SeekStorm
v0.11.0

SeekStorm 은 Rust 로 구현된 오픈 소스, 밀리초 미만의 전체 텍스트 검색 라이브러리이자 다중 테넌트 서버 입니다.
2015년 개발 시작, 2020년부터 생산, 2023년 Rust 포트, 2024년 오픈 소스 작업이 진행 중입니다.
SeekStorm은 Apache License 2.0에 따라 오픈 소스 라이센스가 부여됩니다.
블로그 게시물: SeekStorm은 이제 오픈 소스이며 SeekStorm은 패싯 검색, 지리적 근접 검색, 결과 정렬 기능을 제공합니다.
쿼리 유형
결과 유형
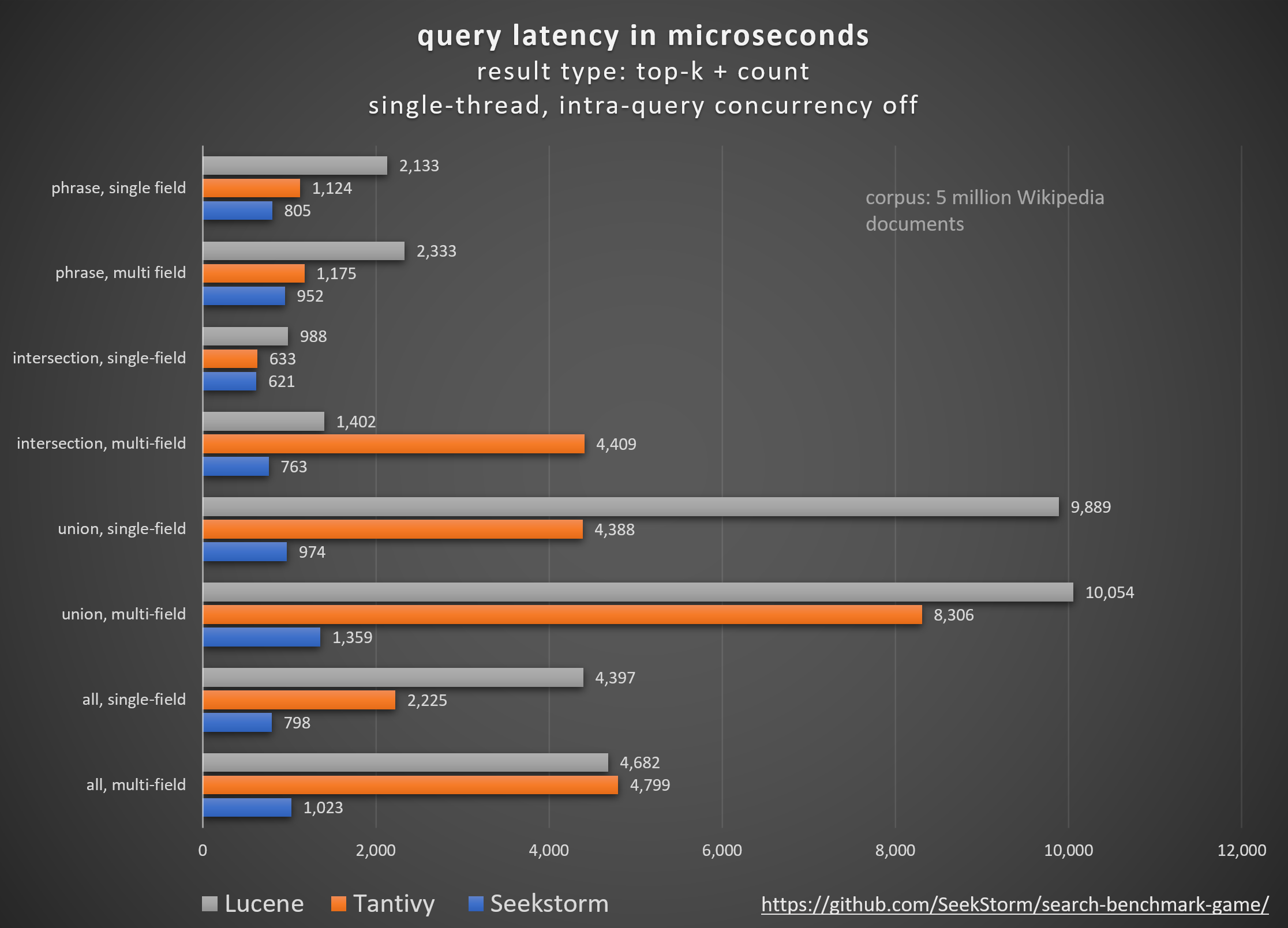
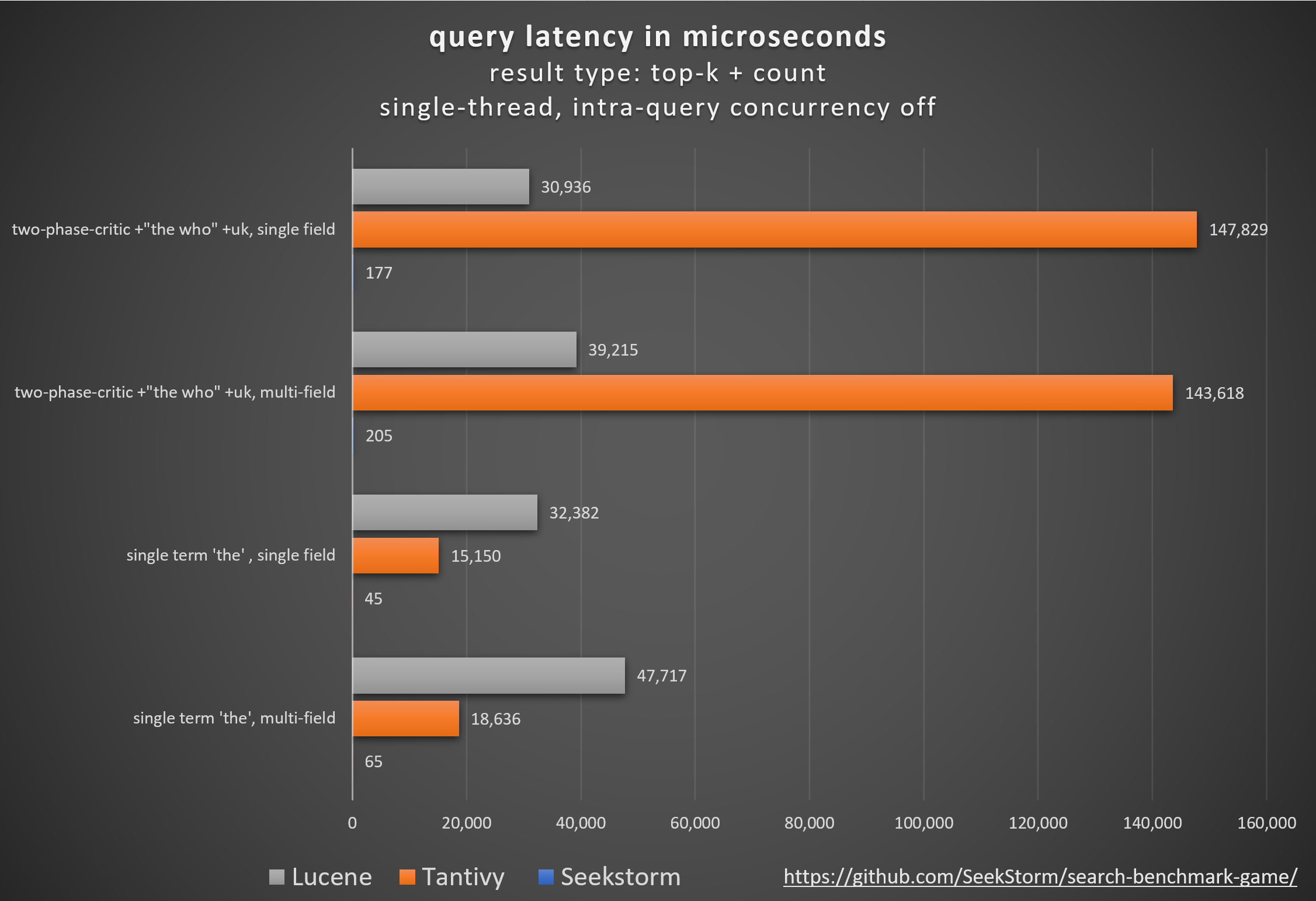
성능
특히 대기 시간이 짧고 처리량이 높으며 비용 및 에너지 소비가 적습니다. 다중 필드 및 동시 쿼리의 경우.
