장소를 사용하는 경우 우리 논문을 인용해 주세요.
@inproceedings{si2023SESRec,
author = {Si, Zihua and Sun, Zhongxiang and Zhang, Xiao and Xu, Jun and Zang, Xiaoxue and Song, Yang and Gai, Kun and Wen, Ji-Rong},
title = {When Search Meets Recommendation: Learning Disentangled Search Representation for Recommendation},
year = {2023},
isbn = {9781450394086},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3539618.3591786},
doi = {10.1145/3539618.3591786},
booktitle = {Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval},
pages = {1313–1323},
numpages = {11},
keywords = {search, contrastive learning, disentanglement learning, recommendation},
location = {Taipei, Taiwan},
series = {SIGIR '23}
}
질문이 있으시면 언제든지 이메일 [email protected] 또는 GitHub 문제를 통해 문의해 주세요. 감사해요!


