lieu
vements
대체 검색 엔진
하이퍼텍스트 검색 및 발견의 사용과 관련된 무관심 환경에 대응하여 만들어졌습니다. 대신 인터넷은 검색 가능한 것이 아니라 자신의 이웃입니다. 다르게 말하면 Lieu는 개인 웹링을 통해 우연한 연결을 증가시키는 방법인 동네 검색 엔진입니다.
전체 검색 구문( site: 및 -site: 사용 방법 포함)은 검색 구문 및 API 설명서를 참조하세요. 더 많은 팁을 보려면 부록을 읽어보세요.
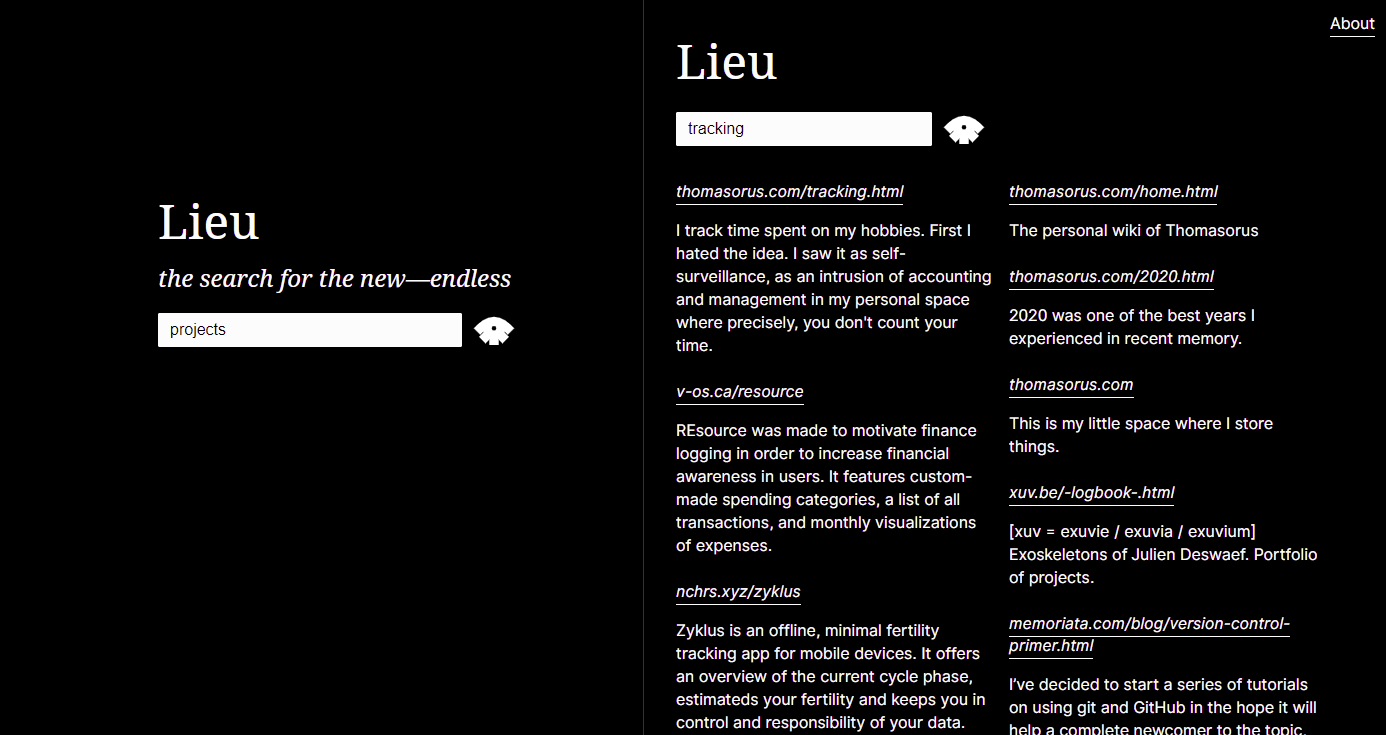
$ lieu help
Lieu: neighbourhood search engine
Commands
- precrawl (scrapes config's general.url for a list of links: <li> elements containing an anchor <a> tag)
- crawl (start crawler, crawls all urls in config's crawler.webring file)
- ingest (ingest crawled data, generates database)
- search (interactive cli for searching the database)
- host (hosts search engine over http)
Example:
lieu precrawl > data/webring.txt
lieu crawl > data/crawled.txt
lieu ingest
lieu host
Lieu의 크롤링 및 사전 크롤링 명령은 데이터를 쉽게 검사할 수 있도록 표준 출력으로 출력됩니다. 일반적으로 구성 파일에 정의된 대로 Lieu가 읽는 파일로 출력을 리디렉션하려고 합니다. 일반적인 작업 흐름은 아래를 참조하세요.
