korpatbert
1.0.0
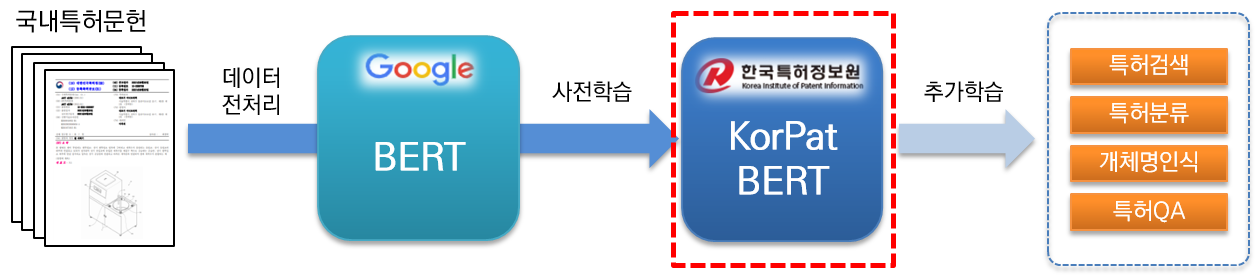
KorPatBERT(Korean Patent BERT)는 한국특허정보원이 연구개발한 AI 언어모델입니다.
특허분야 한국어 자연어처리 문제 해결 및 특허산업분야의 지능정보화 인프라 마련을 위해 기존 Google BERT base 모델의 아키텍쳐를 기반으로 대용량 국내 특허문헌
(base: 약 406만 문헌, large: 약 506만 문헌)을 사전학습(pre-training)하였고, 무료로 제공하고 있습니다.
특허분야 특화된 고성능 사전학습(pre-trained) 언어모델로 다양한 자연어처리 태스크에서 활용 할 수 있습니다.
[KorPatBERT-base]
[KorPatBERT-large]
[KorPatBERT-base]
[KorPatBERT-large]
언어모델 학습에 사용된 특허문헌을 대상으로 약 1,000만개의 주요 명사 및 복합명사를 추출하였으며, 이를 한국어 형태소분석기 Mecab-ko의 사용자 사전에 추가 후 Google SentencePiece를 통하여 Subword로 분할하는 방식의 특허 텍스트에 특화된 MSP 토크나이저(Mecab-ko Sentencepiece Patent Tokenizer)입니다.
| 모델 | Top@1(ACC) |
|---|---|
| Google BERT | 72.33 |
| KorBERT | 73.29 |
| KoBERT | 33.75 |
| KrBERT | 72.39 |
| KorPatBERT-base | 76.32 |
| KorPatBERT-large | 77.06 |
| 모델 | Top@1(ACC) | Top@3(ACC) | Top@5(ACC) |
|---|---|---|---|
| KorPatBERT-base | 61.91 | 82.18 | 86.97 |
| KorPatBERT-large | 62.89 | 82.18 | 87.26 |
| 프로그램명 | 버전 | 설치안내 경로 | 필수여부 |
|---|---|---|---|
| python | 3.6 이상 | https://www.python.org/ | Y |
| anaconda | 4.6.8 이상 | https://www.anaconda.com/ | N |
| tensorflow | 2.2.0 이상 | https://www.tensorflow.org/install/pip?hl=ko | Y |
| sentencepiece | 0.1.96 이상 | https://github.com/google/sentencepiece | N |
| mecab-ko | 0.996-ko-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-python | 0.996-ko-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| python-mecab-ko | 1.0.11 이상 | https://pypi.org/project/python-mecab-ko/ | Y |
| keras | 2.4.3 이상 | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0.14.4 이상 | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0 이상 | https://github.com/tqdm/tqdm | N |
| soynlp | 0.0.493 이상 | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ Google BERT base 학습 방식과 동일하며, 사용 예시는 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 2.3절 참조하세요.
한국특허정보원 언어모델에 관심 있는 기관·기업, 연구자를 대상으로 일정한 절차를 통해 보급을 수행 중에 있습니다. 아래의 사용신청 절차에 따라 사용신청서 및 협약서를 작성하시어 담당자의 이메일로 신청·접수를 하시면 됩니다.
| 파일명 | 설명 |
|---|---|
| pat_all_mecab_dic.csv | Mecab 특허사용자사전 |
| lm_test_data.tsv | 분류 샘플 데이터 셋 |
| korpat_tokenizer.py | KorPat Tokenizer 프로그램 |
| test_tokenize.py | Tokenizer 사용 샘플 |
| test_tokenize.ipynb | Tokenizer 사용 샘플 (주피터) |
| test_lm.py | 언어모델 사용 샘플 |
| test_lm.ipynb | 언어모델 사용 샘플 (주피터) |
| korpat_bert_config.json | KorPatBERT Config 파일 |
| korpat_vocab.txt | KorPatBERT Vocabulary 파일 |
| model.ckpt-381250.meta | KorPatBERT Model 파일 |
| model.ckpt-381250.index | KorPatBERT Model 파일 |
| model.ckpt-381250.data-00000-of-00001 | KorPatBERT Model 파일 |


