ustore
v0.13.12
![]()
![]()
![]()
![]()
![]()
![]()
YouTube 소개 • Discord 채팅 • 전체 문서
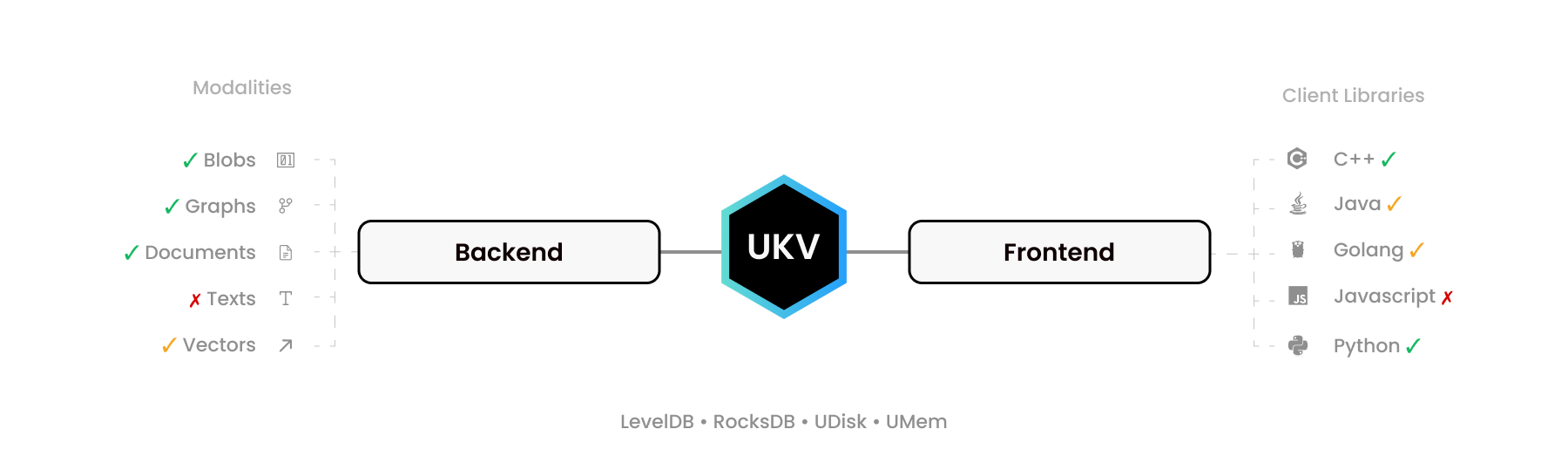
UStore 설치는 매우 쉽고 사용법은 Python dict 만큼 간단합니다.
$ pip install ukv
$ python
from ukv import umem
db = umem . DataBase ()
db . main [ 42 ] = 'Hi' 우리는 메모리 내 임베디드 트랜잭션 데이터베이스를 생성하고 main 컬렉션에 하나의 항목을 추가했습니다. 디스크에 있는 데이터를 선호하시나요? 한 줄을 변경하십시오.
from ukv import rocksdb
db = rocksdb . DataBase ( '/some-folder/' )원격 UStore 서버에 연결하시겠습니까? UStore에는 Apache Arrow Flight RPC 인터페이스가 함께 제공됩니다!
from ukv import flight_client
db = flight_client . DataBase ( 'grpc://0.0.0.0:38709' ) NetworkX와 유사한 MultiDiGraph 저장하고 있습니까? 아니면 팬더와 같은 DataFrame ?
db = rocksdb . DataBase ()
users_table = db [ 'users' ]. table
users_table . merge ( pd . DataFrame ([
{ 'id' : 1 , 'name' : 'Lex' , 'lastname' : 'Fridman' },
{ 'id' : 2 , 'name' : 'Joe' , 'lastname' : 'Rogan' },
]))
friends_graph = db [ 'friends' ]. graph
friends_graph . add_edge ( 1 , 2 )
assert friends_graph . has_edge ( 1 , 2 ) and
friends_graph . has_node ( 1 ) and
friends_graph . number_of_edges ( 1 , 2 ) == 1함수 호출은 동일해 보일 수 있지만 기본 구현은 원격 시스템의 영구 메모리 어딘가에 있는 수백 테라바이트의 데이터를 처리할 수 있습니다.
다른 사람이 해당 컬렉션을 동시에 업데이트하고 있나요? 일관성을 보장하기 위해 작업을 묶으세요!
db = rocksdb . DataBase ()
with db . transact () as txn :
txn [ 'users' ]. table . merge (...)
txn [ 'friends' ]. graph . add_edge ( 1 , 2 )지금까지 우리는 UStore의 핵심만을 다루었습니다. 당신은 그것을 사용할 수 있습니다 ...
