aiwhispr
version 0.941
AIWhispr은 의미론적 검색을 위해 벡터 임베딩 파이프라인을 자동화하는 노/로우 코드 도구입니다. 간단한 구성으로 파일 읽기, 텍스트 추출, 벡터 임베딩 생성 및 벡터 데이터베이스에 저장을 위한 파이프라인을 구동합니다.
AIWhispr

AIWhispr에는 다음 벡터 데이터베이스에 대한 커넥터가 있습니다.
1 Qdrant
2 밀버스
3 위비에이트
4 타입센스
5 몽고DB
6 포스트그레스 - PGVector
벡터 데이터베이스를 설치하고 시작했는지 확인하십시오.
AIWHISPR_HOME_DIR 환경 변수는 aiwhispr 디렉터리의 전체 경로여야 합니다.
AIWHISPR_LOG_LEVEL 환경 변수는 DEBUG / INFO / WARNING / ERROR로 설정할 수 있습니다.
AIWHISPR_HOME=/<...>/aiwhispr
AIWHISPR_LOG_LEVEL=DEBUG
export AIWHISPR_HOME
export AIWHISPR_LOG_LEVEL
쉘 로그인 스크립트에 환경 변수를 추가하는 것을 잊지 마세요
아래 명령을 실행하세요.
$AIWHISPR_HOME/shell/install_python_packages.sh
uwsgi 설치가 실패하면 gcc, python-dev, python3-dev가 설치되어 있는지 확인하세요.
sudo apt-get install gcc
sudo apt install python-dev
sudo apt install python3-dev
pip3 install uwsgi
AIWhispr에는 시작하는 데 도움이 되는 스트림라이트 앱이 함께 제공됩니다.
스트림라이트 앱 실행
