CrawlerTutorial
1.0.0
우리는 인터넷을 검색하다 보면 뉴스, 제품, 동영상, 사진 등 다양하고 흥미로운 콘텐츠를 자주 보게 됩니다. 그러나 이러한 웹 페이지에서 대량의 특정 정보를 수집하려는 경우 수동 작업은 시간이 많이 걸리고 힘들 것입니다.
이때 웹크롤러(Web Crawler)가 유용하게 쓰입니다! 간단히 말해서, 웹 크롤러는 인간 브라우저의 동작을 모방하여 자동으로 웹 정보를 크롤링할 수 있는 프로그램입니다. 이 프로그램의 자동화 기능을 사용하면 웹 사이트에서 관심 있는 데이터를 쉽게 "크롤링"한 다음 향후 분석을 위해 이 데이터를 저장할 수 있습니다.
웹 크롤러가 일반적으로 작동하는 방식은 먼저 대상 웹사이트에 HTTP 요청을 보낸 다음 웹사이트에서 HTML 응답을 얻고 페이지 콘텐츠를 구문 분석한 다음 유용한 데이터를 추출하는 것입니다. 예를 들어, PTT 가십 게시판에 올라온 기사의 제목, 작성자, 시간 및 기타 정보를 수집하려는 경우 웹 크롤러 기술을 사용하여 이 정보를 자동으로 캡처하고 저장할 수 있습니다. 이렇게 하면 수동으로 웹사이트를 탐색하지 않고도 필요한 정보를 얻을 수 있습니다.
웹 크롤러에는 다음과 같은 다양한 실제 응용 프로그램이 있습니다.
물론, 웹 크롤러를 사용할 때에는 웹사이트의 이용약관과 개인정보 보호정책을 준수해야 하며, 웹사이트의 규정을 위반하여 정보를 크롤링할 수 없습니다. 동시에 웹사이트의 정상적인 운영을 보장하기 위해 웹사이트에 과도한 부하가 걸리지 않도록 적절한 크롤링 전략을 설계해야 합니다.
이 튜토리얼에서는 Python3을 사용하며 pip를 사용하여 필수 패키지를 설치합니다. 다음 패키지를 설치해야 합니다.
requests : HTTP 요청 및 응답을 보내고 받는 데 사용됩니다.requests_html : HTML의 요소를 분석하고 크롤링하는 데 사용됩니다.rich : 아름다운 테이블을 표시하는 등 정보를 콘솔에 아름답게 출력하도록 합니다.lxml 또는 PyQuery : HTML의 요소를 구문 분석하는 데 사용됩니다.이러한 패키지를 설치하려면 다음 지침을 따르십시오.
pip install requests requests_html rich lxml PyQuery기본 장에서는 기사 제목, 저자, 시간 등 PTT 웹 페이지에서 정보를 수집하는 방법을 간략하게 소개합니다.
PTT의 버전 읽기 기사를 크롤러 대상으로 사용합시다!
웹 페이지를 크롤링할 때 requests.get() 함수를 사용하여 웹 페이지를 "탐색"하기 위해 HTTP GET 요청을 보내는 브라우저를 시뮬레이션합니다. 이 함수는 웹페이지의 응답 콘텐츠가 포함된 requests.Response .응답 개체를 반환합니다. 그러나 이 콘텐츠는 순수한 텍스트 소스 코드의 형태로 제공되며 브라우저에 의해 렌더링되지 않는다는 점에 유의해야 합니다. response.text 속성을 통해 이를 얻을 수 있습니다.
import requests
# 發送 HTTP GET 請求並獲取網頁內容
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests . get ( url )
print ( response . text )
이후 사용에서는 요청을 확장하기 위해 requests_html 사용해야 합니다 requests 브라우저처럼 탐색하는 것 외에도 requests_html 나중에 사용할 수 있도록 일반 텍스트 response.text 소스 코드 requests_html.HTML 패키지로 만듭니다. 재작성도 매우 간단합니다. 위의 requests.get() 대체하려면 session.get() 사용하세요.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text )그러나 이 방법을 Gossiping에 적용하려고 하면 오류가 발생할 수 있습니다. 그 이유는 우리가 처음으로 가십 게시판을 탐색할 때 웹사이트에서 우리가 18세 이상인지 확인하기 때문입니다. 우리가 확인을 클릭하면 다음 번에 다시 묻지 않도록 브라우저가 해당 쿠키를 기록하기 때문입니다. 다시 입력하세요(시크릿 모드를 사용하여 테스트를 열고 Bagua 보드 홈페이지를 살펴볼 수 있습니다). 그러나 웹 크롤러의 경우 탐색하는 동안 18세 테스트를 통과한 척할 수 있도록 이 특수 쿠키를 기록해야 합니다.
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
print ( response . text ) 다음으로, response.html.find() 메소드를 사용하여 요소를 찾고 CSS 선택기를 사용하여 대상 요소를 지정할 수 있습니다. 이 단계에서 PTT 웹 버전에서는 각 기사의 제목 정보가 r-ent 카테고리의 div 태그에 위치하는 것을 확인할 수 있습니다. 따라서 CSS 선택기 div.r-ent 사용하여 이러한 요소를 타겟팅할 수 있습니다.