낮은 테일 대기 시간은 원활한 사용자 경험을 보장하고 고객 및 수익 손실을 방지합니다.
일부는 성능 향상을 위해 독점 하드웨어 가속기(FPGA/ASIC) 또는 클러스터에 의존하지만,
SeekStorm은 단일 상용 서버에서 알고리즘적으로 유사한 부스트를 달성합니다.
일관성
SeekStorm은 리소스 집약적인 세그먼트 병합을 요구하지 않으므로 대용량 인덱싱 도중 및 이후에 예측할 수 없는 쿼리 대기 시간이 없습니다.
안정적인 대기 시간 - 적시 컴파일로 인한 콜드 스타트 비용이 없고 예측할 수 없는 가비지 수집 지연이 없습니다.
스케일링
수십억 규모의 인덱스에도 낮은 대기 시간, 높은 처리량, 낮은 RAM 소비를 유지합니다.
무제한 필드 수, 필드 길이 및 인덱스 크기.
관련성
용어 근접성 순위는 BM25에 비해 더 관련성이 높은 결과를 제공합니다.
실시간
NRT와 반대되는 진정한 실시간 검색: 인덱싱된 모든 문서는 커밋 전과 커밋 중에도 즉시 검색 가능합니다.
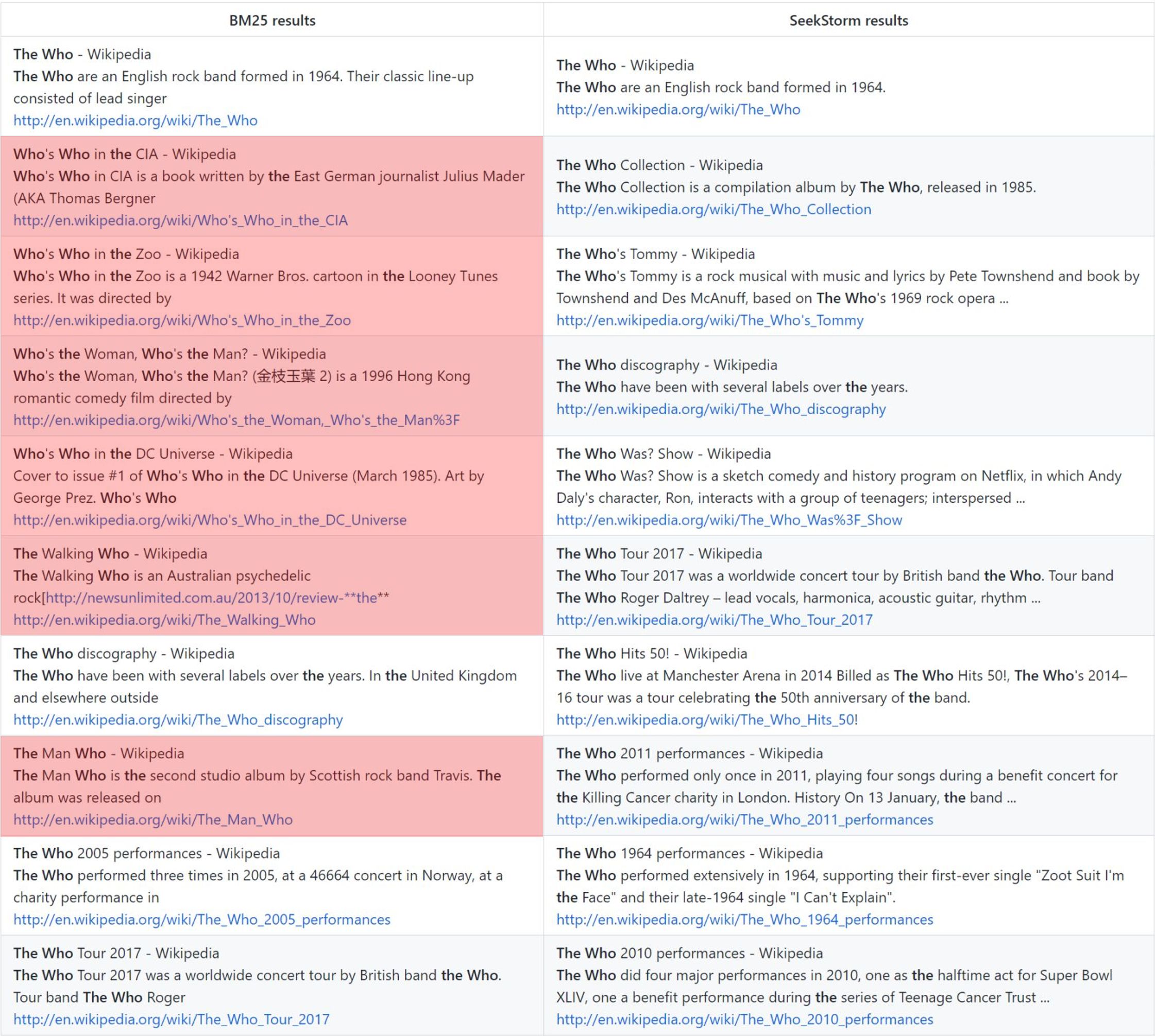
누가: 바닐라 BM25 순위 vs. SeekStorm 근접성 순위
방법론
Tantivy와 Jason Wolfe가 개발한 오픈 소스 search_benchmark_game을 사용하여 다양한 오픈 소스 검색 엔진 라이브러리(BM25 어휘 검색)를 비교합니다.
이익
자세한 벤치마크 결과 https://seekstorm.github.io/search-benchmark-game/
벤치마크 코드 저장소 https://github.com/SeekStorm/search-benchmark-game/
자세한 내용은 블로그 게시물을 참조하세요. SeekStorm은 이제 오픈 소스이며 SeekStorm은 패싯 검색, 지리적 근접 검색, 결과 정렬 기능을 제공합니다.