cd $AIWHISPR_HOME/python/streamlit
streamlit run ./Configure_Content_Site.py &
그러면 기본 포트 8501에서 스트림라이트 앱이 시작되고 웹 브라우저에서 세션이 시작됩니다.
의미 체계 검색을 위해 콘텐츠를 인덱싱하기 위한 파이프라인을 구성하는 3단계가 있습니다.
1. 저장 위치에서 파일을 읽도록 구성
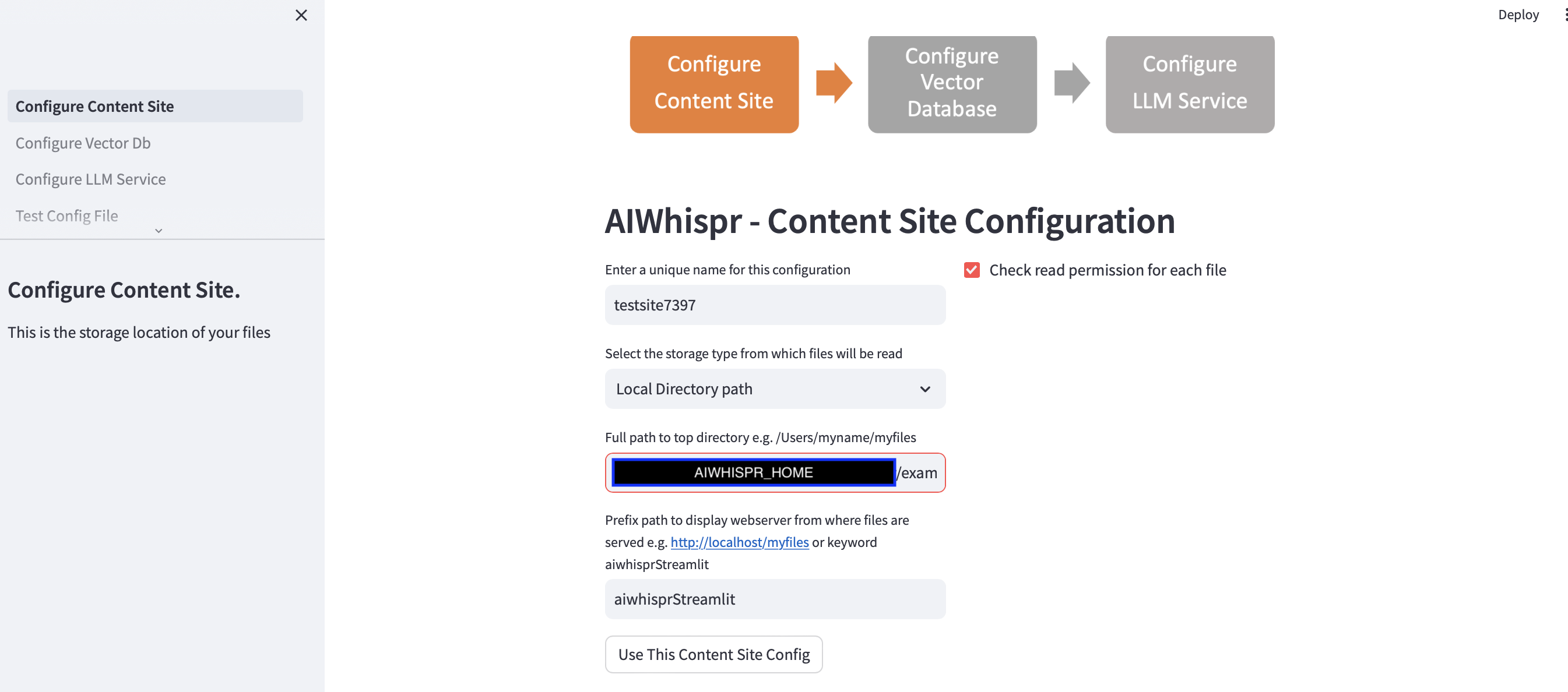
"이 콘텐츠 사이트 구성 사용" 버튼을 클릭하여 기본 구성을 계속할 수 있습니다.
벡터 데이터베이스 연결을 구성하려면 다음 단계로 이동하세요.
기본 예는 의미 검색을 위해 BBC의 뉴스 기사를 색인화합니다.
Streamlit 앱은 사용자가 새 구성을 시작한다고 가정하고 임의의 구성 이름을 할당합니다. 이를 덮어쓰면 보다 의미 있는 이름을 지정할 수 있습니다. 구성 이름은 고유해야 합니다. 공백이나 특수 문자를 포함할 수 없습니다.
기본 구성은 로컬 디렉터리 경로 $AIWHISPR_HOME/examples/http/bbc에서 콘텐츠를 읽습니다.
여기에는 의미 검색을 위해 색인이 생성된 BBC의 2000개 이상의 뉴스 기사가 포함되어 있습니다.
AWS S3, Azure Blob, Google Cloud Storage에 저장된 콘텐츠를 읽도록 선택할 수 있습니다.
접두사 경로 구성은 검색 결과에 대한 href 웹 링크를 만드는 데 사용됩니다. 기본 키워드 "aiwhisprStreamlit"을 계속 사용할 수 있습니다.
"이 콘텐츠 사이트 구성 사용" 버튼을 클릭하고 왼쪽 사이드바에서 "벡터 데이터베이스 구성"을 클릭하여 벡터 데이터베이스 연결을 구성하는 다음 단계로 진행합니다.