하지만 UStore는 그 이상을 할 수 있습니다. 지도는 다음과 같습니다.
## 기본 사용법
UStore는 단순한 데이터베이스가 아니라 "데이터베이스 구축" 툴킷이자 NoSQL 잠재적 트랜잭션 데이터베이스를 위한 개방형 표준으로, "생성, 읽기, 업데이트, 삭제" 작업을 위한 무복사 바이너리 인터페이스, 줄여서 CRUD를 정의합니다.
몇 가지 간단한 C99 헤더는 거의 모든 기본 스토리지 엔진을 수많은 고급 언어 드라이버에 연결하여 바이너리 문자열 값에 대한 지원을 그래프, 유연한 스키마 문서 및 기타 형식으로 확장하여 MongoDB, Neo4J, Pinecone 및 ElasticSearch를 대체할 수 있습니다. 단일 ACID 트랜잭션 시스템을 사용합니다.
예를 들어 Redis는 유사한 목표를 가진 RediSearch, RedisJSON 및 RedisGraph를 제공합니다. UStore는 더 나은 기능을 제공하므로 FoundationDB와 같이 선호하는 KVS(Key-Value Store)를 내장형, 독립형 또는 샤딩형으로 추가하여 기능을 배가할 수 있습니다.
바이너리 대형 객체(Binary Large Object)는 UStore 내에 배치될 수 있습니다. 성능은 사용된 기본 기술에 따라 크게 달라집니다. 메모리 내 UCSet은 가장 빠르지만 더 큰 개체에는 가장 적합하지 않습니다. 영구 UDisk는 적절하게 구성되면 파일 시스템 계층을 포함하여 Linux 커널을 완전히 우회하여 블록 장치의 주소를 직접 지정할 수 있습니다.
고급 서버의 최신 영구 IO는 SPDK와 같은 사용자 공간 드라이버를 기반으로 구축된 경우 소켓당 100GB/s를 초과할 수 있습니다. 이는 고급 RAM의 실제 처리량에 가깝고 데이터베이스 사용 사례에서 흔하지 않은 새로운 가능성을 열어줍니다. 이제 MinIO와 같은 별도의 개체 저장소를 사용하는 대신 기가바이트 크기의 비디오 파일을 메타데이터 바로 옆에 있는 ACID 트랜잭션 데이터베이스에 넣을 수 있습니다.
JSON은 요즘 가장 일반적으로 사용되는 문서 형식입니다. UStore 문서 컬렉션은 JSON은 물론 MongoDB에서 사용하는 MessagePack 및 BSON을 지원합니다.

UStore는 아직 수평적으로 확장되지 않지만 훨씬 더 높은 단일 노드 성능을 제공하며 오픈 소스 simdjson 및 yyjson 라이브러리 덕분에 많은 코어 시스템에서 거의 선형적인 수직 확장성을 제공합니다. 또한 데이터와 상호 작용하기 위해 MQL과 같은 사용자 정의 쿼리 언어가 필요하지 않습니다. 대신 우리는 벤더 잠금을 방지하기 위해 개방형 RFC 표준을 우선시합니다.
Neo4J와 같은 최신 그래프 데이터베이스는 대규모 워크로드로 인해 어려움을 겪고 있습니다. 너무 많은 RAM이 필요하며 알고리즘은 한 번에 한 항목씩 데이터를 관찰합니다. 우리는 두 가지 측면 모두에서 최적화합니다.
Pinecone, Milvus 및 USearch와 같은 기능 저장소 및 벡터 데이터베이스는 벡터 검색을 위한 독립형 색인을 제공합니다. UStore는 이를 문서 및 그래프와 동등한 별도의 양식으로 구현합니다. 특징:
Python용 UStore와 C++용 UStore는 매우 다르게 보입니다. 우리의 Python SDK는 Pandas 및 NetworkX와 같은 다른 Python 라이브러리를 모방합니다. 마찬가지로 C++ 라이브러리는 C++ 개발자가 기대하는 인터페이스를 제공합니다.
