
평가 순위 평가자
RRE(Rated Ranking Evaluator)는 이름에서 알 수 있듯이 검색 인프라에서 나오는 결과의 품질을 평가하는 검색 품질 평가 도구입니다.
모래밭
- 검색 품질 평가: 개발자 관점
- Haystack EU의 RRE, 런던, 2018
- Fosdem 2019의 RRE
- RRE(평가 순위 평가자) 실습 관련성 테스트 @Chorus, 2021
- Rated Ranking Evaluator Enterprise: 차세대 무료 검색 품질 평가 도구, Padova, 2021
- https://github.com/SeaseLtd/rated-ranking-evaluator/wiki에 있는 프로젝트 Wiki
- RRE-사용자 메일링 리스트: https://groups.google.com/g/rre-user
현재 Apache Solr 및 Elasticsearch가 지원됩니다(지원되는 버전에 대한 설명서 참조).
다음 그림은 RRE 생태계를 보여줍니다.
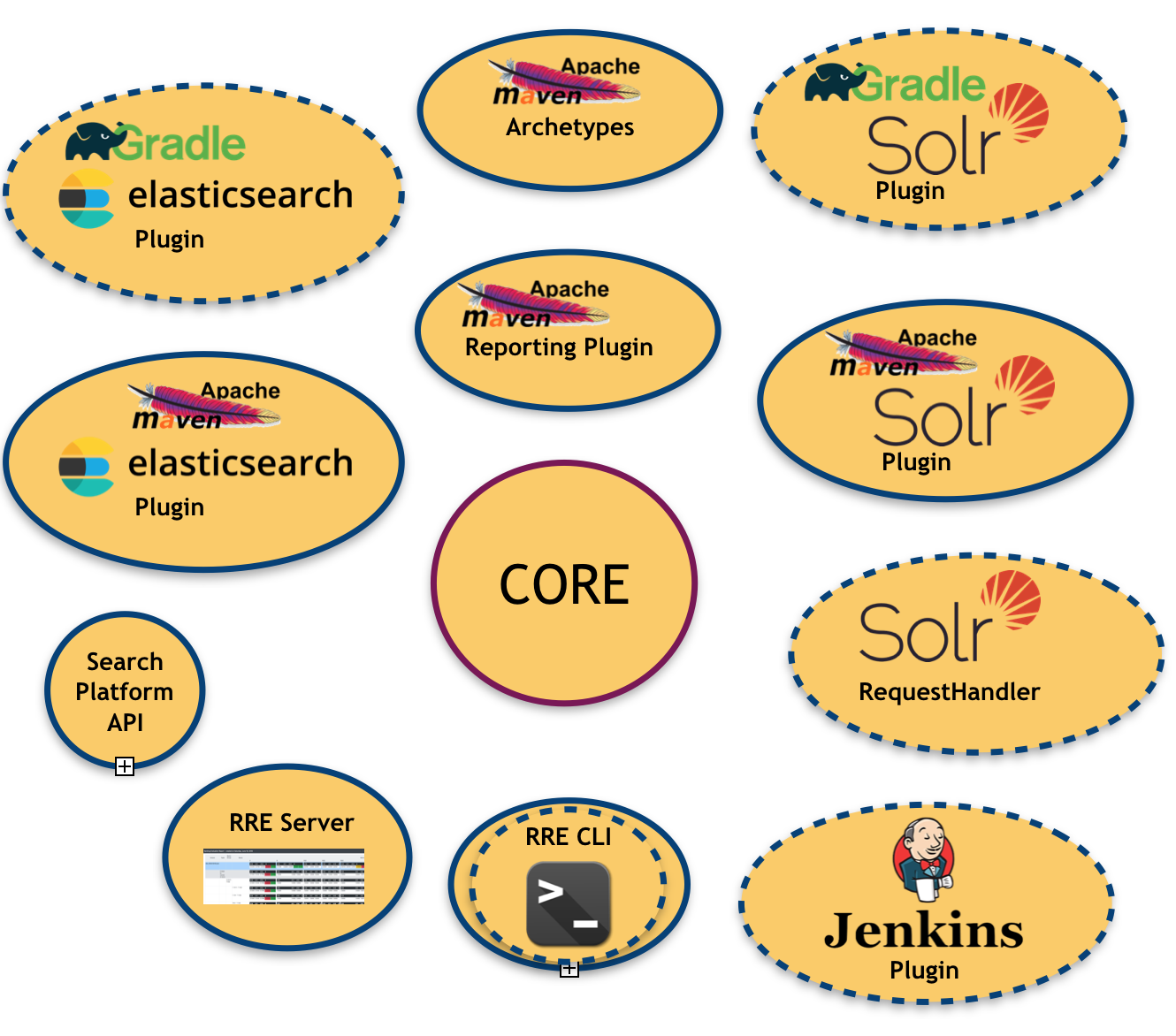
보시다시피, 이미 설치 및 계획된 모듈이 많이 있습니다(경계선이 점선으로 표시된 모듈).