https://www.bitecode.dev/p/hype-cycles의 과대광고에서 여러분이 믿기를 바라는 내용에도 불구하고 NoSQL이 SQL의 죽음이 아니었기 때문에 키워드 검색은 죽지 않았습니다.
도구 상자를 유지 관리하고 현재 작업에 가장 적합한 도구를 선택해야 합니다. https://seekstorm.com/blog/Vector-search-vs-keyword-search1/
키워드 검색은 일련의 문서에 대한 필터일 뿐이며 특정 키워드가 포함된 항목을 반환하며 일반적으로 BM25와 같은 순위 측정 항목과 결합됩니다. 매우 기본적이고 핵심적인 기능으로, 낮은 지연 시간으로 대규모로 구현하기가 매우 어렵습니다. 기능이 워낙 기본적이다보니 적용분야가 무궁무진합니다. 다른 구성요소와 함께 사용되는 구성요소입니다. 오늘날 벡터 검색과 LLM을 통해 더 잘 해결할 수 있는 사용 사례가 있지만 더 많은 경우에는 키워드 검색이 여전히 최고의 솔루션입니다. 키워드 검색은 정확하고 무손실이며 매우 빠르며 더 나은 확장성, 더 나은 대기 시간, 더 낮은 비용 및 에너지 소비를 제공합니다. 벡터 검색은 의미론적 유사성을 바탕으로 작동하며, 주어진 근접성과 확률 내에서 결과를 반환합니다.
고유명사, 번호, 자동차 번호판, 도메인 이름, 문구(예: 표절 탐지)와 같은 정확한 결과를 검색하는 경우 키워드 검색이 도움이 됩니다. 반면에 벡터 검색은 의미상으로만 관련이 있는 수많은 결과 중에서 찾고 있는 정확한 결과를 묻습니다. 동시에, 정확한 용어를 모르거나 더 넓은 주제, 의미 또는 동의어에 관심이 있는 경우 정확한 용어가 사용되더라도 키워드 검색은 실패합니다.