2. 벡터 DB 구성
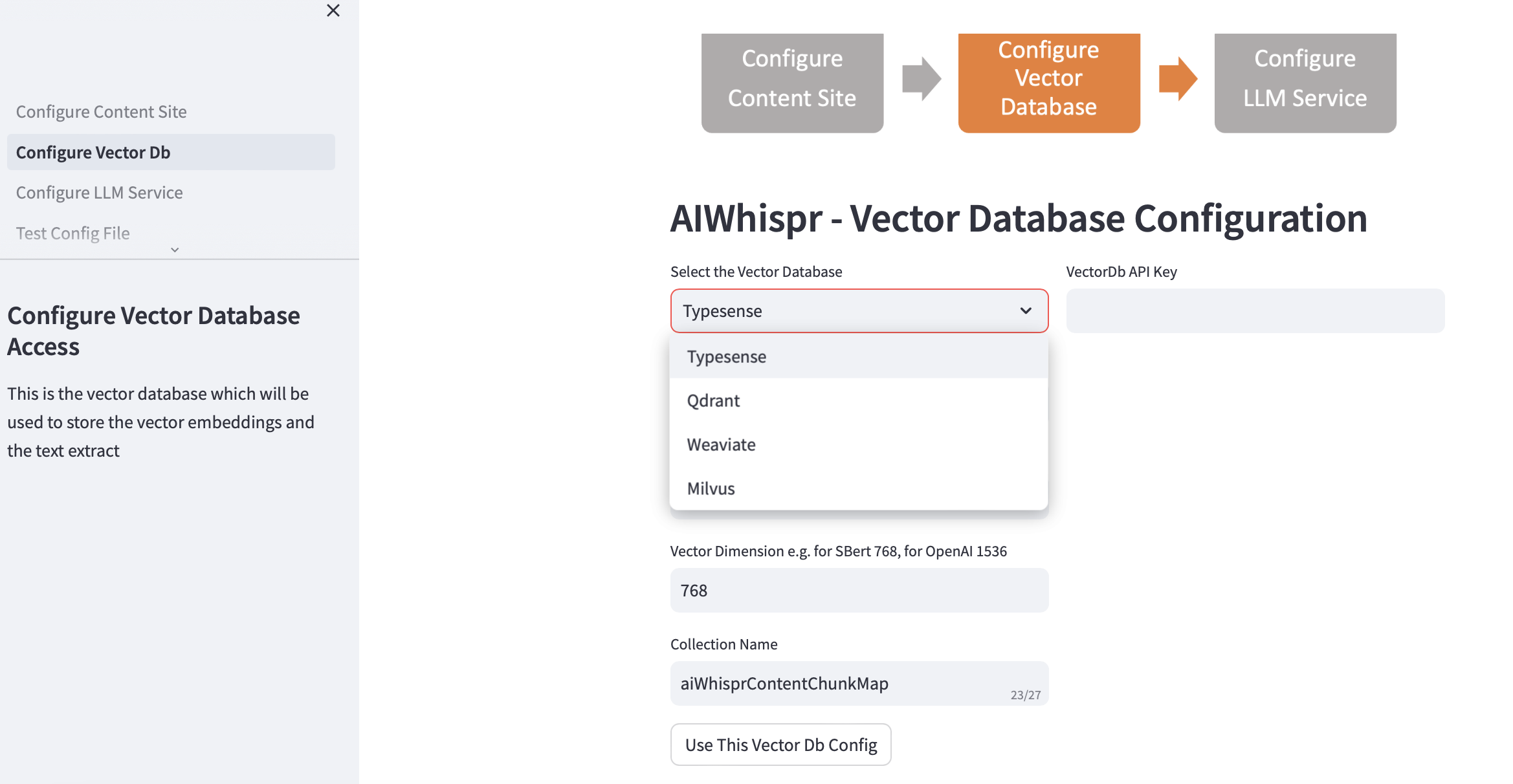
벡터DB를 선택하고 연결 세부정보를 제공하세요.
벡터 데이터베이스를 선택하면 벡터 Db IP 주소와 포트 번호가 기본 설치에 따라 채워집니다. 설정에 따라 이를 변경할 수 있습니다.
인증을 위해 벡터 데이터베이스를 구성해야 합니다. Qdrant, Weaviate, Typesense의 경우 API Key가 필요합니다. Milvus의 경우 사용자 ID, 비밀번호 조합을 구성해야 합니다.
벡터 차원 크기는 텍스트를 벡터 임베딩으로 인코딩하는 데 사용할 LLM을 기반으로 지정해야 합니다. 예: Open AI "text-embedding-ada-002"의 경우 이는 OpenAI 임베딩 서비스에서 반환된 벡터의 크기인 1536으로 구성되어야 합니다.
