uFuzzy
1.0.17
형편없는 작고 효율적인 퍼지 검색입니다. 이게 내 퍼지야?. 비슷한 것이 많지만 이것은 내 것입니다. 1
uFuzzy는 상대적으로 짧은 검색 문구(바늘)를 짧고 중간 문구(건초 더미)의 큰 목록과 일치시키도록 설계된 퍼지 검색 라이브러리입니다. 이는 보다 관대한 String.includes()로 가장 잘 설명될 수 있습니다. 일반적인 응용 프로그램에는 목록 필터링, 자동 완성/제안, 제목, 이름, 설명, 파일 이름 및 기능 검색이 포함됩니다.
uFuzzy의 기본 MultiInsert 모드에서 각 일치 항목에는 바늘의 모든 영숫자 문자가 동일한 순서로 포함되어야 합니다. SingleError 모드에서는 각 용어에서 단일 오타가 허용됩니다(Damerau–Levenshtein 거리 = 1). .search() API는 순서가 잘못된 용어를 효율적으로 일치시키고 여러 하위 문자열 제외(예: fruit -green -melon ) 및 영숫자가 아닌 문자가 포함된 정확한 용어(예: "C++" , "$100" , "#hashtag" 를 지원합니다. "#hashtag" ). 올바르게 잡으면 여러 개체 속성과 효율적으로 일치시킬 수도 있습니다.
Array.sort() 사용하여 추론하고 사용자 정의할 수 있습니다. 이해할 수 있는 복합적인 블랙박스 "점수"는 없습니다.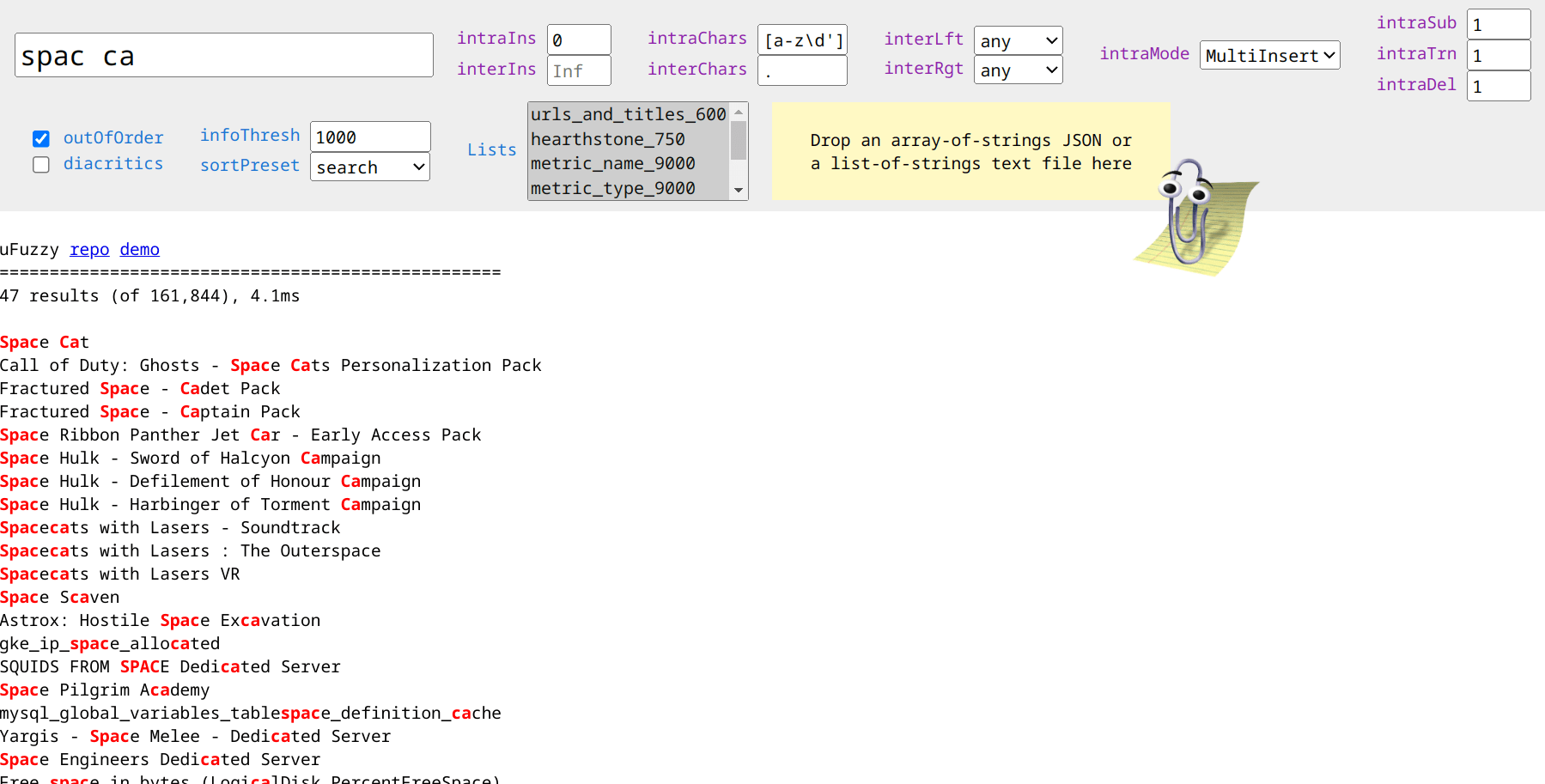
uFuzzy는 라틴/로마 알파벳에 최적화되어 있으며 내부적으로 유니코드가 아닌 정규식을 사용합니다.
더 많은 언어에 대한 지원은 내장된 라틴어 정규식을 추가 문자로 확장하거나 더 느린 범용 {unicode: true} 변형을 사용하여 작동합니다. 더 간단하지만 유연성이 떨어지는 {alpha: "..."} 대안은 내장 라틴어 정규 표현식의 AZ 및 az 부분을 선택한 문자로 바꿉니다(대체하는 동안 대소문자가 자동으로 일치됩니다).
uFuzzy.latinize() 유틸리티 함수는 검색하기 전에 건초 더미와 바늘에서 일반적인 악센트/발음 부호를 제거하는 데 사용될 수 있습니다.
// Latin (default)
let opts = { alpha : "a-z" } ;
// OR
let opts = {
// case-sensitive regexps
interSplit : "[^A-Za-z\d']+" ,