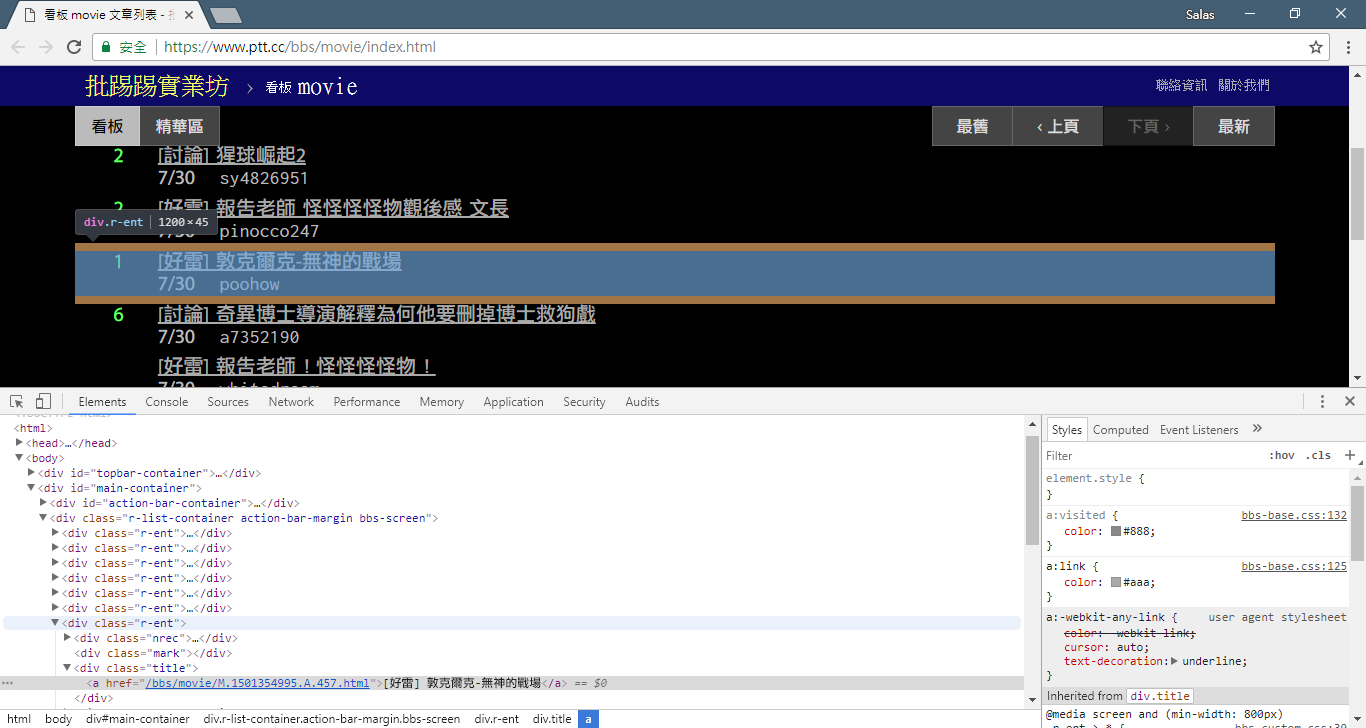
response.html.find() 메소드를 사용하면 조건을 충족하는 요소 목록이 반환되므로 for 루프를 사용하여 이러한 요소를 하나씩 처리할 수 있습니다. 각 요소 내에서 element.find() 메서드를 사용하여 요소를 추가로 구문 분석하고 CSS 선택기를 사용하여 추출할 정보를 지정할 수 있습니다. 이 예에서는 CSS 선택기 div.title 사용하여 제목 요소를 타겟팅할 수 있습니다. 마찬가지로, element.text 속성을 사용하여 요소의 텍스트 내용을 가져올 수 있습니다.
다음은 requests_html 을 사용한 샘플 코드입니다.
from requests_html import HTMLSession
# 建立 HTML 會話
session = HTMLSession ()
session . cookies . set ( 'over18' , '1' ) # 向網站回答滿 18 歲了 !
# 發送 HTTP GET 請求並獲取網頁內容
response = session . get ( url )
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
for element in elements :
# 提取資訊... 이전 단계에서는 response.html.find() 메서드를 사용하여 각 기사의 요소를 찾았습니다. 이러한 요소는 div.r-ent CSS 선택기를 사용하여 타겟팅됩니다. 개발자 도구 기능을 사용하여 웹 페이지의 요소 구조를 관찰할 수 있습니다. 웹 페이지를 열고 F12 키를 누르면 웹 페이지의 HTML 구조와 기타 정보가 포함된 개발자 도구 패널이 표시됩니다.
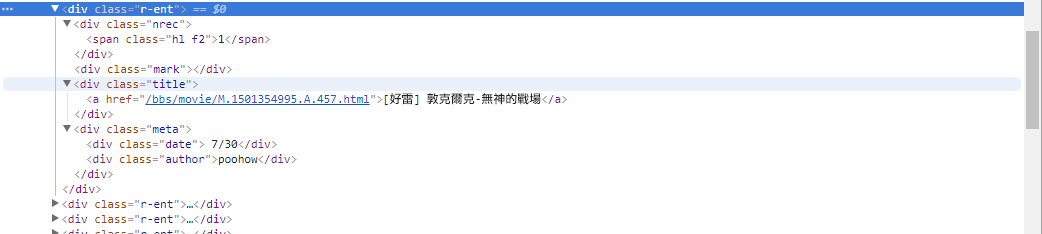
개발자 도구를 사용하면 마우스 포인터를 사용하여 웹페이지에서 특정 요소를 선택한 다음 개발자 도구 패널에서 요소의 HTML 구조, CSS 속성 및 기타 세부정보를 볼 수 있습니다. 이는 타겟팅할 요소와 해당 CSS 선택기를 결정하는 데 도움이 됩니다. 또한 프로그램이 때때로 잘못된 이유를 알 수 있습니까? ! 웹버전을 보니 해당 페이지의 글이 삭제되었을 때, 웹페이지의 <本文已被刪除> 요소의 소스코드結構원본과 다르다는 걸 발견했습니다! 그래서 기사가 삭제되는 상황에 대처할 수 있도록 더욱 강화할 수 있습니다.
