VSA
1.0.0
[프로젝트 페이지] [?Paper] [?허깅 페이스 스페이스] [모델 동물원] [소개] [?영상]

git clone https://github.com/cnzzx/VSA.git
cd VSA
conda create -n vsa python=3.10
conda activate vsa
cd models/LLaVA
pip install -e .
pip install -r requirements.txt
로컬 데모는 Gradio를 기반으로 하며 다음을 사용하여 간단히 실행할 수 있습니다.
python app.py
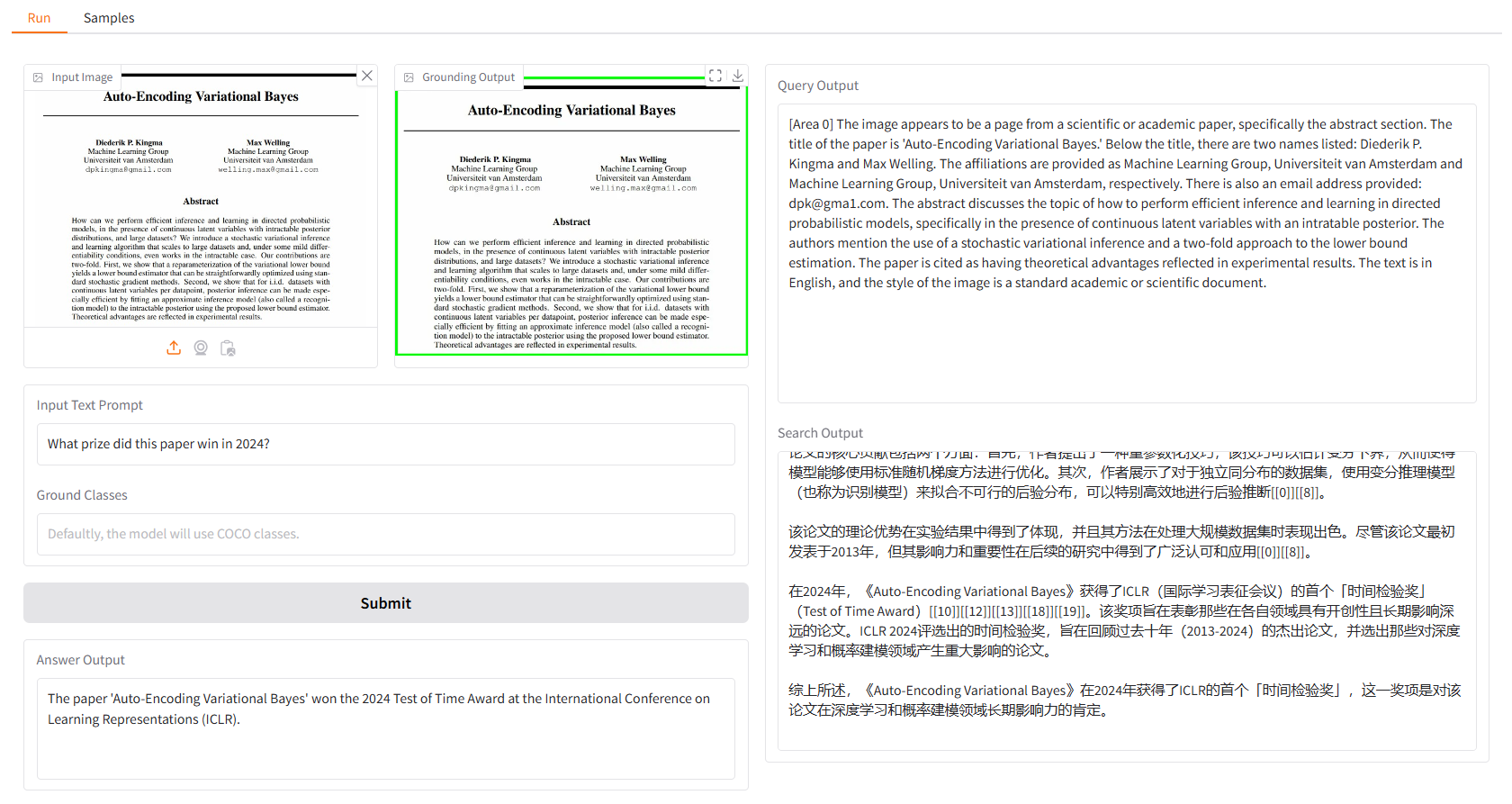
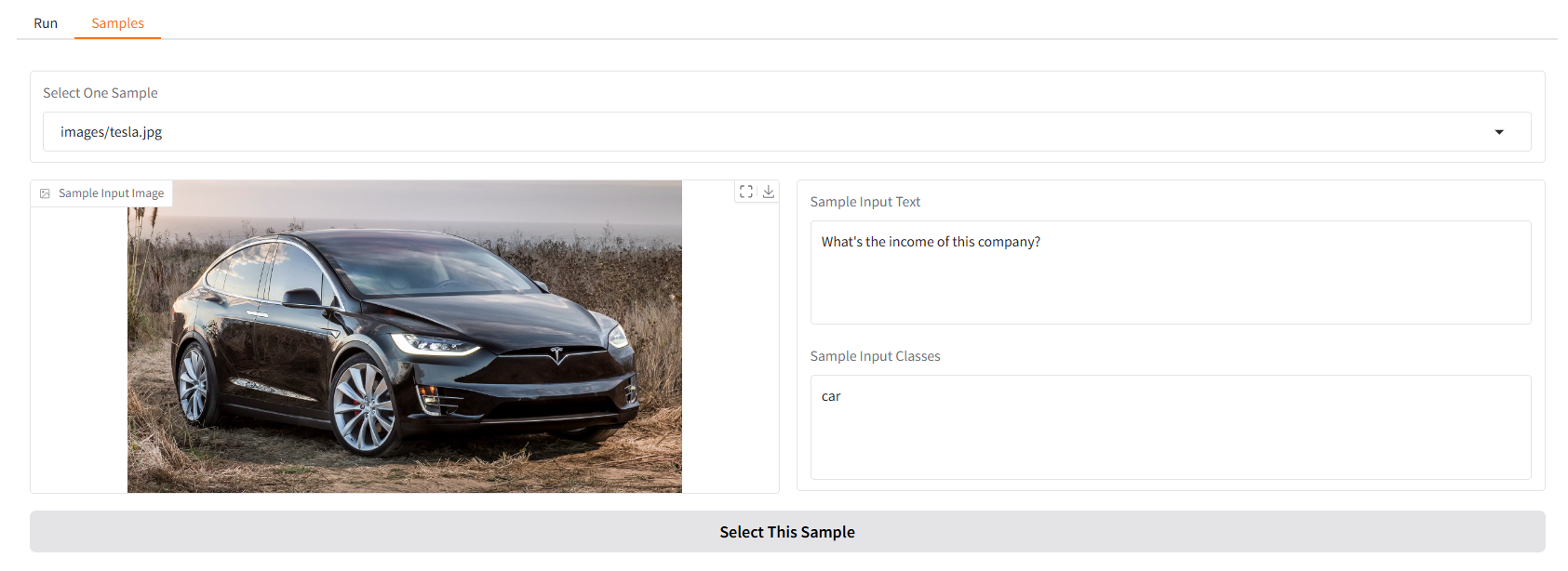
우리는 당신이 시작할 수 있는 몇 가지 샘플을 제공합니다. "샘플" UI의 "샘플" 패널에서 하나를 선택하고 "이 샘플 선택"을 클릭하면 "실행" UI에 샘플 입력이 이미 채워져 있는 것을 확인할 수 있습니다.
터미널에서 다음을 실행하여 Vision Search Assistant와 채팅할 수도 있습니다.
python cli.py
--vlm-model "liuhaotian/llava-v1.6-vicuna-7b"
--ground-model "IDEA-Research/grounding-dino-base"
--search-model "internlm/internlm2_5-7b-chat"
--vlm-load-4bit
그런 다음 이미지를 선택하고 질문을 입력하세요.
이 프로젝트는 Apache 2.0 라이센스에 따라 릴리스됩니다.
Vision Search Assistant는 오픈 소스 커뮤니티에 대한 다음과 같은 뛰어난 기여에서 큰 영감을 받았습니다: GroundingDINO, LLaVA, MindSearch.
이 프로젝트가 귀하의 연구에 유용하다고 생각되면 다음을 인용해 보십시오.
@article{zhang2024visionsearchassistantempower,
title={Vision Search Assistant: Empower Vision-Language Models as Multimodal Search Engines},
author={Zhang, Zhixin and Zhang, Yiyuan and Ding, Xiaohan and Yue, Xiangyu},
journal={arXiv preprint arXiv:2410.21220},
year={2024}
}