intraSplit : "[a-z][A-Z]" ,
intraBound : "[A-Za-z]\d|\d[A-Za-z]|[a-z][A-Z]" ,
// case-insensitive regexps
intraChars : "[a-z\d']" ,
intraContr : "'[a-z]{1,2}\b" ,
} ;
// Latin + Norwegian
let opts = { alpha : "a-zæøå" } ;
// OR
let opts = {
interSplit : "[^A-Za-zæøåÆØÅ\d']+" ,
intraSplit : "[a-zæøå][A-ZÆØÅ]" ,
intraBound : "[A-Za-zæøåÆØÅ]\d|\d[A-Za-zæøåÆØÅ]|[a-zæøå][A-ZÆØÅ]" ,
intraChars : "[a-zæøå\d']" ,
intraContr : "'[a-zæøå]{1,2}\b" ,
} ;
// Latin + Russian
let opts = { alpha : "a-zа-яё" } ;
// OR
let opts = {
interSplit : "[^A-Za-zА-ЯЁа-яё\d']+" ,
intraSplit : "[a-z][A-Z]|[а-яё][А-ЯЁ]" ,
intraBound : "[A-Za-zА-ЯЁа-яё]\d|\d[A-Za-zА-ЯЁа-яё]|[a-z][A-Z]|[а-яё][А-ЯЁ]" ,
intraChars : "[a-zа-яё\d']" ,
intraContr : "'[a-z]{1,2}\b" ,
} ;
// Unicode / universal (50%-75% slower)
let opts = {
unicode : true ,
interSplit : "[^\p{L}\d']+" ,
intraSplit : "\p{Ll}\p{Lu}" ,
intraBound : "\p{L}\d|\d\p{L}|\p{Ll}\p{Lu}" ,
intraChars : "[\p{L}\d']" ,
intraContr : "'\p{L}{1,2}\b" ,
} ;현재 모든 검색은 대소문자를 구분하지 않습니다. 대소문자를 구분하여 검색하는 것은 불가능합니다.
참고: testdata.json 파일은 4MB 크기의 다양한 162,000개의 문자열/구문 데이터 세트이므로 네트워크 전송으로 인해 첫 번째 로드가 느려질 수 있습니다. 브라우저에 캐시된 후 새로고침해 보세요.