이제 requests_html 을 사용하여 정보를 추출하는 샘플 코드로 돌아가겠습니다.
import re
# 使用 CSS 選擇器定位目標元素
elements = response . html . find ( 'div.r-ent' )
# 逐個處理每個元素
for element in elements :
# 可能會遇上文章已刪除的狀況,所以用例外處理 try-catch 包起來
try :
push = element . find ( '.nrec' , first = True ). text # 推文數
mark = element . find ( '.mark' , first = True ). text # 標記
title = element . find ( '.title' , first = True ). text # 標題
author = element . find ( '.meta > .author' , first = True ). text # 作者
date = element . find ( '.meta > .date' , first = True ). text # 發文日期
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ] # 文章網址
except AttributeError :
# 處理已經刪除的文章資訊
if '(本文已被刪除)' in title :
# e.g., "(本文已被刪除) [haudai]"
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
# e.g., "(已被cappa刪除) <edisonchu> op"
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
print ( '推文數:' , push )
print ( '標記:' , mark )
print ( '標題:' , title )
print ( '作者:' , author )
print ( '發文日期:' , date )
print ( '文章網址:' , link )
print ( '---' )출력 워드 프로세싱:
여기서는 rich 사용하여 아름다운 출력을 표시할 수 있습니다. 먼저 rich 테이블 개체를 만든 다음 위 예제 코드의 루프에서 print 테이블에 대한 add_row 로 바꿉니다. 마지막으로 rich 의 print 기능을 사용하여 테이블을 터미널에 올바르게 출력합니다.
실행 결과
import rich
import rich . table
# 建立 `rich` 表格物件,設定不顯示表頭
table = rich . table . Table ( show_header = False )
# 逐個處理每個元素
for element in elements :
...
# 將每個結果新增到表格中
table . add_row ( push , title , date , author )
# 使用 rich 套件的 print 函式輸出表格
rich . print ( table )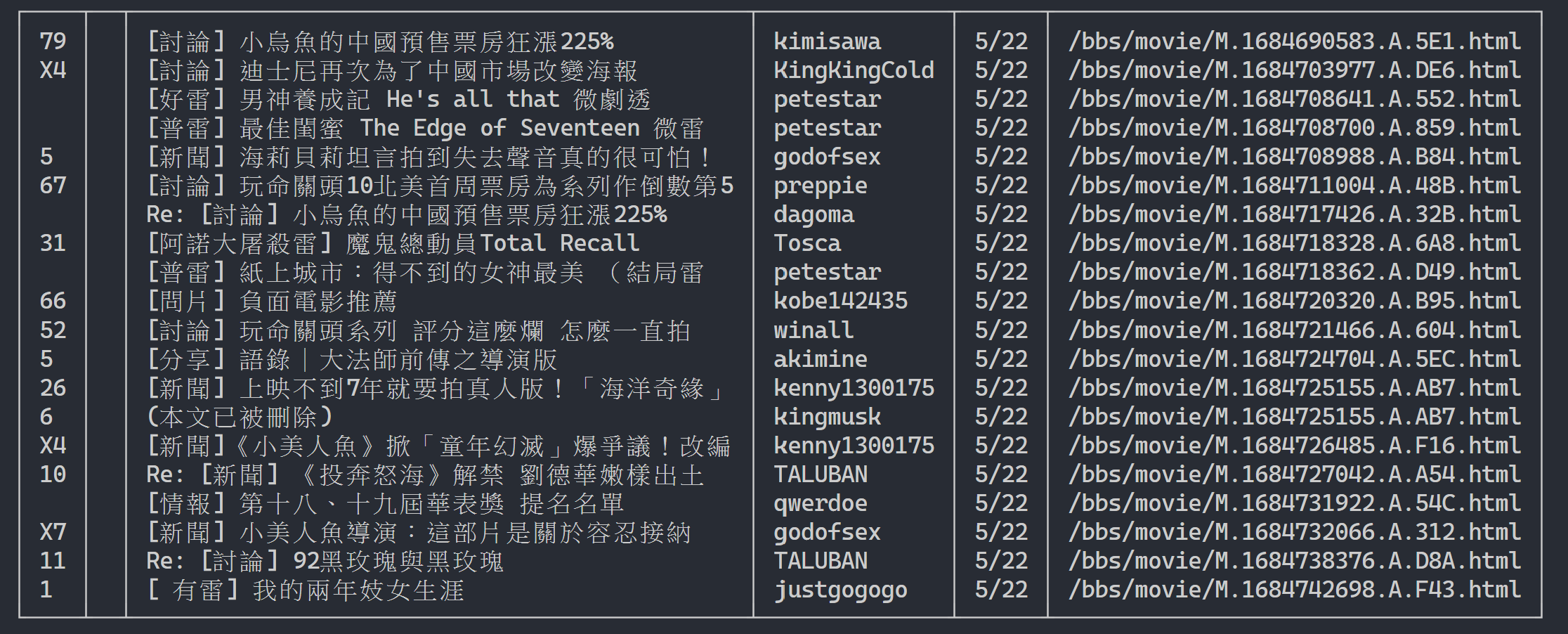
이제 "관찰 방법"을 사용하여 이전 페이지에 대한 링크를 찾아보겠습니다. 아니요, 브라우저에서 버튼이 어디에 있는지 묻는 것이 아니라 개발자 도구의 "소스 트리"가 어디에 있는지 묻는 것입니다. 나는 당신이 페이지 이동을 위한 하이퍼링크가 <div class="action-bar"> 의 <a class="btn wide"> 요소에 있다는 것을 발견했다고 믿습니다. 따라서 다음과 같이 추출할 수 있습니다.