- works with text data only
- unable to capture context, meaning and semantic similarity
- low recall for semantic meaning
+ perfect recall for exact keyword match
+ perfect precision (for exact keyword match)
+ high query speed and throughput (for large document numbers)
+ high indexing speed (for large document numbers)
+ incremental indexing fully supported
+ smaller index size
+ lower infrastructure cost per document and per query, lower energy consumption
+ good scalability (for large document numbers)
+ perfect for exact keyword and phrase search, no false positives
+ perfect explainability
+ efficient and lossless for exact keyword and phrase search
+ works with new vocabulary out of the box
+ works with any language out of the box
+ works perfect with long-tail vocabulary out of the box
+ works perfect with any rare language or domain-specific vocabulary out of the box
+ RAG (Retrieval-augmented generation) based on keyword search offers unrestricted real-time capabilities.벡터 검색은 정확한 검색어를 모르거나 정확한 검색어가 사용되는 것과 관계없이 더 넓은 주제, 의미 또는 동의어에 관심이 있는 경우에 적합합니다. 그러나 고유명사, 번호, 자동차 번호판, 도메인 이름, 문구(예: 표절 탐지)와 같은 정확한 용어를 찾고 있다면 항상 키워드 검색을 사용해야 합니다. 벡터 검색은 어떤 식으로든 관련이 있는 수많은 결과 중에서 찾고 있는 정확한 결과를 묻을 뿐입니다. 재현율은 좋지만 정밀도가 낮고 대기 시간이 높습니다. 예를 들어 표절 탐지에서 정확한 단어와 단어 순서가 손실되어 거짓 긍정이 발생하기 쉽습니다.
벡터 검색을 사용하면 유사한 텍스트뿐만 아니라 벡터로 변환할 수 있는 모든 것(텍스트, 이미지(얼굴 인식, 지문), 오디오)을 검색할 수 있으며 여왕 - 여자 + 남자 = 왕과 같은 마법 같은 일을 할 수 있습니다. .
+ works with any data that can be transformed to a vector: text, image, audio ...
+ able to capture context, meaning, and semantic similarity
+ high recall for semantic meaning (90%)
- lower recall for exact keyword match (for Approximate Similarity Search)
- lower precision (for exact keyword match)
- lower query speed and throughput (for large document numbers)
- lower indexing speed (for large document numbers)
- incremental indexing is expensive and requires rebuilding the entire index periodically, which is extremely time-consuming and resource intensive.
- larger index size
- higher infrastructure cost per document and per query, higher energy consumption
- limited scalability (for large document numbers)
- unsuitable for exact keyword and phrase search, many false positives
- low explainability makes it difficult to spot manipulations, bias and root cause of retrieval/ranking problems
- inefficient and lossy for exact keyword and phrase search
- Additional effort and cost to create embeddings and keep them updated for every language and domain. Even if the number of indexed documents is small, the embeddings have to created from a large corpus before nevertheless.
- Limited real-time capability due to limited recency of embeddings
- works only with vocabulary known at the time of embedding creation
- works only with the languages of the corpus from which the embeddings have been derived
- works only with long-tail vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- works only with rare language or domain-specific vocabulary that was sufficiently represented in the corpus from which the embeddings have been derived
- RAG (Retrieval-augmented generation) based on vector search offers only limited real-time capabilities, as it can't process new vocabulary that arrived after the embedding generation벡터 검색은 키워드 검색을 대체하는 것이 아니라 보완적인 추가 기능입니다. 두 접근 방식의 장점이 결합된 하이브리드 솔루션 내에서 사용하는 것이 가장 좋습니다. 키워드 검색은 시대에 뒤떨어지지 않지만 오랜 세월에 걸쳐 검증되었습니다 .
SeekStorm 코드베이스를 C#에서 Rust로 (부분적으로) 이식했습니다.
Rust는 빅 데이터 및/또는 많은 동시 사용자를 처리하는 성능이 중요한 애플리케이션에 적합합니다. 빠른 알고리즘은 성능을 고려한 프로그래밍 언어로 더욱 빛을 발할 것입니다.
ARCHITECTURE.md 참조
cargo build --release
경고 : MASTER_KEY_SECRET 환경 변수를 비밀로 설정해야 합니다. 그렇지 않으면 생성된 API 키가 손상될 수 있습니다.