첫째, uFuzzy를 분리하여 성능을 보여줍니다.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy&search=super%20ma
이제 동일한 비교 페이지가 fuzzysort, QuickScore 및 Fuse.js로 부팅됩니다.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=super%20ma
다음은 전체 라이브러리 목록이지만 브라우저 충돌을 방지하기 위해 데이터 세트를 줄였습니다( hearthstone_750 , urls_and_titles_600 ).
https://leeoniya.github.io/uFuzzy/demos/compare.html?lists=hearthstone_750,urls_and_titles_600&search=moo
답변:
그 외: https://github.com/leeoniya/uFuzzy/issues
npm i @leeoniya/ufuzzy
const uFuzzy = require ( '@leeoniya/ufuzzy' ) ; < script src = "./dist/uFuzzy.iife.min.js" > < / script > let haystack = [
'puzzle' ,
'Super Awesome Thing (now with stuff!)' ,
'FileName.js' ,
'/feeding/the/catPic.jpg' ,
] ;
let needle = 'feed cat' ;
let opts = { } ;
let uf = new uFuzzy ( opts ) ;
// pre-filter
let idxs = uf . filter ( haystack , needle ) ;
// idxs can be null when the needle is non-searchable (has no alpha-numeric chars)
if ( idxs != null && idxs . length > 0 ) {
// sort/rank only when <= 1,000 items
let infoThresh = 1e3 ;
if ( idxs . length <= infoThresh ) {
let info = uf . info ( idxs , haystack , needle ) ;
// order is a double-indirection array (a re-order of the passed-in idxs)
// this allows corresponding info to be grabbed directly by idx, if needed
let order = uf . sort ( info , haystack , needle ) ;
// render post-filtered & ordered matches
for ( let i = 0 ; i < order . length ; i ++ ) {
// using info.idx here instead of idxs because uf.info() may have
// further reduced the initial idxs based on prefix/suffix rules
console . log ( haystack [ info . idx [ order [ i ] ] ] ) ;
}
}
else {
// render pre-filtered but unordered matches
for ( let i = 0 ; i < idxs . length ; i ++ ) {
console . log ( haystack [ idxs [ i ] ] ) ;
}
}
} uFuzzy는 위의 filter , info , sort 단계를 결합한 uf.search(haystack, needle, outOfOrder = 0, infoThresh = 1e3) => [idxs, info, order] 래퍼를 제공합니다. 이 방법은 또한 검색어를 순서대로 일치시키지 않고 여러 하위 문자열 제외를 지원하기 위한 효율적인 논리를 구현합니다(예: fruit -green -melon .
주문한 일치 항목을 먼저 가져옵니다.
let haystack = [
'foo' ,
'bar' ,
'cowbaz' ,
] ;
let needle = 'ba' ;
let u = new uFuzzy ( ) ;
let idxs = u . filter ( haystack , needle ) ;
let info = u . info ( idxs , haystack , needle ) ;
let order = u . sort ( info , haystack , needle ) ; 기본 innerHTML 하이라이터( <mark> - 래핑된 범위):
let innerHTML = '' ;
for ( let i = 0 ; i < order . length ; i ++ ) {
let infoIdx = order [ i ] ;
innerHTML += uFuzzy . highlight (
haystack [ info . idx [ infoIdx ] ] ,
info . ranges [ infoIdx ] ,
) + '<br>' ;
}
console . log ( innerHTML ) ; 사용자 정의 표시 기능이 있는 innerHTML 형광펜( <b> - 래핑된 범위):
let innerHTML = '' ;
const mark = ( part , matched ) => matched ? '<b>' + part + '</b>' : part ;
for ( let i = 0 ; i < order . length ; i ++ ) {
let infoIdx = order [ i ] ;
innerHTML += uFuzzy . highlight (
haystack [ info . idx [ infoIdx ] ] ,
info . ranges [ infoIdx ] ,
mark ,
) + '<br>' ;
}
console . log ( innerHTML ) ;사용자 정의 표시 및 추가 기능을 갖춘 DOM/JSX 요소 하이라이터:
let domElems = [ ] ;
const mark = ( part , matched ) => {
let el = matched ? document . createElement ( 'mark' ) : document . createElement ( 'span' ) ;
el . textContent = part ;
return el ;
} ;
const append = ( accum , part ) => { accum . push ( part ) ; } ;
for ( let i = 0 ; i < order . length ; i ++ ) {
let infoIdx = order [ i ] ;
let matchEl = document . createElement ( 'div' ) ;
let parts = uFuzzy . highlight (
haystack [ info . idx [ infoIdx ] ] ,
info . ranges [ infoIdx ] ,
mark ,
[ ] ,
append ,
) ;
matchEl . append ( ... parts ) ;
domElems . push ( matchEl ) ;
}
document . getElementById ( 'matches' ) . append ( ... domElems ) ;uFuzzy에는 일치 전략이 다른 두 가지 작동 모드가 있습니다.