# 控制頁面選項: 最舊/上頁/下頁/最新
controls = response . html . find ( '.action-bar a.btn.wide' )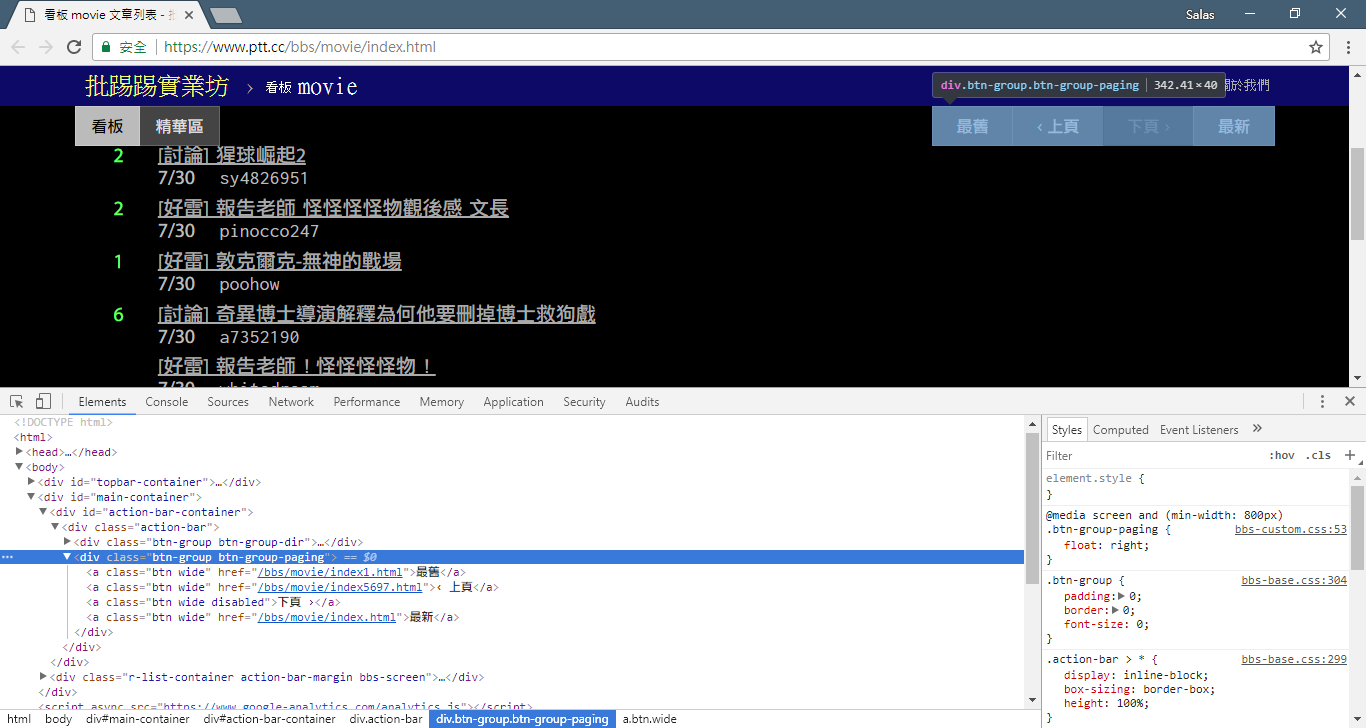
우리에게 필요한 것은 "이전 페이지" 기능입니다. 왜일까요? PTT는 최신 기사를 맨 앞에 표시하기 때문에 정보를 파헤치고 싶다면 앞으로 스크롤해야 한다.
그럼 어떻게 사용하나요? 먼저 control 에서 두 번째 href (색인은 1)를 가져오면 다음과 같이 보일 수 있습니다. /bbs/movie/index3237.html 전체 웹 사이트 주소(URL)는 https://www.ptt.cc/ 여야 합니다. 도메인 URL)이므로 urljoin() (또는 직접 문자열 연결)을 사용하여 영화 홈페이지 링크를 새 링크와 비교하고 완전한 URL로 병합하세요!
import urllib . parse
def parse_next_link ( controls ):
link = controls [ 1 ]. attrs [ 'href' ]
next_page_url = urllib . parse . urljoin ( 'https://www.ptt.cc/' , link )
return next_page_url 이제 후속 설명을 용이하게 하기 위해 함수를 재정렬해 보겠습니다. 3단계에서 각 기사 요소를 처리하는 예를 살펴보겠습니다. 이러한 제목 메시지를 독립적인 함수인 parse_article_entries(elements) 로 살펴보겠습니다.
# 解析該頁文章列表中的元素
def parse_article_entries ( elements ):
results = []
for element in elements :
try :
push = element . find ( '.nrec' , first = True ). text
mark = element . find ( '.mark' , first = True ). text
title = element . find ( '.title' , first = True ). text
author = element . find ( '.meta > .author' , first = True ). text
date = element . find ( '.meta > .date' , first = True ). text
link = element . find ( '.title > a' , first = True ). attrs [ 'href' ]
except AttributeError :
# 處理文章被刪除的情況
if '(本文已被刪除)' in title :
match_author = re . search ( '[(w*)]' , title )
if match_author :
author = match_author . group ( 1 )
elif re . search ( '已被w*刪除' , title ):
match_author = re . search ( '<(w*)>' , title )
if match_author :
author = match_author . group ( 1 )
# 將解析結果加到回傳的列表中
results . append ({ 'push' : push , 'mark' : mark , 'title' : title ,
'author' : author , 'date' : date , 'link' : link })
return results다음으로 다중 페이지 콘텐츠를 처리할 수 있습니다.