https://docs.rs/seekstorm
문서 작성
cargo doc --no-deps
로컬에서 문서에 액세스
SeekStormtargetdocseekstormindex.html
SeekStormtargetdocseekstorm_serverindex.html
프로젝트에 필요한 상자를 추가하세요
cargo add seekstorm
cargo add tokio
cargo add serde_json use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;비동기 Rust 런타임을 사용하세요
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {인덱스 생성
let index_path= Path :: new ( "C:/index/" ) ;
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":false,"indexed":false}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let _index_arc = Arc :: new ( RwLock :: new ( index ) ) ;인덱스 열기(또는 인덱스 생성)
let index_path= Path :: new ( "C:/index/" ) ;
let mut index_arc= open_index ( index_path , false ) . await . unwrap ( ) ; 색인 문서
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1"},
{"title":"title2","body":"body2 test","url":"url2"},
{"title":"title3 test","body":"body3 test","url":"url3"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; 문서 커밋
index_arc . commit ( ) . await ;검색 색인
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter ) . await ;결과 표시
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_string ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter= Some ( highlighter ( & index_arc , highlights , result_object . query_term_strings ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let mut index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}멀티스레드 검색
let query_vec= vec ! [ "house" .to_string ( ) , "car" .to_string ( ) , "bird" .to_string ( ) , "sky" .to_string ( ) ] ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Union ;
let result_type= ResultType :: TopkCount ;
let thread_number = 4 ;
let permits = Arc :: new ( Semaphore :: new ( thread_number ) ) ;
for query in query_vec {
let permit_thread = permits . clone ( ) . acquire_owned ( ) . await . unwrap ( ) ;
let query_clone = query . clone ( ) ;
let index_arc_clone = index_arc . clone ( ) ;
let query_type_clone = query_type . clone ( ) ;
let result_type_clone = result_type . clone ( ) ;
let offset_clone = offset ;
let length_clone = length ;
tokio :: spawn ( async move {
let rlo = index_arc_clone
. search (
query_clone ,
query_type_clone ,
offset_clone ,
length_clone ,
result_type_clone ,
false ,
Vec :: new ( ) ,
)
. await ;
println ! ( "result count {}" , rlo.result_count ) ;
drop ( permit_thread ) ;
} ) ;
}JSON, 줄 바꿈으로 구분된 JSON 및 연결된 JSON 형식의 인덱스 JSON 파일
let file_path= Path :: new ( "wiki_articles.json" ) ;
let _ =index_arc . ingest_json ( file_path ) . await ;디렉토리 및 하위 디렉토리의 모든 PDF 파일 색인화
ingest 명령에 의해 자동으로 생성됨). [
{
"field" : " title " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text " ,
"boost" : 10
},
{
"field" : " body " ,
"stored" : true ,
"indexed" : true ,
"field_type" : " Text "
},
{
"field" : " url " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Text "
},
{
"field" : " date " ,
"stored" : true ,
"indexed" : false ,
"field_type" : " Timestamp " ,
"facet" : true
}
] let file_path= Path :: new ( "C:/Users/johndoe/Downloads" ) ;
let _ =index_arc . ingest_pdf ( file_path ) . await ;색인 PDF 파일
let file_path= Path :: new ( "C:/test.pdf" ) ;
let file_date= Utc :: now ( ) . timestamp ( ) ;
let _ =index_arc . index_pdf_file ( file_path ) . await ;색인 PDF 파일 바이트
let file_date= Utc :: now ( ) . timestamp ( ) ;
let document = fs :: read ( file_path ) . unwrap ( ) ;
let _ =index_arc . index_pdf_bytes ( file_path , file_date , & document ) . await ;PDF 파일 바이트 가져오기
let doc_id= 0 ;
let file=index . get_file ( doc_id ) . unwrap ( ) ;인덱스 지우기
index . clear_index ( ) ;인덱스 삭제
index . delete_index ( ) ;인덱스 닫기
index . close_index ( ) ;Seekstorm 라이브러리 버전 문자열
let version= version ( ) ;
println ! ( "version {}" ,version ) ;패싯은 3가지 다른 위치에서 정의됩니다.
패싯 인덱싱 및 검색의 최소 작업 예제에는 단 60줄의 코드만 필요합니다. 그러나 문서만으로 모든 것을 하나로 묶는 것은 지루할 수 있습니다. 이것이 바로 여기에서 빠른 시작 예시를 제공하는 이유입니다.