example - 정확함examplle - 단일 삽입(추가)exemple - 단일 대체(교체)exmaple - 단일 전치(스왑)exmple - 단일삭제(생략)xamp 부분xmap - 전치된 부분검색에는 3단계가 있습니다.
needle 에서 컴파일된 빠른 RegExp를 사용하여 전체 haystack 필터링합니다. 일치하는 인덱스의 배열을 원래 순서로 반환합니다.needle 다시 컴파일합니다. 따라서 일반적으로 필터 단계에서 반환되는 건초 더미의 축소된 하위 집합에서 실행되어야 합니다. uFuzzy 데모는 이 단계를 진행하기 전에 필터링된 항목이 1,000개 미만으로 제한됩니다.info 객체를 활용하여 Array.sort() 수행하여 최종 결과 순서를 결정합니다. 사용자 정의 정렬 기능은 uFuzzy 옵션을 통해 제공될 수 있습니다: {sort: (info, haystack, needle) => idxsOrder} .자유롭게 주석이 달린 200 LoC uFuzzy.d.ts 파일입니다.
inter 접두어가 붙은 옵션은 검색어 사이의 여유분에 적용되고, 인트라 접두어가 있는 옵션은 각 검색어 내의 여유분에 적용됩니다.
| 옵션 | 설명 | 기본 | 예 |
|---|---|---|---|
intraMode | 용어 일치를 수행하는 방법 | 0 | 0 다중 삽입단일 오류 1작동 방식 보기 |
intraIns | 허용되는 최대 추가 문자 수 용어 내의 각 문자 사이 | intraMode 값과 일치합니다( 0 또는 1 ). | '고양이'를 검색해 보세요...0 다음과 일치할 수 있습니다: cat , s cat , cat ch, va cat e1 다음과도 일치합니다: car r t , ch a p t er, out ca s t |
interIns | 용어 사이에 허용되는 최대 추가 문자 수 | Infinity | '어디'를 검색하는 중...Infinity 일치할 수 있습니다: where is , where have blah w is dom5 일치할 수 없습니다: 어쩌구 지혜가 있는 곳이 어디입니까? |
intraSubintraTrnintraDel | intraMode: 1 만,용어 내에서 허용되는 오류 유형 | intraMode 값과 일치합니다( 0 또는 1 ). | 0 아니요1 예 |
intraChars | 허용된 삽입에 대한 부분 정규 표현식 용어 내 각 문자 사이의 문자 | [azd'] | [azd] 영숫자만 일치합니다(대소문자 구분 안 함).[w-] 영숫자, 밑줄 및 하이픈과 일치합니다. |
intraFilt | 기간 및 일치에 따라 결과를 제외하는 콜백 | (term, match, index) => true | 자신만의 일을 하세요. 아마도... - 길이 차이 임계값 - 레벤슈타인 거리 - 기간 상쇄 또는 내용 |
interChars | 용어 사이에 허용되는 문자에 대한 부분 정규 표현식 | . | . 모든 문자와 일치[^azd] 공백과 구두점만 일치합니다. |
interLft | 허용 용어 왼쪽 경계를 결정합니다. | 0 | '마니아'를 검색해 보세요...0 모두 - 어디서나: ro mania n1 느슨한 - 공백, 구두점, 영숫자, 대소문자 변경 전환: Track Mania , mania c2 엄격 - 공백, 구두점: mania cally |
interRgt | 허용 용어 권리 경계를 결정합니다. | 0 | '마니아'를 검색해 보세요...0 모두 - 어디서나: ro mania n1 느슨함 - 공백, 구두점, 영숫자, 대소문자 변경 전환: Mania Star2 엄격 - 공백, 구두점: mania _foo |
sort | 사용자 정의 결과 정렬 기능 | (info, haystack, needle) => idxsOrder | 기본값: 검색 정렬, 전체 용어 일치 및 문자 밀도 우선순위 지정 데모: 자동 완성 정렬, 시작 오프셋 및 길이 일치 우선순위 지정 |
이 평가는 매우 좁으며 물론 내 사용 사례, 텍스트 자료 및 내 라이브러리 운영에 대한 완전한 전문 지식에 편향되어 있습니다. 일부 축에 따라 결과를 크게 향상시킬 수 있는 다른 라이브러리의 일부 기능을 최대한 활용하지 않을 가능성이 매우 높습니다. 나는 "기본 사용법" 예제와 README 문서에 대해 10분 동안 성급하게 훑어본 것보다 더 깊은 라이브러리 지식을 가진 사람의 개선 PR을 환영합니다.