# 起始首頁
url = 'https://www.ptt.cc/bbs/movie/index.html'
# 想要收集的頁數
num_page = 10
for page in range ( num_page ):
# 發送 GET 請求並獲取網頁內容
response = session . get ( url )
# 解析文章列表的元素
results = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一個連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 建立表格物件
table = rich . table . Table ( show_header = False , width = 120 )
for result in results :
table . add_row ( * list ( result . values ()))
# 輸出表格
rich . print ( table )
# 更新下面一位 URL~
url = next_page_url출력 결과:
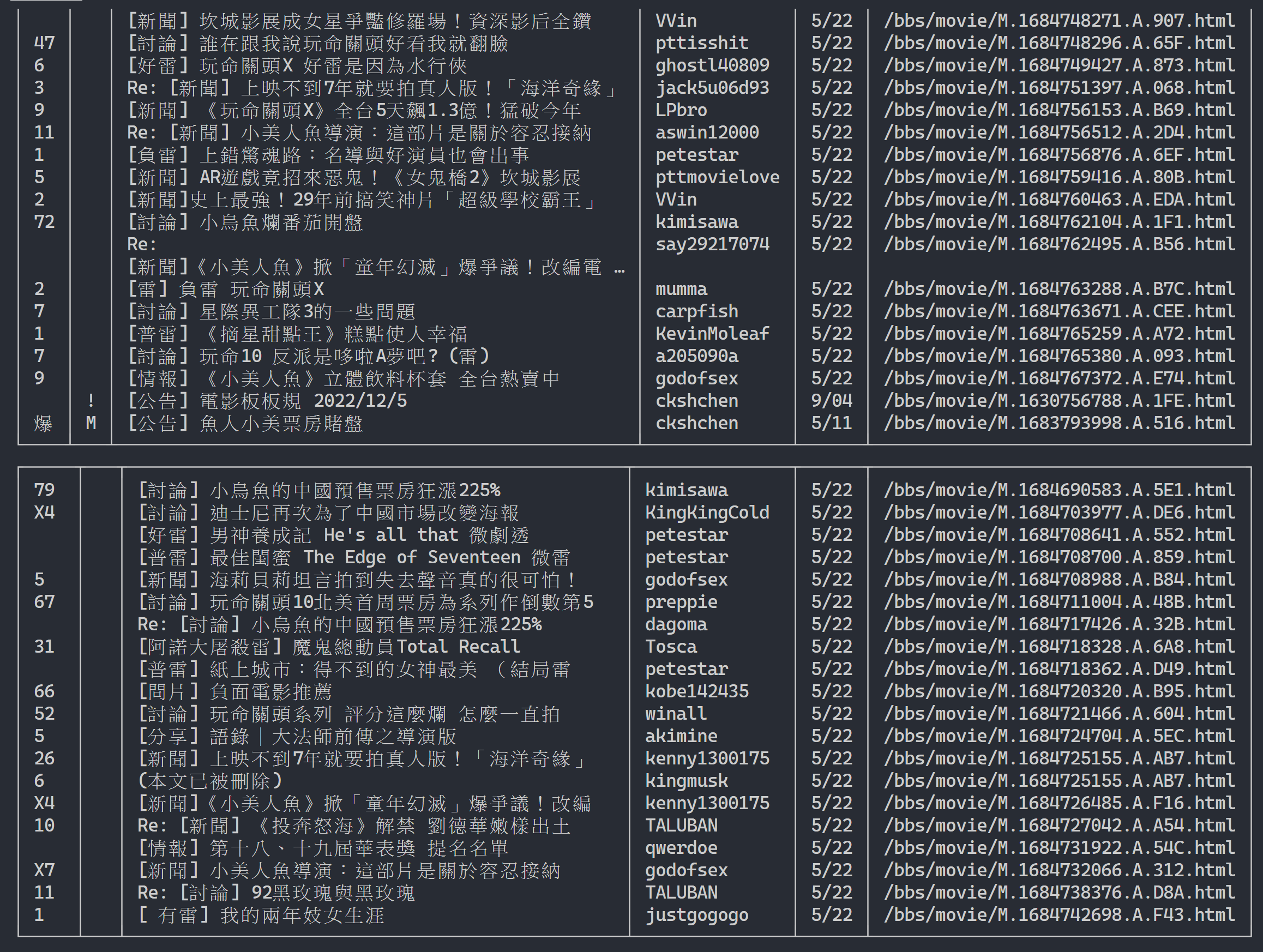
기사 목록 정보 획득 후, 다음 단계는 기사(PO 기사) 내용(게시물 내용) 획득! 메타데이터의 link 각 기사의 링크입니다. 또한 urllib.parse.urljoin 사용하여 전체 URL을 연결한 다음 HTTP GET을 실행하여 기사의 내용을 가져옵니다. 각 기사의 내용을 캡처하는 작업은 매우 반복적이며 병렬화 방법을 사용하여 처리하는 데 매우 적합하다는 것을 알 수 있습니다.
Python에서는 multiprocessing.Pool 사용하여 고급 멀티프로세싱 프로그래밍을 할 수 있습니다~ Python에서 멀티프로세스를 사용하는 가장 쉬운 방법입니다! 이는 SIMD(Single Instruction Multiple Data) 애플리케이션 시나리오에 매우 적합합니다. 사용 후 프로세스 리소스를 자동으로 해제하려면 with 문 구문을 사용하세요. ProcessPool의 사용법도 매우 간단합니다. pool.map(function, items) 은 함수형 프로그래밍의 개념과 약간 비슷합니다. 각 항목에 함수를 적용하고 최종적으로 항목과 동일한 수의 결과 목록을 얻습니다.