- 코어 , 즉 평가 결과 생성을 담당하는 중앙 라이브러리입니다.
- 검색 플랫폼 API : 기본 검색 플랫폼을 추상화(및 바인딩)하기 위한 것입니다.
- 검색 플랫폼 바인딩 세트: 위에서 말했듯이 현재 두 가지 사용 가능한 바인딩(Apache Solr 및 Elasticsearch)이 있습니다.
- 사용 가능한 각 검색 플랫폼 바인딩을 위한 Apache Maven 플러그인 : Maven 기반 빌드 시스템에 RRE를 주입할 수 있습니다.
- Apache Maven 보고 플러그인 : 사람이 읽을 수 있는 형식(예: PDF, Excel)으로 평가 보고서를 생성하며, 비기술적인 사용자를 대상으로 하는 데 유용합니다.
- RRE 서버 : 각 빌드 주기 후에 평가 결과가 실시간으로 업데이트되는 간단한 웹 기반 제어판입니다.
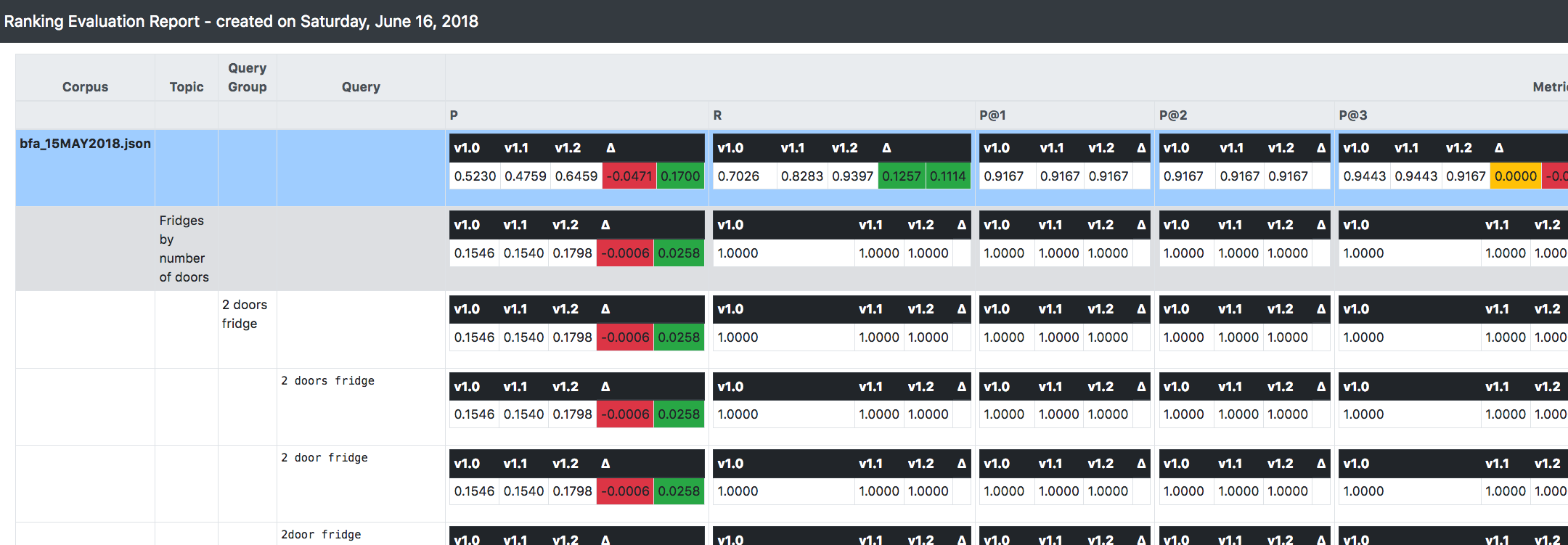
전체 시스템은 메트릭을 구성/활성화하고 플러그인할 수도 있는 프레임워크로 구축되었습니다(물론 이 옵션에는 약간의 개발이 필요함). 현재 RRE 릴리스의 일부인 메트릭은 다음과 같습니다.
