wagtail_textract
1.0.0
이 패키지는 유지 관리되지 않으며 유지 관리할 계획이 없습니다.
예제로 사용하는 것이 좋습니다. 코드를 자신의 프로젝트에 복사하되 패키지를 설치하지 마세요.
이 패키지는 Wagtail의 Document 클래스를 textract를 사용하여 문서 파일 내용을 검색할 수 있는 클래스로 대체하기 위한 것입니다.
Textract는 PDF, Excel 및 Word 파일에서 텍스트를 추출할 수 있습니다.
이 패키지는 Wagtail의 "검색: 문서에서 텍스트 추출" 문제에서 영감을 받았습니다.
Wagtail 관리 인터페이스의 문서 검색이 파일 내용에서도 검색어를 찾는다는 점을 제외하면 문서는 이전과 같이 작동합니다.
설명하기 위한 일부 스크린샷.
wagtail_textract 가 설치된 새로운 Wagtail 사이트에 손으로 쓴 텍스트가 포함된 test_document.pdf 라는 파일을 업로드했습니다. 문서 아래의 관리 인터페이스에 나열됩니다.
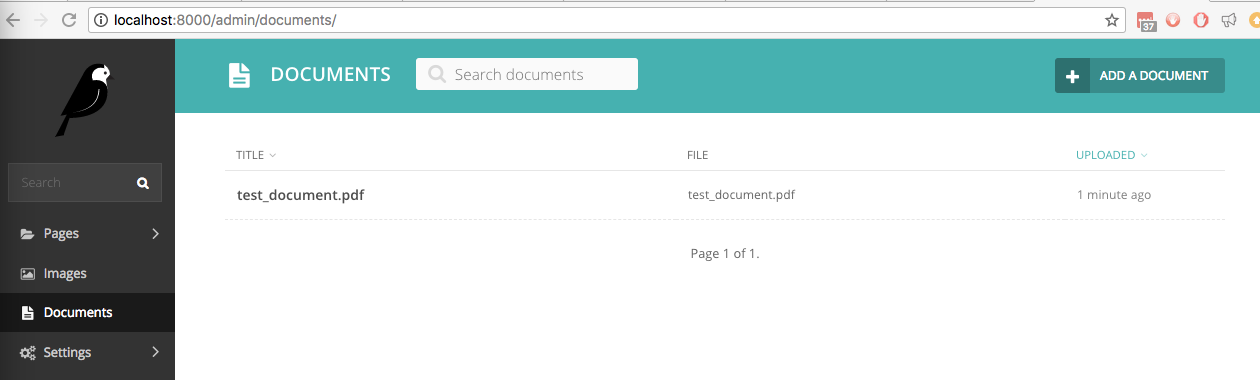
이제 문서에서 손으로 쓴 단어 중 하나인 correct 단어를 검색하면 실시간 검색에서 해당 단어를 찾습니다.
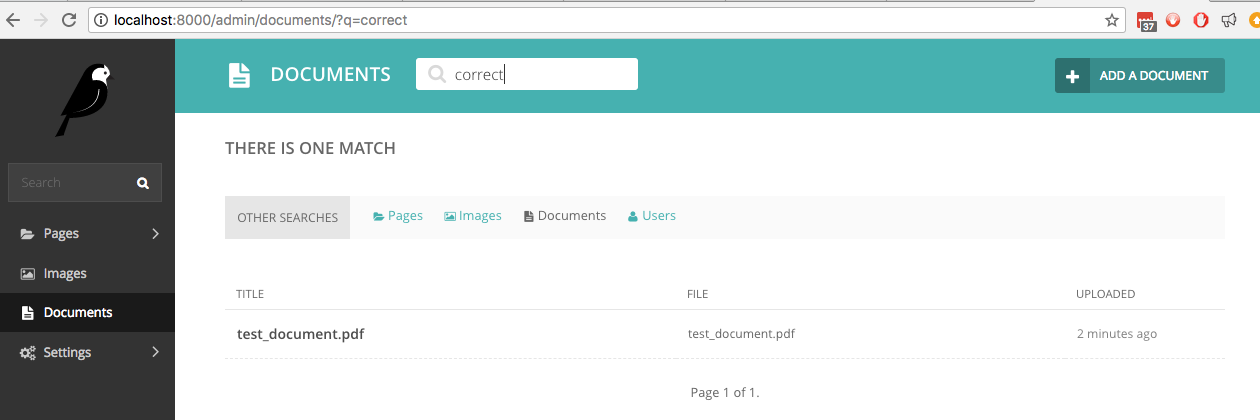
이 검색은 Wagtail의 관리 인터페이스뿐만 아니라 코드 예제를 제공하는 공개 검색 보기에서도 사용할 수 있어야 한다고 가정합니다.