벡터 데이터베이스에 생성된 기본 컬렉션 이름은 aiwhisprContentChunkMap입니다. 자신만의 컬렉션 이름을 지정할 수 있습니다.
"이 벡터 Db 구성 사용" 버튼을 클릭한 후 왼쪽 사이드바에서 "LLM 서비스 구성"을 클릭하여 다음 단계로 이동합니다.
3. LLM 서비스 구성
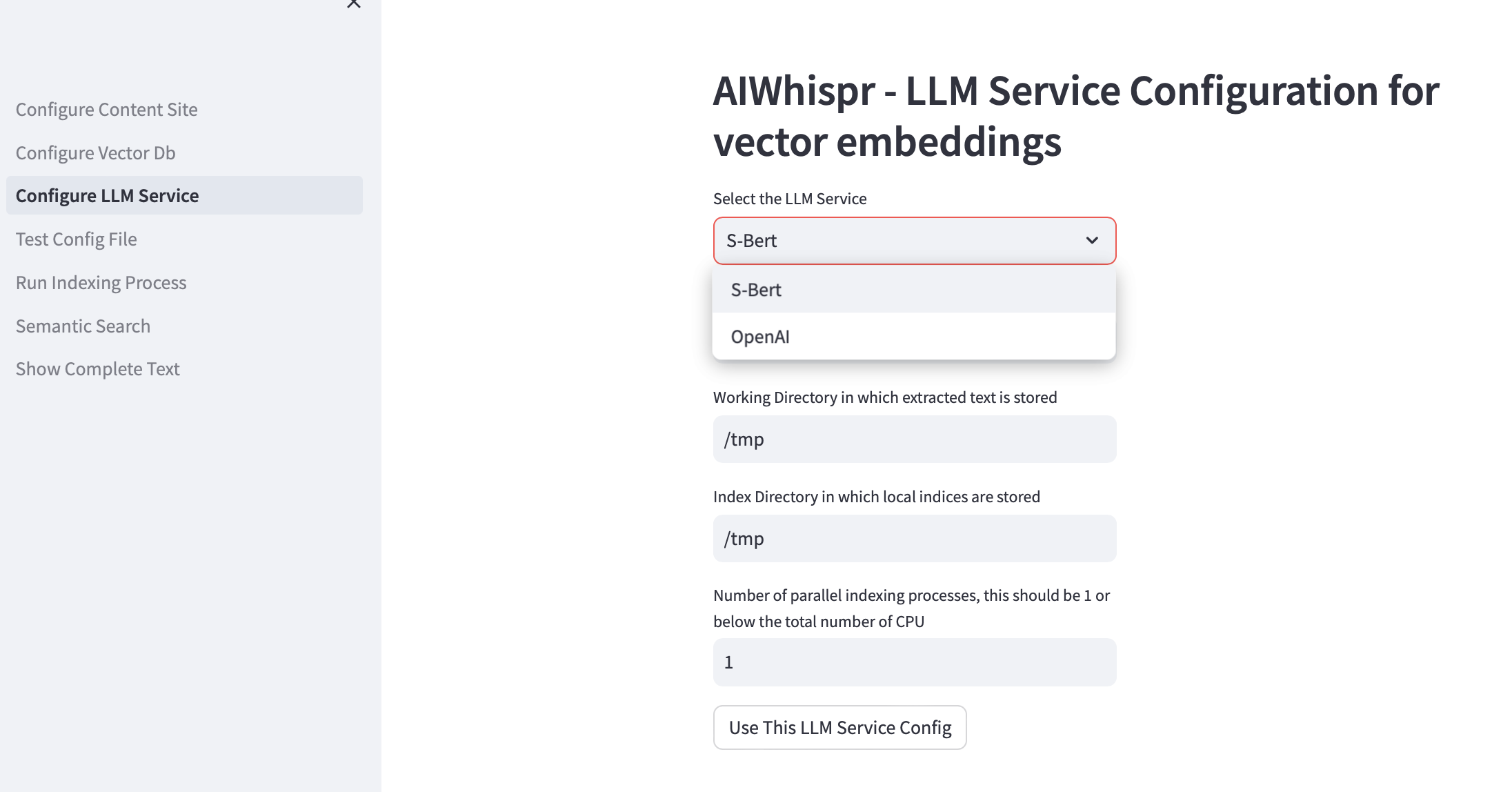
로컬에서 실행되거나 OpenAI API를 사용하는 Sbert 사전 학습 모델을 사용하여 벡터 임베딩을 생성하도록 선택할 수 있습니다.