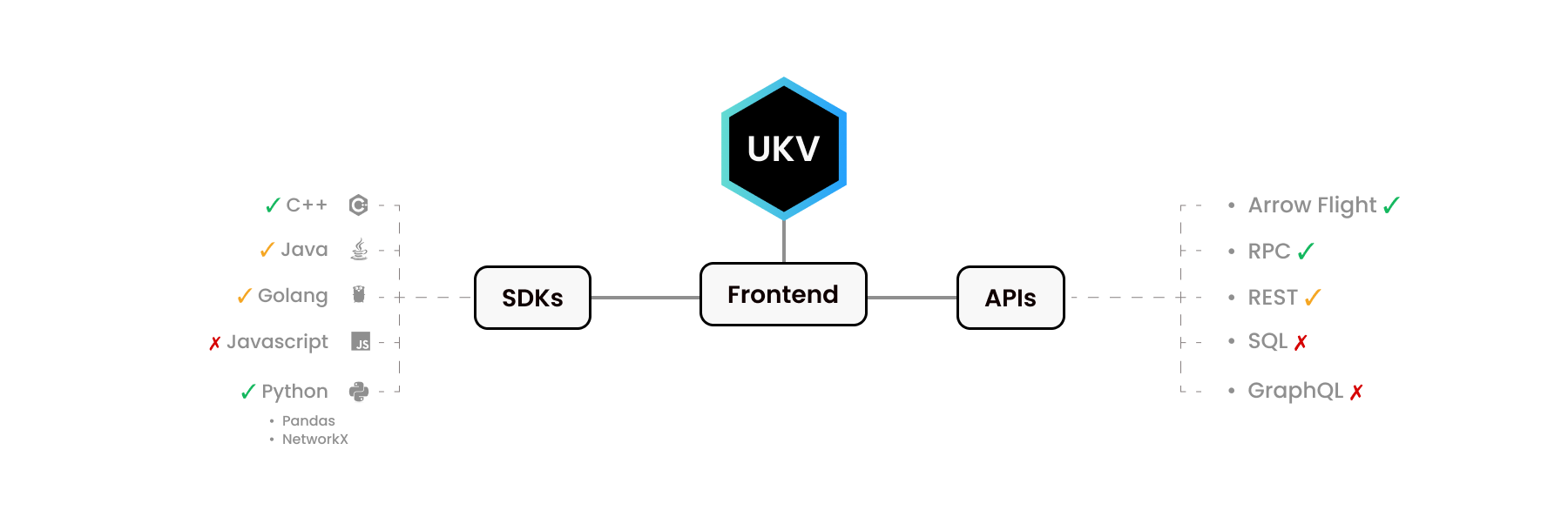
우리가 알고 있듯이 사람들은 다양한 목적을 위해 다양한 언어를 사용합니다. 일부 C 수준 기능은 일부 언어에 대해 구현되지 않습니다. 수요가 없었거나 아직 도달하지 못했기 때문입니다.
| 이름 | 거래 | 컬렉션 | 배치 | 문서 | 그래프 | 사본 |
|---|---|---|---|---|---|---|
| C99 표준 | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| C++ SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0 |
| 파이썬 SDK | ✓ | ✓ | ✓ | ✓ | ✓ | 0-1 |
| 고랭 SDK | ✓ | ✓ | ✓ | ✗ | ✗ | 1 |
| 자바 SDK | ✓ | ✓ | ✗ | ✗ | ✗ | 1 |
| 화살표 비행 API | ✓ | ✓ | ✓ | ✓ | ✓ | 0-2 |
일부 프런트엔드는 주변에 전체 생태계를 가지고 있습니다! 예를 들어 Apache Arrow Flight API에는 C, C++, C#, Go, Java, JavaScript, Julia, MATLAB, Python, R, Ruby 및 Rust를 위한 자체 드라이버가 있습니다.