벌레 캔 #1.
성능에 대해 논의하기 전에 검색 품질에 대해 이야기해 보겠습니다. 결과가 "아 예!"라는 이상한 중간 내용일 때는 속도가 중요하지 않기 때문입니다. 그리고 "WTF?".
검색 품질은 매우 주관적입니다. "자동 입력/자동 제안" 사례에서 좋은 상위 일치 항목을 구성하는 것은 "검색/모두 찾기" 시나리오에서는 잘못된 일치 항목일 수 있습니다. 일부 솔루션은 후자에 최적화되어 있고 일부 솔루션은 전자에 최적화되어 있습니다. 결과를 어느 방향으로든 왜곡하는 손잡이를 찾는 것이 일반적이지만 이는 종종 느낌에 어긋나고 불완전하며 단일 복합 일치 "점수"를 생성하는 프록시에 지나지 않습니다.
업데이트(2024): 이상한 일치에 관한 아래 비평은 Fuse.js의 기본 구성에만 적용됩니다. 직관과는 반대로, ignoreFieldNorm: true 설정하면 결과가 상당히 향상되었지만 고품질 일치 항목의 순서는 여전히 좋지 않습니다.
가장 인기 있는 퍼지 검색 라이브러리인 Fuse.js에서 생성된 일부 일치 항목과 데모에서 일치 강조 표시가 구현된 일부 항목을 살펴보겠습니다.
부분 용어 "twili"를 검색하면 수많은 명백한 "twilight" 결과 위에 다음과 같은 결과가 나타납니다.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=twili
이러한 불량한 일치 항목은 단독으로 있을 뿐만 아니라 실제로 문자 그대로의 하위 문자열보다 순위가 더 높습니다.
검색어를 "twilight" 로 마무리해도 여전히 이상한 결과의 점수가 더 높습니다.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore,Fuse&search=twilight
일부 엔진은 시작/인덱싱 비용이 높지만 부분 접두사 일치로 더 나은 성능을 발휘합니다.
https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,FlexSearch,match-sorter,MiniSearch&search=twili
여기서 match-sorter 1,384개의 결과를 반환하지만 처음 40개만 관련이 있습니다. 컷오프가 어디에 있는지 어떻게 알 수 있나요?
벌레 캔 #2.
모든 벤치마크는 형편없지만 이번 벤치마크는 다른 것보다 형편없을 수도 있습니다.
그럼에도 불구하고 손으로 YMMV/스스로 해고하는 것보다 낫고 아무것도 없는 것보다 확실히 낫습니다.
환경
| 날짜 | 2023-10 |
|---|---|
| 하드웨어 | CPU: 라이젠 7 PRO 5850U(1.9GHz, 7nm, 15W TDP) 램: 48GB SSD: 삼성 SSD 980 PRO 1TB(NVMe) |
| 운영체제 | EndeavourOS(아치 리눅스) v6.5.4-arch2-1 x86_64 |
| 크롬 | v117.0.5938.132 |
libs 매개변수를 원하는 라이브러리 이름으로 변경하여 실행할 수 있습니다: https://leeoniya.github.io/uFuzzy/demos/compare.html?bench&libs=uFuzzybench 모드에서는 결과 출력이 억제됩니다.test , chest , super ma , mania , puzz , prom rem stor , twil 과 같은 검색어를 문자별로(20ms마다) 입력한 후 삭제하여 각 키 누름에 대한 검색을 시작합니다. 각 라이브러리의 결과를 평가하거나 여러 라이브러리를 비교하려면 bench 없이 더 많은 libs 있는 동일한 페이지를 방문하세요. https://leeoniya.github.io/uFuzzy/demos/compare.html?libs=uFuzzy,fuzzysort,QuickScore ,퓨즈&서치=super%20ma.