Sbert 모델 계열의 경우 사용되는 기본 모델은 all-mpnet-base-v2입니다. 다른 Sbert 모델을 지정할 수 있습니다.
OpenAI의 경우 기본 임베딩 모델은 text-embedding-ada-002입니다.
기본 작업 디렉터리는 /tmp입니다.
작업 디렉터리는 저장 위치에서 읽거나 다운로드한 파일을 처리하기 위한 작업 디렉터리로 사용되는 로컬 컴퓨터의 위치입니다. 그런 다음 문서에서 추출된 텍스트는 더 작은 크기(일반적으로 700단어)로 분할된 다음 벡터 임베딩으로 인코딩됩니다. 작업 디렉터리는 텍스트 청크를 저장하는 데 사용됩니다.
기본 로컬 인덱싱 디렉터리는 /tmp입니다.
작업 및 인덱스 디렉터리에 대한 영구 로컬 디렉터리 경로를 지정할 수 있습니다.
index-dir은 읽어야 하는 콘텐츠 파일의 인덱싱 목록을 저장하는 데 사용됩니다. AIWhispr은 인덱싱을 위한 여러 프로세스를 지원하며, 각 프로세스는 자체 인덱싱 목록을 사용하므로 컴퓨터에서 여러 CPU를 활용할 수 있습니다.
인덱싱(콘텐츠 읽기, 벡터 임베딩 생성, 벡터 데이터베이스에 저장)을 위해 여러 CPU를 활용하려면 병렬 프로세스 수에 대한 테스트 상자에서 이를 지정하십시오. 권장 사항은 이 값이 1 또는 최대(CPU 수/2)여야 한다는 것입니다. 8개 CPU 시스템의 예에서는 4로 설정해야 합니다. AIWhispr은 다중 처리를 사용하여 Python GIL 제한을 우회합니다.
벡터 임베딩 파이프라인 구성 파일의 최종 버전을 생성하려면 "이 LLM 서비스 구성 사용"을 클릭하세요.
구성 파일의 내용과 컴퓨터에서의 해당 위치가 표시됩니다.
왼쪽 사이드바에서 "구성 파일 테스트"를 클릭하여 이 구성을 테스트할 수 있습니다.
4. 테스트 구성
이제 벡터 임베딩 파이프라인 구성 파일의 위치를 보여주는 메시지와 "구성 파일 테스트" 버튼이 표시됩니다.
버튼을 클릭하면 파이프라인 구성을 테스트하는 프로세스가 시작됩니다.
로그 끝에 이 파이프라인 구성을 사용할 수 있음을 알려주는 "NO ERRORS" 메시지가 표시되어야 합니다.
파이프라인을 시작하려면 왼쪽 사이드바에서 "인덱싱 프로세스 실행"을 클릭하세요.
5. 인덱싱 프로세스 실행
"인덱싱 시작" 버튼이 표시됩니다.
파이프라인을 시작하려면 이 버튼을 클릭하세요. 로그는 15초마다 업데이트됩니다.
기본 예에서는 약 20분 정도 소요되는 2000개 이상의 BBC 뉴스 기사를 색인화합니다.
인덱싱 프로세스가 실행되는 동안, 즉 Streamlit "실행 중" 상태가 오른쪽 상단에 표시되는 동안에는 이 페이지에서 벗어나지 마십시오.