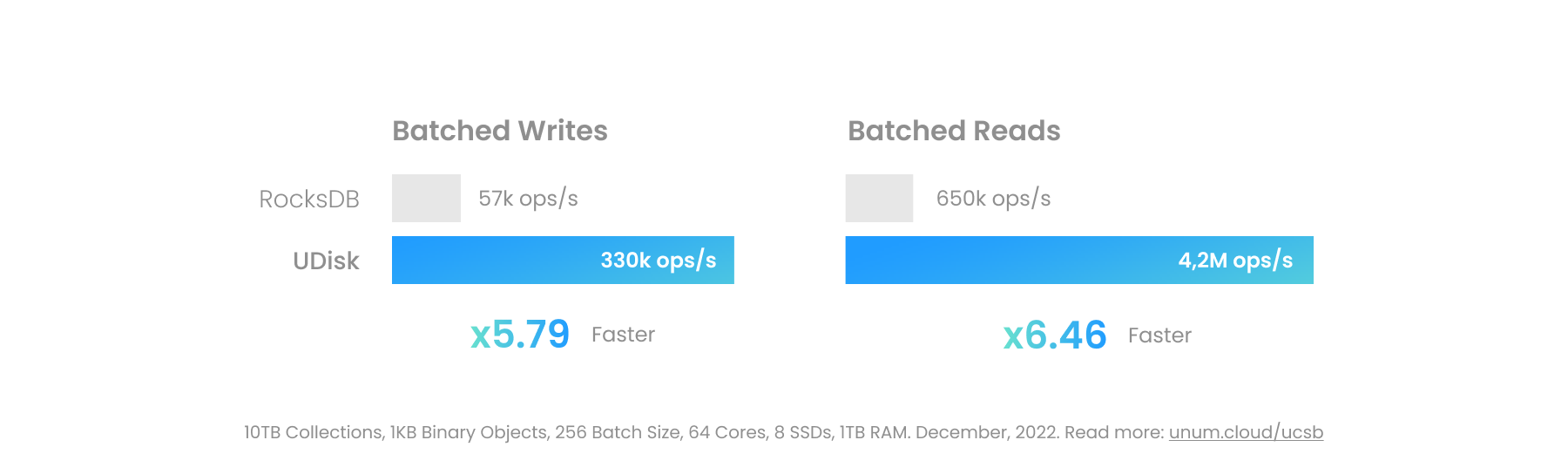
다음 엔진은 거의 서로 바꿔서 사용할 수 있습니다. 역사적으로 LevelDB가 첫 번째였습니다. RocksDB는 기능과 성능이 향상되었습니다. 현재는 DBMS 스타트업 절반의 기반 역할을 하고 있습니다.
| 레벨DB | RocksDB | UDisk | UC세트 | |
|---|---|---|---|---|
| 속도 | 1x | 2배 | 10배 | 30배 |
| 지속성 있는 | ✓ | ✓ | ✓ | ✗ |
| 거래 | ✗ | ✓ | ✓ | ✓ |
| 블록 장치 지원 | ✗ | ✗ | ✓ | ✗ |
| 암호화 | ✗ | ✗ | ✓ | ✗ |
| 시계 | ✗ | ✓ | ✓ | ✓ |
| 스냅샷 | ✓ | ✓ | ✓ | ✗ |
| 무작위 샘플링 | ✗ | ✗ | ✓ | ✓ |
| 대량 열거 | ✗ | ✗ | ✓ | ✓ |
| 명명된 컬렉션 | ✗ | ✓ | ✓ | ✓ |
| 오픈 소스 | ✓ | ✓ | ✗ | ✓ |
| 호환성 | 어느 | 어느 | 리눅스 | 어느 |
| 유지관리자 | 페이스북 | 우눔 | 우눔 |
UCSet과 UDisk는 모두 Unum에서 설계하고 유지 관리합니다. 둘 다 기능이 완벽하지만 대안이 제공하는 가장 중요한 기능은 성능입니다. 기억력이 빠른 것은 쉽습니다. UCSet의 핵심 로직은 템플릿 기반 헤더 전용 ucset 라이브러리에서 찾을 수 있습니다.
UDisk를 설계하는 것은 7년에 걸친 노력보다 훨씬 더 어려운 일이었습니다. 여기에는 새로운 트리형 구조의 발명, io_uring 통한 부분 커널 우회 구현, SPDK 통한 완전한 우회, CUDA GPU 가속, 심지어 사용자 정의 내부 파일 시스템까지 포함되었습니다. UDisk는 병렬 아키텍처와 커널 우회를 염두에 두고 처음부터 설계된 최초의 엔진입니다 .
원자성은 항상 보장됩니다. 비트랜잭션 쓰기에서도 모든 업데이트가 통과되거나 모두 실패합니다.
일관성은 가능한 가장 엄격한 형식으로 구현됩니다. 즉, "엄격한 직렬화 가능성"은 다음을 의미합니다.
그러나 기본 동작은 특정 작업 수준에서 조정할 수 있습니다. 이를 위해 ::ustore_option_transaction_dont_watch_k ustore_transaction_init() 또는 트랜잭션 읽기/쓰기 작업에 전달하여 스테이징 중 일관성 검사를 제어할 수 있습니다.
| 읽기 | 쓰기 | |
|---|---|---|
| 머리 | 엄격한 직렬 | 엄격한 직렬 |
| 스냅샷을 통한 거래 | 연속물 | 엄격한 직렬 |
| 스냅샷이 없는 거래 | 엄격한 직렬 | 엄격한 직렬 |
| 시계 없이 거래 | 엄격한 직렬 | 잇달아 일어나는 |
이 주제가 처음이라면 일관성에 대한 Jepsen.io 블로그를 확인하세요.
| 읽기 | 쓰기 | |
|---|---|---|
| 스냅샷을 통한 거래 | ✓ | ✓ |
| 스냅샷이 없는 거래 | ✗ | ✓ |
내구성은 정의에 따라 메모리 내 시스템에 적용되지 않습니다. 하이브리드 또는 영구 시스템에서는 기본적으로 비활성화하는 것을 선호합니다. KVS를 기반으로 구축된 거의 모든 DBMS는 자체 내구성 메커니즘을 구현하는 것을 선호합니다. 세 개의 개별 미리 쓰기 로그가 존재할 수 있는 분산 데이터베이스에서는 더욱 그렇습니다.
