lnx
v0.9.0 Master

풍부한 기능 | ⚡ 엄청나게 빠르다
REST를 통한 Tantivy 검색 엔진의 초고속 적응형 배포입니다.
lnx는 바퀴를 재발명하지 않도록 제작되었으며, Tantivy 검색 엔진 의 원시 컴퓨팅 성능과 결합된 tokio-rs 작업 도용 런타임, 하이퍼 웹 프레임워크 위에 서 있습니다.
이를 통해 lnx는 한 번에 수만 개의 문서 삽입에 대해 밀리초 단위의 인덱싱을 제공할 수 있습니다(더 이상 인덱싱될 때까지 기다릴 필요가 없습니다!). 인덱스별 트랜잭션 및 해시 테이블에 대한 또 다른 조회인 것처럼 검색을 처리하는 기능이 있습니까?
lnx는 매우 새로운 기능이지만 생태계 덕분에 다양한 기능을 제공합니다.
여기에서는 인덱싱된 후 합리적인 18GB로 들어오는 2,700만 개의 문서 데이터 세트에 입력할 때 lnx가 검색을 수행하는 것을 볼 수 있습니다. 빠른 퍼지 시스템과 함께 ~3GB RAM을 사용하여 i7-8700k에서 실행되었습니다. 우리가 시도할 더 큰 데이터 세트가 있습니까? 이슈를 열어보세요!
