elastic_transformers
1.0.0
문장 변환기를 사용한 Semantic Elasticsearch. 우리는 Elastic의 강력한 기능과 BERT의 마법을 사용하여 백만 개의 기사를 색인화하고 이에 대한 어휘 및 의미 검색을 수행할 것입니다.
목적은 NLP 변환기를 사용하여 상황별 임베딩/의미론적 검색의 거의 최첨단 기능을 통해 자체 Elasticsearch를 설정하는 사용하기 쉬운 방법을 제공하는 것입니다.
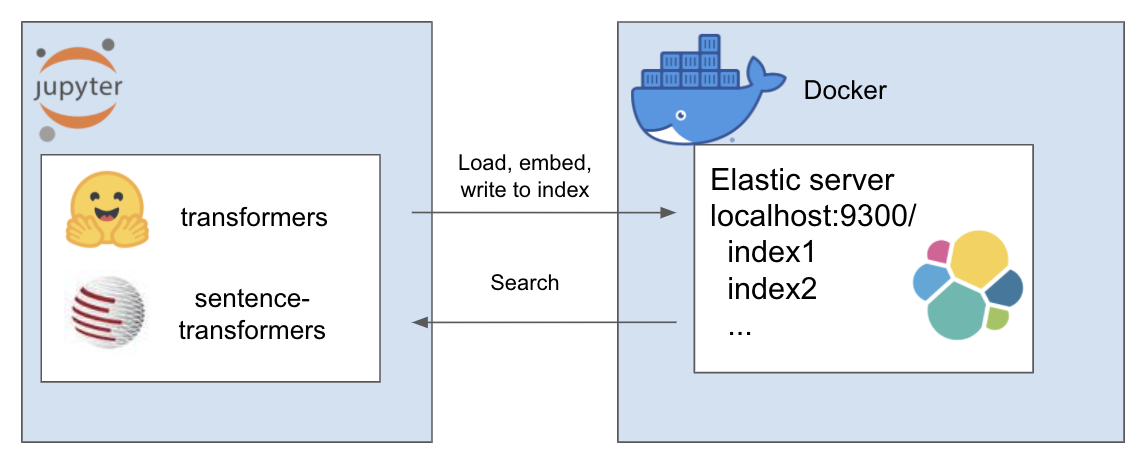
위의 설정은 다음과 같이 작동합니다
내 환경은 et 라고 불리며 이를 위해 conda를 사용합니다. 프로젝트 디렉토리 내부 탐색
conda create - - name et python = 3.7
conda install - n et nb_conda_kernels
conda activate et
pip install - r requirements . txt이 튜토리얼에서는 Rohk의 A Million News Headlines를 사용하고 이를 프로젝트 디렉토리 내의 데이터 폴더에 배치합니다.
elastic_transformers/
├── data/
그렇지 않으면 단계가 상당히 추상화되어 있으므로 선택한 데이터 세트를 사용하여 이 작업을 수행할 수도 있습니다.
여기 Elastic 페이지에서 Docker로 Elastic을 설정하는 지침을 따르세요. 이 튜토리얼에서는 다음 두 단계만 실행하면 됩니다.
저장소에서는 ElasiticTransformers 클래스를 소개합니다. 임베딩을 포함하는 Elasticsearch 인덱스를 생성, 색인 및 쿼리하는 데 도움이 되는 유틸리티
연결 링크와 함께 작업할 인덱스 이름(선택 사항)을 시작합니다.
et = ElasticTransformers ( url = 'http://localhost:9300' , index_name = 'et-tiny' )create_index_spec은 인덱스에 대한 매핑을 정의합니다. 키워드 검색이나 의미(밀도 벡터) 검색을 위해 관련 필드 목록을 제공할 수 있습니다. 또한 밀집 벡터의 크기에 대한 매개변수가 있습니다. create_index - 이전에 생성된 사양을 사용하여 검색 준비가 된 인덱스를 생성합니다.
et . create_index_spec (
text_fields = [ 'publish_date' , 'headline_text' ],
dense_fields = [ 'headline_text_embedding' ],
dense_fields_dim = 768
)
et . create_index ()write_large_csv - 큰 csv 파일을 청크로 나누고 사전 정의된 임베딩 유틸리티를 반복적으로 사용하여 각 청크에 대한 임베딩 목록을 생성한 후 결과를 인덱스에 제공합니다.
et . write_large_csv ( 'data/tiny_sample.csv' ,
chunksize = 1000 ,
embedder = embed_wrapper ,
field_to_embed = 'headline_text' )검색 - 키워드(Elastic에서는 '일치') 또는 의미론적(Elastic에서는 밀도가 높음) 검색을 선택할 수 있습니다. 특히 write_large_csv에 사용된 것과 동일한 임베딩 기능이 필요합니다.
et . search ( query = 'search these terms' ,
field = 'headline_text' ,
type = 'match' ,
embedder = embed_wrapper ,
size = 1000 )성공적으로 설정한 후 다음 노트북을 사용하여 이 모든 작업을 수행하세요.
이 저장소는 뛰어난 사람들의 다음과 같은 놀라운 작품을 결합합니다. 아직 확인하지 않으셨다면 그들의 작업을 확인해 보세요...