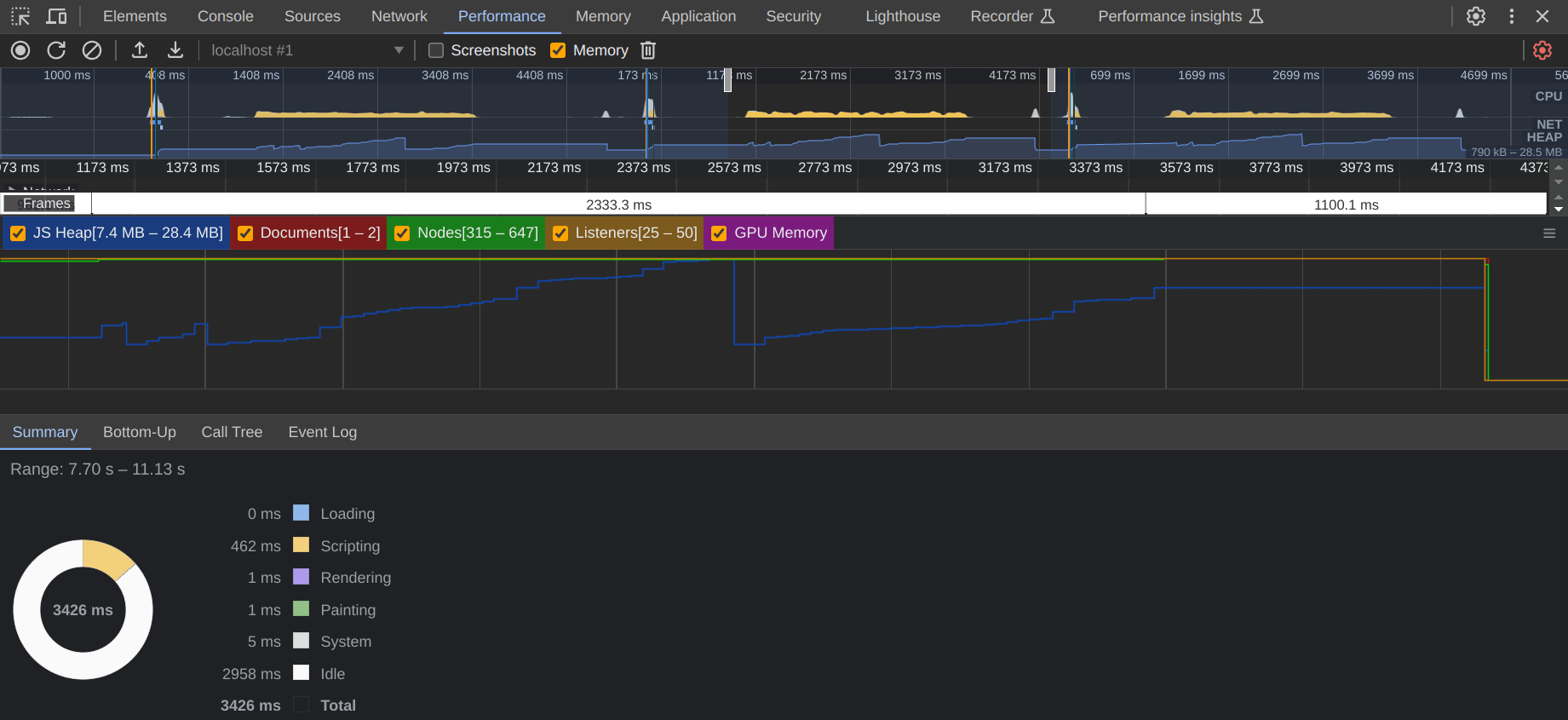
평가되는 몇 가지 지표가 있습니다.