앞서 소개한 기사 콘텐츠 크롤링 작업에 사용됩니다.
from multiprocessing import Pool
def get_posts ( post_links ):
with Pool ( processes = 8 ) as pool :
# 建立 processes pool 並指定 processes 數量為 8
# pool 中的 processes 將用於同時發送多個 HTTP GET 請求,以獲取文章內容
responses = pool . map ( session . get , post_links )
# 使用 pool.map() 方法在每個 process 上都使用 session.get(),並傳入文章連結列表 post_links 作為參數
# 每個 process 將獨立地發送一個 HTTP GET 請求取得相應的文章內容
return responses
response = session . get ( url )
# 解析文章列表的元素
metadata = parse_article_entries ( elements = response . html . find ( 'div.r-ent' ))
# 解析下一頁的連結
next_page_url = parse_next_link ( controls = response . html . find ( '.action-bar a.btn.wide' ))
# 一串文章的 URL
post_links = [ urllib . parse . urljoin ( url , meta [ 'link' ]) for meta in metadata ]
results = get_posts ( post_links ) # list(requests_html.HTML)
rich . print ( results ) import time
if __name__ == '__main__' :
post_links = [...]
...
start_time = time . time ()
results = get_posts ( post_links )
print ( f'花費: { time . time () - start_time :.6f }秒,共 { len ( results ) } 篇文章' )실험 결과는 다음과 같습니다.
# with 1-process
花費: 15.686177秒,共 202 篇文章
# with 8-process
花費: 3.401658秒,共 202 篇文章전체 실행 속도가 거의 5배 빨라진 것을 볼 수 있지만, Process 많을수록 더 좋아집니다. CPU와 같은 하드웨어 사양 외에도 주로 네트워크 카드와 같은 외부 장치의 제한에 따라 달라집니다. 네트워크 속도.
위 코드는 ( src/basic_crawler.py )에서 찾을 수 있습니다!
PTT 웹의 새로운 기능: 검색! 마침내 웹 버전에서 사용 가능
또한 PTT의 영화 버전을 크롤러 대상으로 사용해 보겠습니다! 새로운 기능에서 검색할 수 있는 콘텐츠는 다음과 같습니다.
처음 세 개는 모두 새 버전의 페이지 소스 코드에서 규칙을 찾아 요청을 보낼 수 있지만 트윗 수 검색은 웹 버전 UI 인터페이스에 나타나지 않은 것 같습니다. 따라서 작성자가 PTT 網站原始碼에서 채굴한 매개변수는 다음과 같습니다. PTT 網站原始碼. 우리가 일반적으로 찾아보는 PTT에는 실제로 BBS 서버(즉, BBS)와 프런트엔드 웹 서버(웹 버전)가 포함됩니다. 프런트엔드 웹 서버는 Go 언어(Golang)로 작성되어 백엔드에 직접 액세스할 수 있습니다. BBS 데이터 및 사용 일반 웹사이트 상호작용 모드는 검색을 위해 콘텐츠를 웹페이지로 렌더링합니다.
실제로 이러한 새로운 기능을 사용하는 것은 매우 간단합니다. HTTP GET 요청과 표준 쿼리 문자열 방법을 통해서만 이 정보를 얻으면 됩니다. 검색 기능을 제공하는 endpoint URL은 /bbs/{看板名稱}/search 입니다. 여기에서 검색 결과를 얻으려면 해당 쿼리를 사용하면 됩니다. 먼저 제목 키워드를 예로 들어보겠습니다.
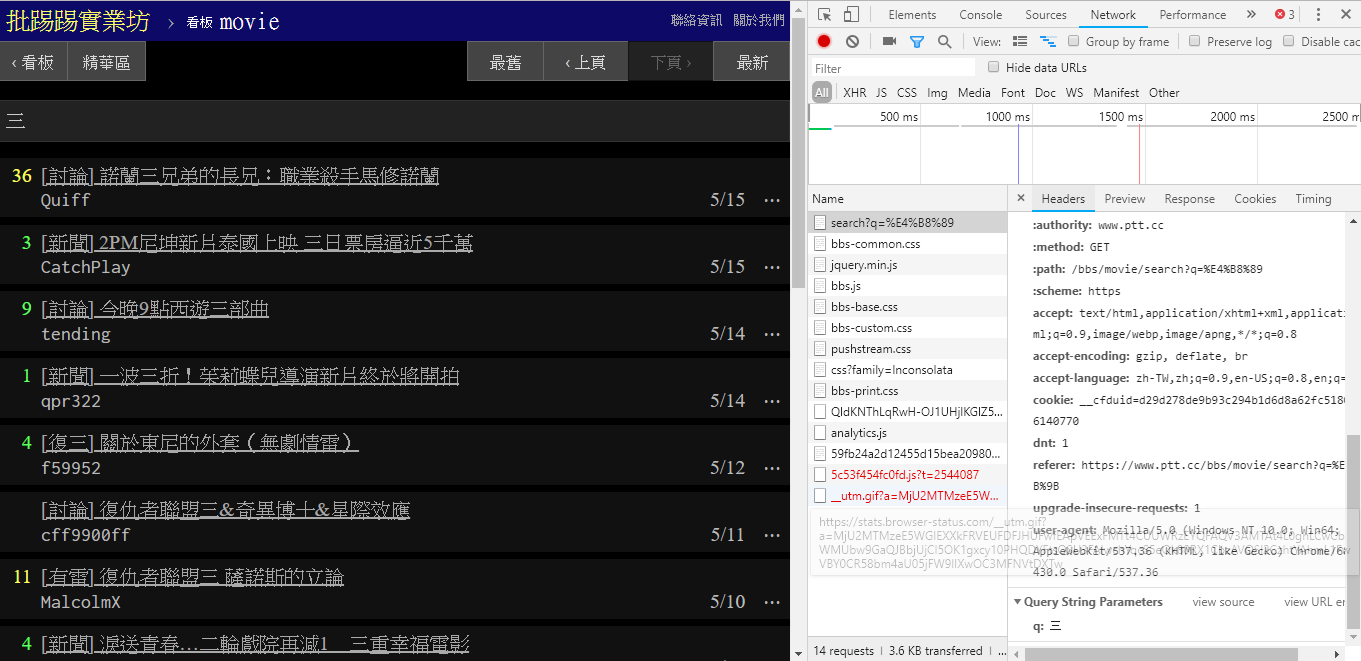
그림의 오른쪽 하단에서 볼 수 있듯이 검색 시 q=三인 GET 요청이 실제로 endpoint 로 전송되므로 전체 URL은 https://www.ptt.cc/bbs/movie/search?q=三와 같아야 합니다. https://www.ptt.cc/bbs/movie/search?q=三, 주소 표시줄에서 복사된 URL은 중국어가 HTML이기 때문에 https://www.ptt.cc/bbs/movie/search?q=%E4%B8%89 형식일 수 있습니다. 인코딩되었지만 동일한 의미를 나타냅니다. requests 에서 추가 쿼리 매개변수를 추가하려면 다음과 같이 param= 의 dict()를 통해 함수 매개변수에 문자열 형식을 수동으로 구성할 필요가 없습니다.