프로젝트에 필요한 상자를 추가하세요
cargo add seekstorm
cargo add tokio
cargo add serde_json사용 선언 추가
use std :: { collections :: HashSet , error :: Error , path :: Path , sync :: Arc } ;
use seekstorm :: { index :: * , search :: * , highlighter :: * , commit :: Commit } ;
use tokio :: sync :: RwLock ;비동기 Rust 런타임을 사용하세요
# [ tokio :: main ]
async fn main ( ) -> Result < ( ) , Box < dyn Error + Send + Sync > > {인덱스 생성
let index_path= Path :: new ( "C:/index/" ) ; //x
let schema_json = r#"
[{"field":"title","field_type":"Text","stored":false,"indexed":false},
{"field":"body","field_type":"Text","stored":true,"indexed":true},
{"field":"url","field_type":"Text","stored":true,"indexed":false},
{"field":"town","field_type":"String","stored":false,"indexed":false,"facet":true}]"# ;
let schema=serde_json :: from_str ( schema_json ) . unwrap ( ) ;
let meta = IndexMetaObject {
id : 0 ,
name : "test_index" . to_string ( ) ,
similarity : SimilarityType :: Bm25f ,
tokenizer : TokenizerType :: AsciiAlphabetic ,
access_type : AccessType :: Mmap ,
} ;
let serialize_schema= true ;
let segment_number_bits1= 11 ;
let index= create_index ( index_path , meta , & schema , serialize_schema , & Vec :: new ( ) , segment_number_bits1 , false ) . unwrap ( ) ;
let mut index_arc = Arc :: new ( RwLock :: new ( index ) ) ;색인 문서
let documents_json = r#"
[{"title":"title1 test","body":"body1","url":"url1","town":"Berlin"},
{"title":"title2","body":"body2 test","url":"url2","town":"Warsaw"},
{"title":"title3 test","body":"body3 test","url":"url3","town":"New York"}]"# ;
let documents_vec=serde_json :: from_str ( documents_json ) . unwrap ( ) ;
index_arc . index_documents ( documents_vec ) . await ; 문서 커밋
index_arc . commit ( ) . await ;검색 색인
let query= "test" . to_string ( ) ;
let offset= 0 ;
let length= 10 ;
let query_type= QueryType :: Intersection ;
let result_type= ResultType :: TopkCount ;
let include_uncommitted= false ;
let field_filter= Vec :: new ( ) ;
let query_facets = vec ! [ QueryFacet :: String { field: "age" .to_string ( ) ,prefix: "" .to_string ( ) ,length: u16 :: MAX } ] ;
let facet_filter= Vec :: new ( ) ;
//let facet_filter = vec![FacetFilter::String { field: "town".to_string(),filter: vec!["Berlin".to_string()],}];
let facet_result_sort= Vec :: new ( ) ;
let result_object = index_arc . search ( query , query_type , offset , length , result_type , include_uncommitted , field_filter , query_facets , facet_filter ) . await ;결과 표시
let highlights : Vec < Highlight > = vec ! [
Highlight {
field: "body" .to_owned ( ) ,
name: String ::new ( ) ,
fragment_number: 2 ,
fragment_size: 160 ,
highlight_markup: true ,
} ,
] ;
let highlighter2= Some ( highlighter ( & index_arc , highlights , result_object . query_terms ) ) ;
let return_fields_filter= HashSet :: new ( ) ;
let index=index_arc . write ( ) . await ;
for result in result_object . results . iter ( ) {
let doc=index . get_document ( result . doc_id , false , & highlighter2 , & return_fields_filter ) . unwrap ( ) ;
println ! ( "result {} rank {} body field {:?}" , result.doc_id,result.score, doc.get ( "body" ) ) ;
}디스플레이 패싯
println ! ( "{}" , serde_json::to_string_pretty ( &result_object.facets ) .unwrap ( ) ) ;주요 기능 끝
Ok ( ( ) )
} SeekStorm 서버를 사용하여 Wikipedia 코퍼스에서 Wikipedia 검색 엔진을 구축하는 방법에 대한 간단한 5단계 튜토리얼입니다.

SeekStorm 다운로드
GitHub 저장소에서 SeekStorm을 다운로드하세요.
원하는 디렉터리에 압축을 풀고 Visual Studio 코드로 엽니다.
