ndvr
1.0.0
신경망 검색 해커톤 2위?
우리는 인터넷에서 수십억 개의 비디오를 사용할 수 있는 다양한 비디오 공유 웹사이트에서 비디오 데이터의 폭발적인 증가를 목격했습니다. 대규모 비디오 데이터베이스에서 거의 중복된 비디오 검색(NDVR)을 수행하는 것이 주요 과제가 되었습니다. NDVR은 대규모 비디오 데이터베이스에서 거의 중복된 비디오를 검색하는 것을 목표로 합니다. 여기서 거의 중복된 비디오는 원본 비디오에 시각적으로 가까운 비디오로 정의됩니다.
사용자는 인기를 끄는 짧은 동영상을 복사하고 관심을 끌기 위해 증강 버전을 업로드하려는 강력한 인센티브를 가지고 있습니다. 짧은 동영상이 성장함에 따라 거의 중복된 짧은 동영상을 감지하는 데 새로운 어려움과 어려움이 나타나고 있습니다.
여기에서는 NDVR 문제를 해결하기 위해 Jina를 사용하여 신경망 검색 솔루션을 구축했습니다.
목차

강력한 긍정 후보 동영상의 예입니다. 윗줄: 측면 처리, 색상 필터링 및 물세척. 가운데 행: 가로 화면이 검은색 여백이 큰 세로 화면으로 변경되었습니다. 하단 행: 회전됨
하드 네거티브 동영상의 예. 모든 후보는 쿼리와 시각적으로 유사하지만 거의 중복되지는 않습니다.
후보 동영상을 선택하는 데는 세 가지 전략이 있습니다.
우리는 시간과 자원의 제약으로 인해 변환 검색 전략을 사용하기로 결정했습니다. 실제 애플리케이션에서 사용자는 개인 인센티브를 위해 인기 동영상을 복사합니다. 사용자는 일반적으로 탐지를 우회하기 위해 복사한 비디오를 약간 수정하는 것을 선택합니다. 이러한 수정에는 비디오 자르기, 테두리 삽입 등이 포함됩니다.
이러한 사용자 행동을 모방하기 위해 우리는 하나의 시간적 변환, 즉 비디오 속도 향상과 세 가지 공간 변환, 즉 비디오 자르기, 검은색 테두리 삽입 및 비디오 회전을 정의합니다.
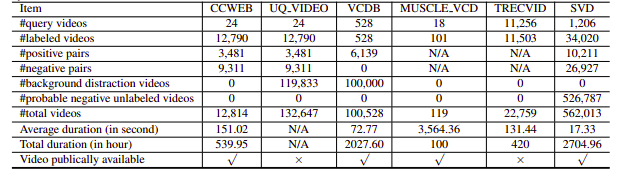
안타깝게도 연구된 NDVR 데이터 세트는 해상도가 낮거나 거대하거나 특정 도메인에 국한되거나 공개적으로 사용할 수 없었습니다(개인적으로 연락한 사람도 거의 없었습니다). 따라서 우리는 실험할 소규모 사용자 지정 데이터 세트를 만들기로 결정했습니다.
pip install --upgrade -r requirements.txtbash ./get_data.shpython app.py -t index인덱스 흐름은 다음과 같이 정의됩니다.
!Flow
with :
logserver : false
pods :
chunk_seg :
uses : craft/craft.yml
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
tf_encode :
uses : encode/encode.yml
needs : chunk_seg
parallel : $PARALLEL
read_only : true
timeout_ready : 600000
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
doc_idx :
uses : index/doc.yml
needs : gateway
join_all :
uses : _merge
needs : [doc_idx, chunk_idx]
read_only : true이는 다음 단계로 구분됩니다.
여기서는 YAML 파일을 사용하여 흐름을 정의하고 이를 사용하여 데이터를 인덱싱합니다. index 함수는 Iterator를 사용하여 파일 경로를 전달하는 input_fn 매개변수를 사용하며, 이 매개변수는 IndexRequest 에 추가로 래핑되어 흐름으로 전송됩니다.
DATA_BLOB = "./index-videos/*.mp4"
if task == "index" :
f = Flow (). load_config ( "flow-index.yml" )
with f :
f . index ( input_fn = input_index_data ( DATA_BLOB , size = num_docs ), batch_size = 2 ) def input_index_data ( patterns , size ):
def iter_file_exts ( ps ):
return it . chain . from_iterable ( glob . iglob ( p , recursive = True ) for p in ps )
d = 0
if isinstance ( patterns , str ):
patterns = [ patterns ]
for g in iter_file_exts ( patterns ):
yield g . encode ()
d += 1
if size is not None and d > size :
break python app.py -t query 그런 다음 사용자 정의 엔드포인트 http://localhost:45678/api/search 사용하여 Jinabox를 열 수 있습니다.
쿼리 흐름은 다음과 같이 정의됩니다.
!Flow
with :
logserver : true
read_only : true # better add this in the query time
pods :
chunk_seg :
uses : craft/index-craft.yml
parallel : $PARALLEL
tf_encode :
uses : encode/encode.yml
parallel : $PARALLEL
chunk_idx :
uses : index/chunk.yml
shards : $SHARDS
separated_workspace : true
polling : all
uses_reducing : _merge_all
timeout_ready : 100000 # larger timeout as in query time will read all the data
ranker :
uses : BiMatchRanker
doc_idx :
uses : index/doc.yml쿼리 흐름은 다음 단계로 구분됩니다.