search_endpoint_url = 'https://www.ptt.cc/bbs/movie/search'
resp = requests . get ( search_endpoint_url , params = { 'q' : '三' })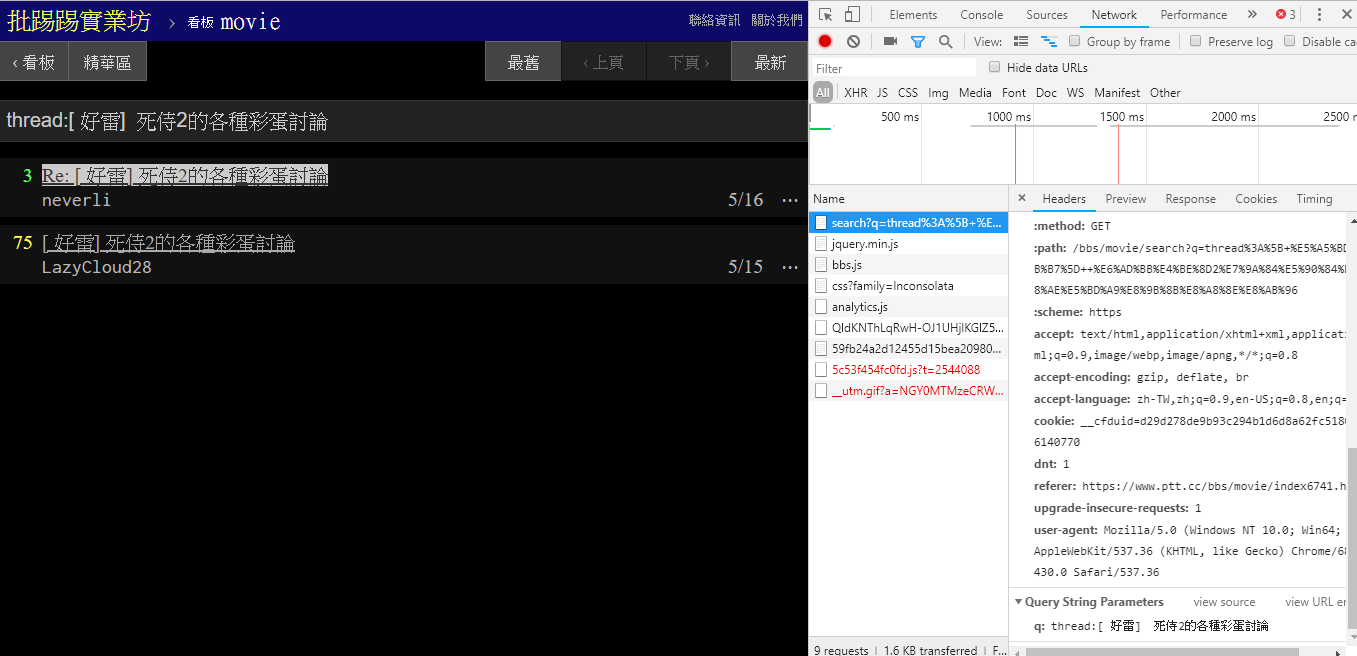
동일한 기사(스레드)를 검색할 때 실제로 제목 앞에 스레드 thread: 라는 문자열을 문자열로 묶어서 쿼리를 보낸다는 것을 오른쪽 하단의 정보를 보면 알 수 있습니다.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'thread:[ 好雷] 死侍2的各種彩蛋討論' })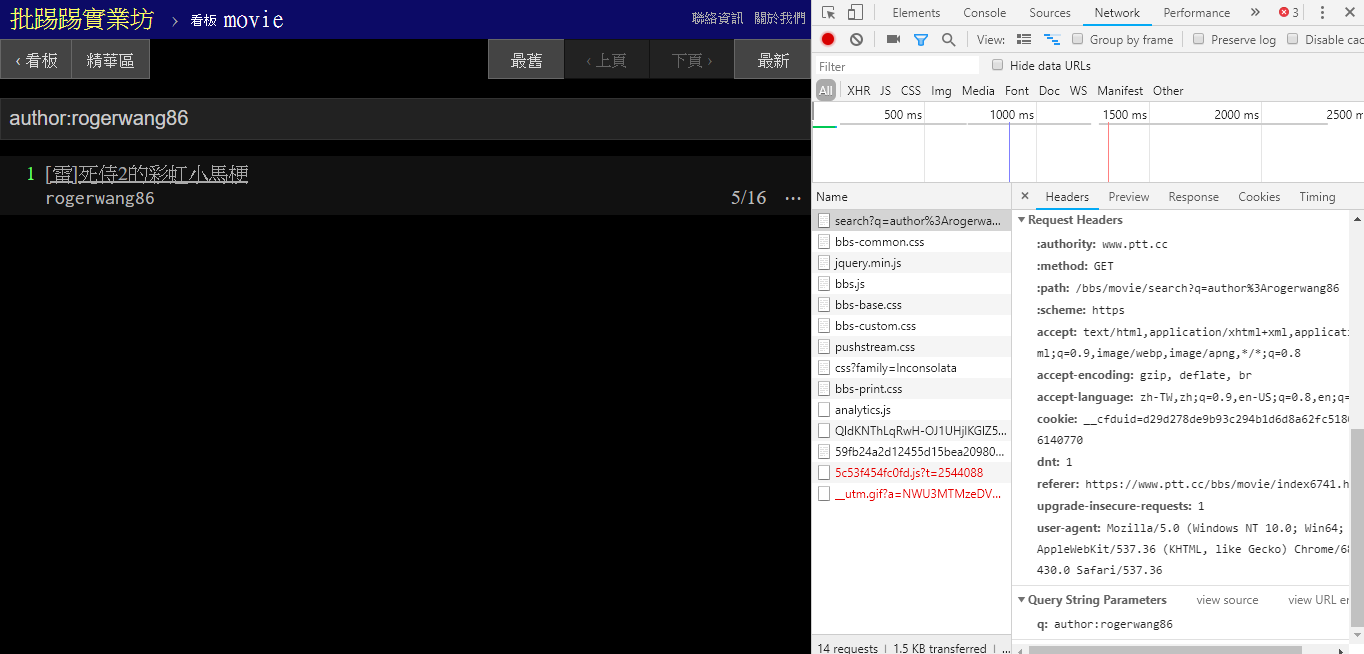