- 정밀도 : 검색된 관련 문서의 비율입니다.
- Recall : 검색된 관련 문서의 비율입니다.
- 1의 정밀도 : 이 측정항목은 목록의 첫 번째 상위 결과가 관련성이 있는지 여부를 나타냅니다.
- 2에서의 정밀도 : 위와 동일하지만 처음 두 결과를 고려합니다.
- 3에서의 정밀도 : 위와 동일하지만 처음 세 가지 결과를 고려합니다.
- 정밀도 10 : 이 측정항목은 상위 10개 검색 결과에서 관련 결과의 수를 측정합니다.
- 역수 순위 : 첫 번째 "정답" 순위의 곱셈 역수입니다. 1위는 1, 2위는 1/2, 3위는 1/3 등입니다.
- 예상 상호 순위(ERR) 등급별 관련성을 갖춘 상호 순위의 확장으로 사용자가 관련 문서를 찾는 데 소요되는 예상 상호 시간 길이를 측정합니다.
- 평균 정밀도 : 정밀도-재현율 곡선 아래의 영역입니다.
- 10의 NDCG : 10의 정규화된 할인 누적 이득; 참조: https://en.wikipedia.org/w/index.php?title=Discounted_cumulative_gain§ion=4#Normalized_DCG
- F-Measure : 정밀도보다 기억력을 β배 더 중요하게 생각하는 사용자에 대한 검색 효과를 측정합니다. RRE는 가장 인기 있는 세 가지 F-Measure 인스턴스인 F0.5, F1 및 F2를 제공합니다.
쿼리 수준에서 계산되는 "리프" 메트릭 외에도 RRE는 동일한 메트릭을 여러 수준에서 집계할 수 있는 풍부한 중첩 데이터 모델을 제공합니다. 예를 들어 쿼리는 쿼리 그룹으로 그룹화되고 쿼리 그룹은 주제로 그룹화됩니다. 이는 산술 평균을 집계 기준으로 사용하여 위에 나열된 동일한 측정항목을 상위 수준에서도 사용할 수 있음을 의미합니다. 그 결과 RRE는 다음과 같은 측정항목도 제공합니다.
- 평균 평균 정밀도 : 쿼리 수준에서 계산된 평균 정밀도의 평균입니다.
- 평균 상호 순위 : 쿼리 수준에서 계산된 상호 순위의 평균입니다.
- 위에 나열된 다른 모든 측정항목은 산술 평균으로 집계됩니다.
위 스크린샷에서 볼 수 있는 가장 중요한 것 중 하나는 RRE가 평가 중인 시스템의 여러 버전을 추적하고 비교할 수 있다는 것입니다.
검색 시스템을 개발하고 발전시킬 때 증분/반복/불변 접근 방식을 권장합니다. 버전 1.0에서 시작한다고 가정하면 구성에 관련 변경 사항을 적용할 때 해당 버전을 변경하는 대신 해당 버전을 복제하고 적용하는 것이 좋습니다. 새 버전으로 변경합니다(1.1이라고 하겠습니다).
이러한 방식으로 시스템 빌드가 발생하면 RRE는 사용 가능한 각 버전에 대해 위에 설명된 모든 내용(즉, 측정항목)을 계산합니다.
또한, 후속 버전 간의 델타/트렌드를 제공하므로 관련성 향상 측면에서 시스템이 어디로 향하고 있는지 전반적인 방향을 즉시 파악할 수 있습니다.