config.crawler.webring 에서 크롤링할 도메인을 추가하세요.url 필드를 해당 페이지로 설정하십시오.precrawl 으로 크롤링할 도메인 목록 채우기: lieu precrawl > data/webring.txtlieu crawl > data/crawled.txtlieu ingestlieu host lieu ingest 로 데이터를 수집한 후 lieu search 로 터미널에서 자료를 검색하는 데 lieu를 사용할 수도 있습니다.
아래에 지정된 구성의 theme 값을 조정합니다.
구성 파일은 TOML로 작성됩니다.
[ general ]
name = " Merveilles Webring "
# used by the precrawl command and linked to in /about route
url = " https://webring.xxiivv.com "
# used by the precrawl command to populate the Crawler.Webring file;
# takes simple html selectors. might be a bit wonky :)
webringSelector = " li > a[href]:first-of-type "
port = 10001
[ theme ]
# colors specified in hex (or valid css names) which determine the theme of the lieu instance
# NOTE: If (and only if) all three values are set lieu uses those to generate the file html/assets/theme.css at startup.
# You can also write directly to that file istead of adding this section to your configuration file
foreground = " #ffffff "
background = " #000000 "
links = " #ffffff "
[ data ]
# the source file should contain the crawl command's output
source = " data/crawled.txt "
# location & name of the sqlite database
database = " data/searchengine.db "
# contains words and phrases disqualifying scraped paragraphs from being presented in search results
heuristics = " data/heuristics.txt "
# aka stopwords, in the search engine biz: https://en.wikipedia.org/wiki/Stop_word
wordlist = " data/wordlist.txt "
[ crawler ]
# manually curated list of domains, or the output of the precrawl command
webring = " data/webring.txt "
# domains that are banned from being crawled but might originally be part of the webring
bannedDomains = " data/banned-domains.txt "
# file suffixes that are banned from being crawled
bannedSuffixes = " data/banned-suffixes.txt "
# phrases and words which won't be scraped (e.g. if a contained in a link)
boringWords = " data/boring-words.txt "
# domains that won't be output as outgoing links
boringDomains = " data/boring-domains.txt "
# queries to search for finding preview text
previewQueryList = " data/preview-query-list.txt "사용자가 직접 사용하려면 다음 구성 필드를 사용자 정의해야 합니다.
nameurlportsourcewebringbannedDomains다음 구성 정의 파일은 특정 요구 사항이 없는 한 그대로 유지될 수 있습니다.
databaseheuristicswordlistbannedSuffixespreviewQueryList파일 및 다양한 작업에 대한 전체 요약을 보려면 파일 설명을 참조하세요.
바이너리를 빌드합니다.
# this project has an experimental fulltext-search feature, so we need to include sqlite's fts engine (fts5)
go build --tags fts5
# or using go run
go run --tags fts5 . 새 릴리스 바이너리를 만듭니다.
./release.sh 소스 코드 AGPL-3.0-or-later , Inter는 SIL OPEN FONT LICENSE Version 1.1 에서 사용할 수 있으며 Noto Serif는 Apache License, Version 2.0 으로 라이센스가 부여됩니다.