우리는 2018년 8월부터 https://nuffic.nl에서 이 패키지를 프로덕션에 사용해 왔습니다.
wagtail_textract 추가하거나 pip install wagtail_textractINSTALLED_APPS 에 추가하세요.WAGTAILDOCS_DOCUMENT_MODEL = "wagtail_textract.document" 입력하세요.참고: wagtail_texttract(Wagtail 2.0.1 설치) 설치 중에 비호환성 경고가 표시됩니다.
requests 2.18.4 has requirement chardet<3.1.0,>=3.0.2, but you'll have chardet 2.3.0 which is incompatible.
textract 1.6.1 has requirement beautifulsoup4==4.5.3, but you'll have beautifulsoup4 4.6.0 which is incompatible.
이것이 문제로 이어지는 것을 본 적은 없지만 명심해야 할 사항이 있습니다.
textract Tesseract를 사용하도록 하려면(일반 textract 텍스트를 찾지 못하는 경우) Tesseract가 단어 일치의 기반이 될 수 있는 데이터 파일을 추가해야 합니다.
프로젝트 디렉터리에 tessdata 디렉터리를 만들고 원하는 언어를 다운로드하세요.
처리 중 응답이 차단되는 것을 방지하기 위해 asyncio 실행기에서 문서 저장 후 전사가 자동으로 수행됩니다.
모든 기존 문서를 기록하려면 관리 명령을 실행하십시오.
./manage.py transcribe_documents
분명히 시간이 오래 걸릴 수 있습니다.
다음은 페이지 및 문서 결과를 모두 표시하는 검색 보기(Wagtail의 관리 인터페이스 외부)에 대한 코드 예제입니다.
from itertools import chain
from wagtail . core . models import Page
from wagtail . documents . models import get_document_model
def search ( request ):
# Search
search_query = request . GET . get ( 'query' , None )
if search_query :
page_results = Page . objects . live (). search ( search_query )
document_results = Document . objects . search ( search_query )
search_results = list ( chain ( page_results , document_results ))
# Log the query so Wagtail can suggest promoted results
Query . get ( search_query ). add_hit ()
else :
search_results = Page . objects . none ()
# Render template
return render ( request , 'website/search_results.html' , {
'search_query' : search_query ,
'search_results' : search_results ,
}) 문서에서는 pageurl result 수행할 수 없기 때문에 템플릿에서는 페이지와 다르게 문서 처리를 허용해야 합니다.
{% if result . file %}
< a href = " {{ result.url }} " >{{ result }}</ a >
{% else %}
< a href = " {% pageurl result %} " >{{ result }}</ a >
{% endif %} wagtail_texttract를 사용하려면 CustomizedDocument 모델이 wagtail_texttract의 문서와 동일한 작업을 수행해야 합니다.
TranscriptionMixinsearch_fields 변경 from wagtail_textract . models import TranscriptionMixin
class CustomizedDocument ( TranscriptionMixin , ...):
"""Extra fields and methods for Document model."""
search_fields = ... + [
index . SearchField (
'transcription' ,
partial_match = False ,
),
] 하위 클래스의 첫 번째 클래스는 TranscriptionMixin 이어야 하므로 해당 save() 다른 상위 클래스보다 우선합니다.
테스트를 실행하려면 이 저장소를 체크아웃하고 다음을 수행하세요.
make test
적용 범위 보고서는 ./coverage_html_report/ 에 생성됩니다.