lnx는 특정 사용 사례에 맞게 시스템을 미세 조정할 수 있는 기능을 제공할 수 있습니다. 비동기 런타임 스레드를 사용자 정의할 수 있습니다. 동시성 스레드 풀, 판독기 및 기록기 스레드당 스레드, 모두 인덱스당.
이를 통해 컴퓨팅 리소스가 어디로 가는지 세부적으로 제어할 수 있습니다. 데이터세트는 크지만 동시 읽기 양은 적나요? 최대 동시성을 낮추는 대가로 리더 스레드를 범프합니다.
다음 수치는 작은 movies.json 데이터 세트에서 lnx-cli 로 찍은 것입니다. 새로운 Meilisearch 엔진이 이를 다소 개선했지만 Meilisearch가 수백만 개의 문서를 색인화하는 데 믿을 수 없을 정도로 오랜 시간이 걸리기 때문에 더 높은 수준의 시도를 하지 않았습니다.
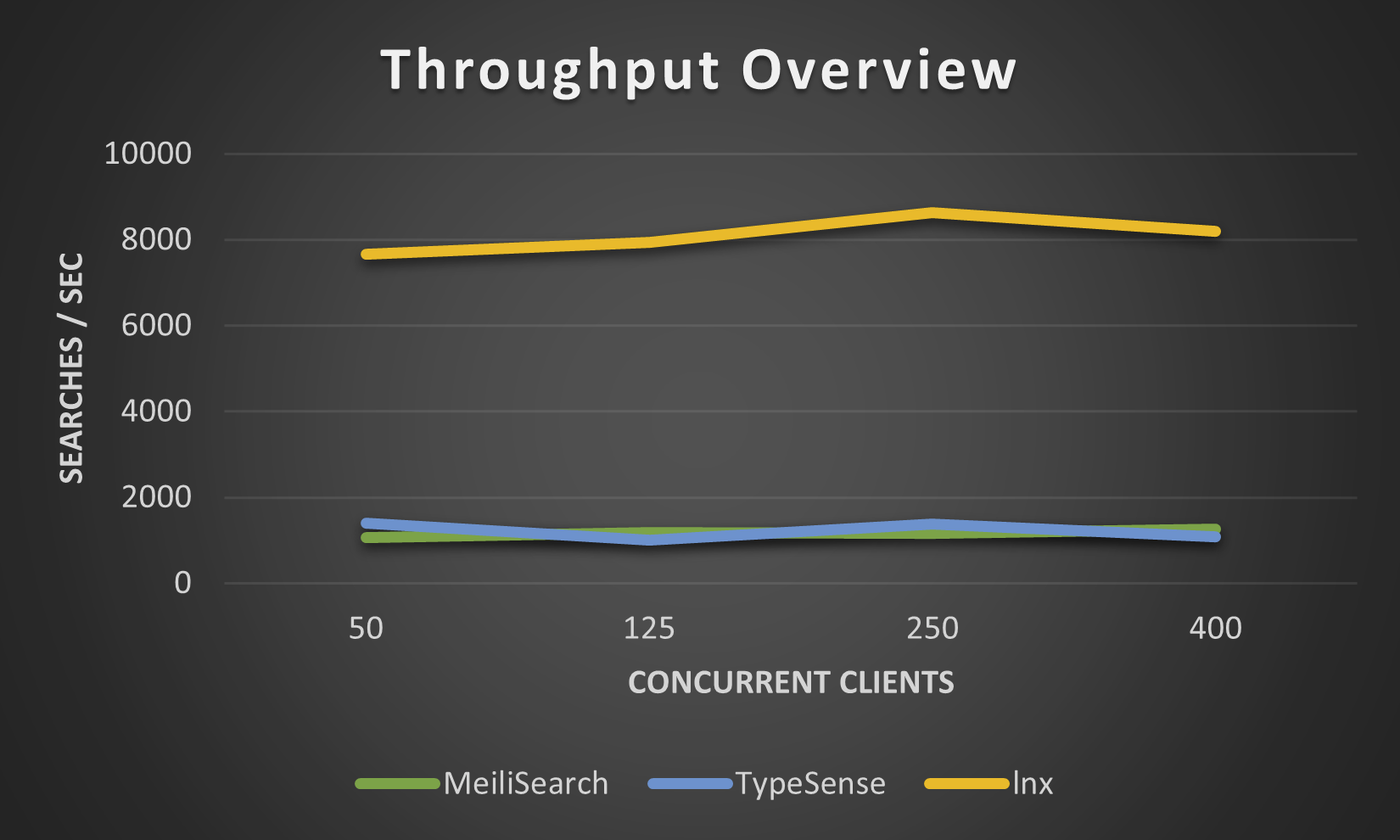
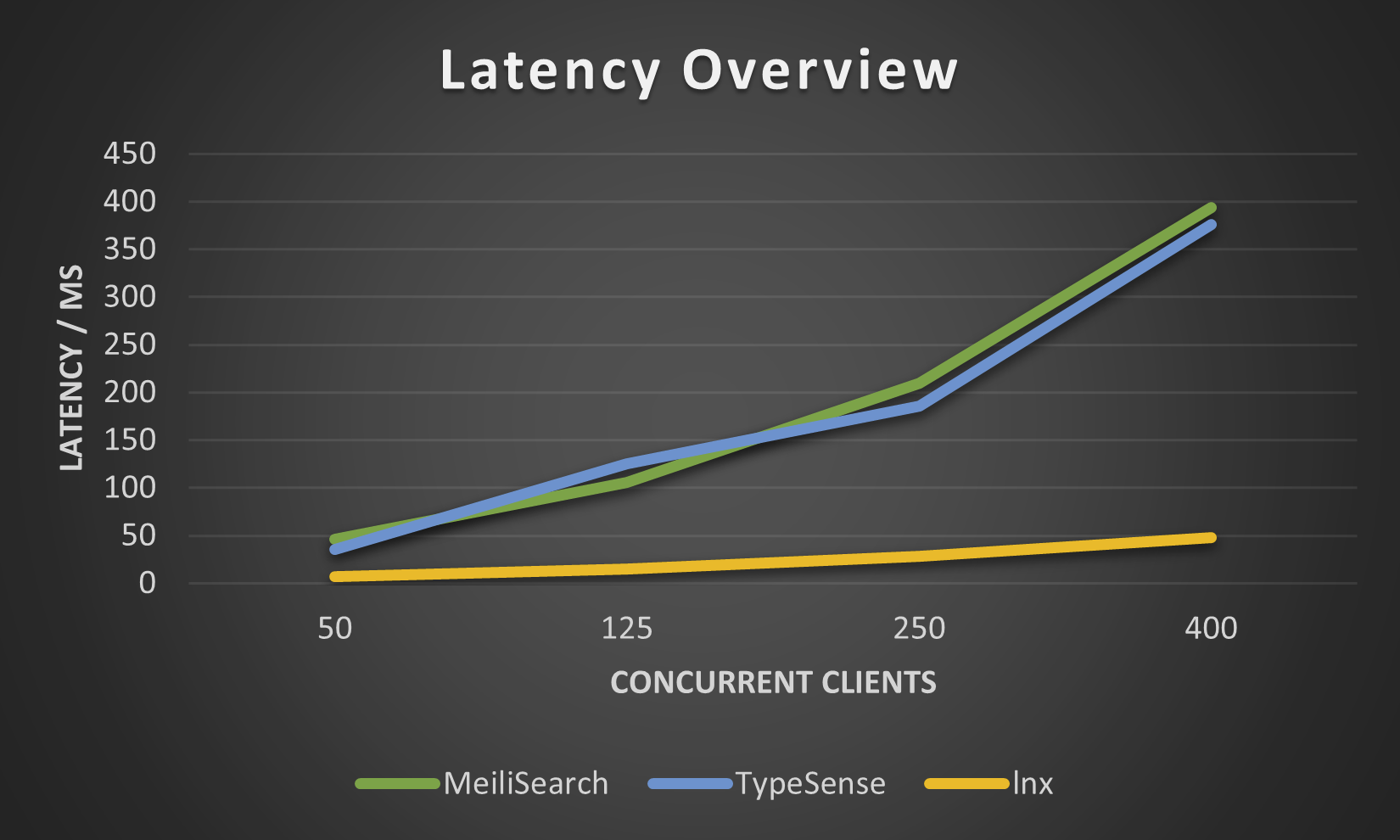
lnx는 다양한 기능을 제공하지만, 그렇게 젊은 시스템이기 때문에 모든 기능을 제공할 수는 없습니다. 당연히 몇 가지 제한 사항이 있습니다.