머신에서 grep을 사용하여 인덱싱 프로세스가 실행 중인지 확인할 수도 있습니다.
ps -ef | grep python3 | grep index_content_site.py
6. 의미 검색
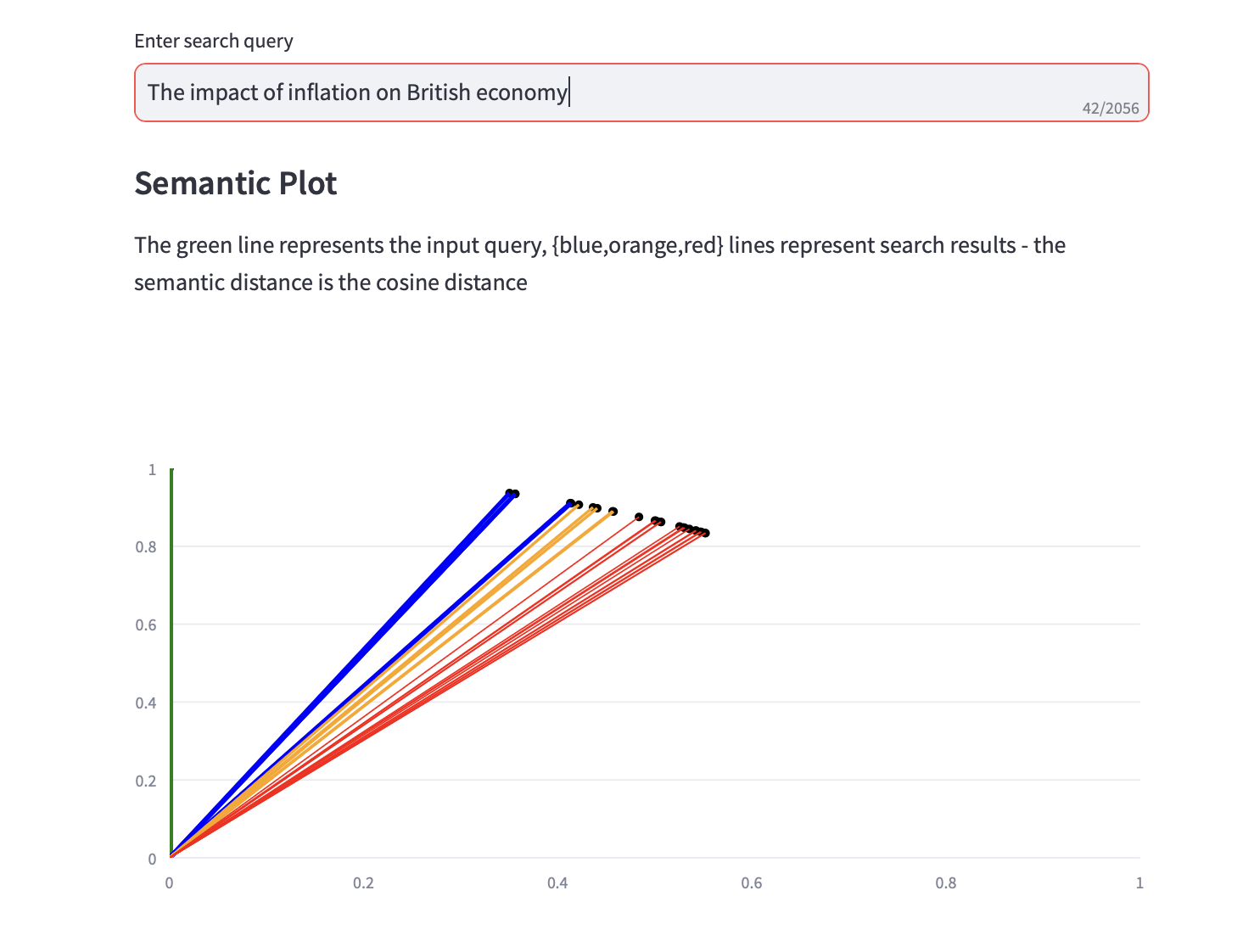
이제 의미 체계 검색 쿼리를 실행할 수 있습니다.
검색 결과에 대한 코사인 거리와 상위 3개 PCA 분석을 표시하는 의미 플롯도 텍스트 검색 결과와 함께 표시됩니다.