또는 대안적으로
git clone https://github.com/SeekStorm/SeekStorm.git
SeekStorm 구축
Rust를 설치하세요(아직 없는 경우): https://www.rust-lang.org/tools/install
Visual Studio Code의 터미널에서 다음을 입력합니다.
cargo build --release
Wikipedia 자료 받기
사전 처리된 영어 Wikipedia 자료(5,032,105개 문서, 압축 해제된 8,28GB). wiki-articles.json의 확장자는 .JSON이지만 유효한 JSON 파일은 아닙니다. 모든 줄에는 URL, 제목 및 본문 속성이 있는 JSON 개체가 포함되어 있는 텍스트 파일입니다. 형식은 ndjson("Newline delimited JSON")이라고 합니다.
Wikipedia 말뭉치 다운로드
Wikipedia 말뭉치를 압축 해제합니다.
https://gnuwin32.sourceforge.net/packages/bzip2.htm
bunzip2 wiki-articles.json.bz2
압축이 풀린 wiki-articles.json을 릴리스 디렉터리로 이동합니다.
SeekStorm 서버 시작
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
인덱싱
실행 중인 SeekStorm 서버의 명령줄에 'ingest'를 입력합니다.
ingest
그러면 데모 색인이 생성되고 로컬 위키피디아 파일의 색인이 생성됩니다.
내장된 WebUI 내에서 검색 시작
브라우저에서 내장된 웹 UI 열기: http://127.0.0.1
검색창에 검색어를 입력하세요
REST API 엔드포인트 테스트
VSC 확장 "Rest 클라이언트"와 함께 VSC에서 src/seekstorm_server/test_api.rest를 열어 API 호출을 실행하고 응답을 검사합니다.
대화형 API 엔드포인트 예
위에서 'index'를 입력했을 때 서버 콘솔에 표시되는 api 키로 test_api.rest의 '개별 API 키'를 설정합니다.
데모 색인 삭제
실행 중인 SeekStorm 서버의 명령줄에 'delete'를 입력하세요.
delete
서버 종료
실행 중인 SeekStorm 서버의 명령줄에 'quit'을 입력합니다.
quit
커스터마이징
자신의 프로젝트에 비슷한 것을 사용하고 싶습니까? 수집 및 웹 UI 설명서를 살펴보세요.
SeekStorm 서버를 사용하여 PDF 파일이 포함된 디렉터리에서 PDF 검색 엔진을 구축하는 방법에 대한 빠른 단계별 자습서입니다.
집이나 조직에서 모든 과학 논문, 전자책, 이력서, 보고서, 계약서, 문서, 매뉴얼, 편지, 은행 명세서, 송장, 배송 메모를 검색 가능하게 만드세요.
SeekStorm 구축
Rust를 설치하세요(아직 없는 경우): https://www.rust-lang.org/tools/install
Visual Studio Code의 터미널에서 다음을 입력합니다.
cargo build --release
PDFium 다운로드
Pdfium 라이브러리를 다운로드하여eekstorm_server.exe와 동일한 폴더에 복사하십시오: https://github.com/bblanchon/pdfium-binaries
SeekStorm 서버 시작
cd target/release
./seekstorm_server local_ip="0.0.0.0" local_port=80
인덱싱
색인화하고 검색하려는 PDF 파일이 포함된 디렉토리(예: 문서 또는 다운로드 디렉토리)를 선택하십시오.
실행 중인 SeekStorm 서버의 명령줄에 'ingest'를 입력합니다.
ingest C:UsersJohnDoeDownloads
그러면 pdf_index가 생성되고 하위 디렉토리를 포함하여 지정된 디렉토리의 모든 PDF 파일이 색인화됩니다.
내장된 WebUI 내에서 검색 시작
브라우저에서 내장된 웹 UI 열기: http://127.0.0.1
검색창에 검색어를 입력하세요
데모 색인 삭제
실행 중인 SeekStorm 서버의 명령줄에 'delete'를 입력하세요.
delete
서버 종료
실행 중인 SeekStorm 서버의 명령줄에 'quit'을 입력합니다.
quit
전체 텍스트 검색 3천만 개의 Hacker News 게시물 및 링크된 웹 페이지
DeepHN.org
DeepHN 데모는 여전히 SeekStorm C# 코드베이스를 기반으로 합니다.
현재 누락된 필수 기능을 모두 포팅하는 중입니다.
아래 로드맵을 참조하세요.
Rust 포트는 아직 기능이 완성되지 않았습니다. 현재 다음 기능이 이식되었습니다.
포팅
개량
새로운 기능