여전히 내구성이 필요한 경우 선택적 플래그를 사용하여 커밋에 대한 쓰기를 플러시하세요. C 드라이버에서는 ::ustore_option_write_flush_k 플래그를 사용하여 ustore_transaction_commit() 호출합니다.
전체 DBMS는 100MB 미만의 Docker 이미지에 맞습니다. 다음 스크립트를 실행하여 컨테이너를 가져와 실행하여 포트 38709 에 Apache Arrow Flight 서버를 노출합니다. 클라이언트 SDK도 기본적으로 동일한 포트를 통해 통신합니다.
docker run -d --rm --name ustore-test -p 38709:38709 unum/ustore기본 구성 파일은 다음을 사용하여 검색할 수 있습니다.
cat /var/lib/ustore/config.json연결하고 테스트하는 가장 간단한 방법은 다음 명령입니다.
python ...사전 패키지된 UStore 이미지는 여러 플랫폼에서 사용할 수 있습니다.
주저하지 말고 UStore를 상용화하고 재배포하세요.
데이터베이스 튜닝은 과학만큼이나 예술입니다. RocksDB와 같은 프로젝트는 동작을 최적화하기 위해 수십 개의 손잡이를 제공합니다. 특수한 구성 파일을 기본 엔진으로 전달할 수 있습니다.
{
"version" : " 1.0 " ,
"directory" : " ./tmp/ "
}우리는 또한 80%의 사용자에게 충분한 더 간단한 절차를 가지고 있습니다. 이는 여러 장치나 디렉터리를 활용하거나 특수 엔진 구성을 전달하도록 확장될 수 있습니다.
{
"version" : " 1.0 " ,
"directory" : " /var/lib/ustore " ,
"data_directories" : [
{
"path" : " /dev/nvme0p0/ " ,
"max_size" : " 100GB "
},
{
"path" : " /dev/nvme1p0/ " ,
"max_size" : " 100GB "
}
],
"engine" : {
"config_file_path" : " ./engine_rocksdb.ini " ,
}
}데이터베이스 컬렉션은 JSON 파일을 사용하여 구성할 수도 있습니다.
현재 버전에서는 64비트 부호 있는 정수가 사용됩니다. [0, 2^63) 범위의 고유 키를 허용합니다. UUID를 사용한 128비트 빌드가 출시될 예정이지만 가변 길이 키는 권장되지 않습니다. 왜 그렇습니까?
가변 길이 키를 사용하면 키-값 저장소 설계에 많은 제한이 적용됩니다. 첫째, 이는 최신 하이퍼스칼라 CPU의 성능 저하 요인인 느린 문자별 비교를 의미합니다. 둘째, 탐색에 필요한 메타데이터를 최소화하기 위해 키와 값을 디스크에 강제로 결합합니다. 마지막으로, "영구 메모리 할당자"로서 KVS에 대한 간단한 논리적 관점을 위반하여 KVS에 더 많은 책임을 부여합니다.
문자열 키를 처리하는 데 권장되는 접근 방식은 다음과 같습니다.
이로 인해 문자열에서 정수 표현으로의 단일 변환 지점이 발생하고 대부분의 시스템이 원활하게 유지되고 C 수준 인터페이스가 이전보다 더 단순해집니다.
현재로서는 4GB 이하의 값만 처리할 수 있습니다. 왜? 키-값 저장소는 일반적으로 빈도가 높은 작업을 위한 것입니다. 최신 하드웨어에서는 4GB 이상의 파일에 액세스하고 수정하는 것이 불가능한 경우가 많습니다(초당 수천 번). 따라서 우리는 더 작은 길이의 유형을 고수하여 Apache Arrow 표현을 약간 더 쉽게 사용하고 KVS가 인덱스를 더 잘 압축할 수 있도록 합니다.
우리의 개발 로드맵은 공개되어 있으며 GitHub 저장소 내에서 호스팅됩니다. 향후 작업은 다음과 같습니다.
여기 문서에서 전체 로드맵을 읽어보세요.