| 도서관 | 별 | 크기(최소) | 초기화 | 찾다 (×86) | 힙(피크) | 보유 | GC |
|---|---|---|---|---|---|---|---|
| uFuzzy (시도해 보세요) | ★ 2.3천 | 7.6KB | 0.5ms | 434ms | 28.4MB | 7.4MB | 18ms |
| uFuzzy (시도해 보세요) (외부 접두사 캐싱) | 210ms | 27.8MB | 7.4MB | 18ms | |||
| uFuzzy (시도해 보세요) (outOfOrder, 더 모호함) | 545ms | 29.5MB | 7.4MB | 18ms | |||
| uFuzzy (시도해 보세요) (outOfOrder, 퍼지, SingleError) | 508ms | 30.0MB | 7.4MB | 18ms | |||
| ------- | |||||||
| Fuse.js(시도) | ★ 16.6천 | 24.2KB | 31ms | 33875ms | 245MB | 13.9MB | 25ms |
| FlexSearch(라이트)(시도) | ★ 10.7천 | 6.2KB | 3210ms | 83ms | 670MB | 316MB | 553ms |
| Lunr.js(시도) | ★ 8.7천 | 29.4KB | 1704ms | 996ms | 380MB | 123MB | 166ms |
| Orama (이전 Lyra) (시도) | ★ 6.4k | 41.5KB | 2650ms | 225ms | 313MB | 192MB | 180ms |
| 미니서치(시도) | ★ 3.4천 | 29.1KB | 504ms | 1453ms | 438MB | 67MB | 105ms |
| 일치 분류기(시도) | ★ 3.4천 | 7.3KB | 0.1ms | 6245ms | 71MB | 7.3MB | 12ms |
| 퍼지정렬(시도) | ★ 3.4천 | 6.2KB | 50ms | 1321ms | 175MB | 84MB | 63ms |
| 웨이드 (시도해) | ★ 3천 | 4KB | 781ms | 194ms | 438MB | 42MB | 130ms |
| 퍼지 검색(시도) | ★ 2.7천 | 0.2KB | 0.1ms | 529ms | 26.2MB | 7.3MB | 18ms |
| js 검색(시도) | ★ 2.1천 | 17.1KB | 5620ms | 1190ms | 1740MB | 734MB | 2600ms |
| Elasticlunr.js(시도) | ★ 2천 | 18.1KB | 933ms | 1330ms | 196MB | 70MB | 135ms |
| 퍼지세트(시도) | ★ 1.4k | 2.8KB | 2962ms | 606ms | 654MB | 238MB | 239ms |
| 검색 색인(시도) | ★ 1.4k | 168KB | RangeError: 최대 호출 스택 크기를 초과했습니다. | ||||
| sifter.js (시도) | ★ 1.1천 | 7.5KB | 3ms | 1070ms | 46.2MB | 10.6MB | 18ms |
| fzf-for-js (시도) | ★ 831 | 15.4KB | 50ms | 6290ms | 153MB | 25MB | 18ms |
| 퍼지 (시도해) | ★ 819 | 1.4KB | 0.1ms | 5427ms | 72MB | 7.3MB | 14ms |
| 빠른 퍼지(시도) | ★ 346 | 18.2KB | 790ms | 19266ms | 550MB | 165MB | 140ms |
| ItemsJS(시도) | ★ 305 | 109KB | 2400ms | 11304ms | 320MB | 88MB | 163ms |
| LiquidMetal(시도) | ★ 292 | 4.2KB | (충돌) | ||||
| 퍼지검색(시도) | ★ 209 | 3.5KB | 2ms | 3948ms | 84MB | 10.5MB | 18ms |
| FuzzySearch2 (시도) | ★ 186 | 19.4KB | 93ms | 4189ms | 117MB | 40.3MB | 40ms |
| QuickScore(시도) | ★ 153 | 9.5KB | 10ms | 6915ms | 133MB | 12.1MB | 18ms |
| ndx (시도) | ★ 142 | 2.9KB | 300ms | 581ms | 308MB | 137MB | 262ms |
| fzy (시도해) | ★ 133 | 1.5KB | 0.1ms | 3932ms | 34MB | 7.3MB | 10ms |
| 퍼지 도구(시도) | ★ 13 | 3KB | 0.1ms | 5138ms | 164MB | 7.5MB | 18ms |
| fuzzyMatch(시도) | ★ 0 | 1KB | 0.1ms | 2415ms | 83.5MB | 7.3MB | 13ms |