동일한 저자(저자)의 기사를 검색할 경우, 오른쪽 하단의 정보를 통해서도 author: 문자열을 저자명과 연결하여 쿼리를 보내는 것을 알 수 있습니다.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'author:rogerwang86' })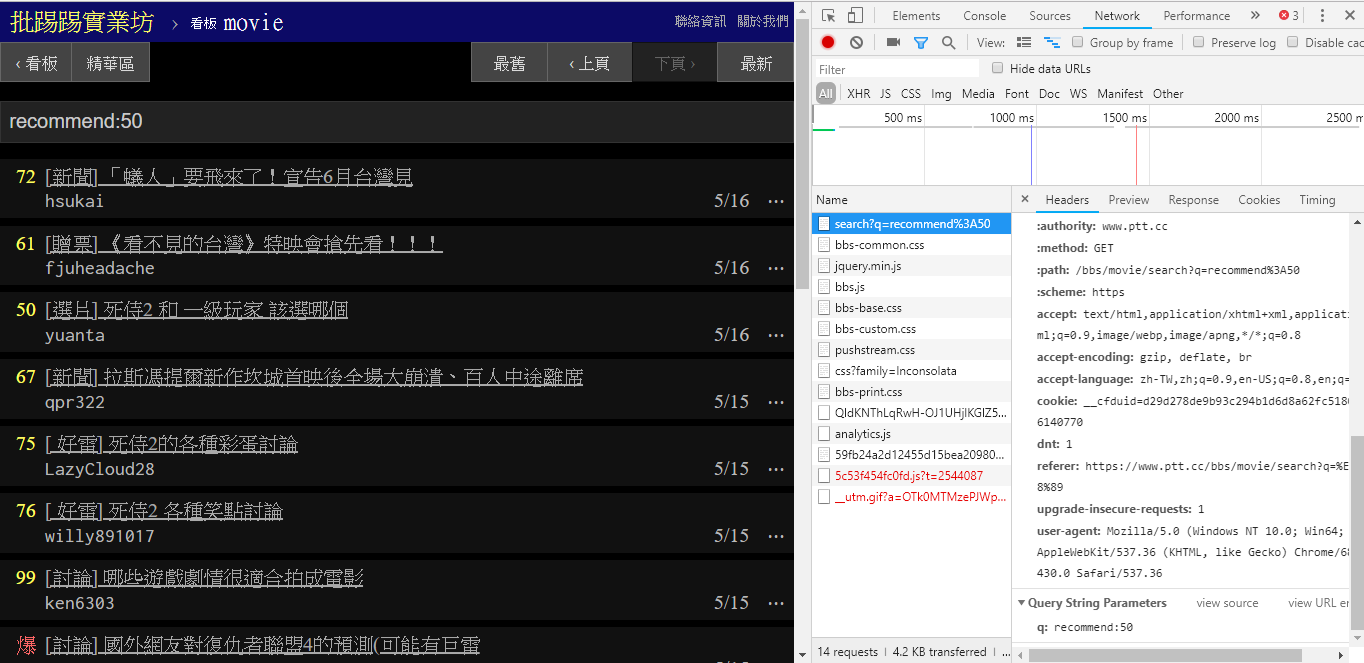
(추천)보다 트윗 수가 많은 기사를 검색할 경우 문자열 recommend: 검색하려는 최소 트윗 수를 문자열로 묶은 후 쿼리를 보냅니다. 또한, PTT 웹 서버 소스코드를 보면 트윗 개수를 ±100 이내로만 설정할 수 있음을 알 수 있다.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })이러한 매개변수의 PTT 웹 구문 분석 기능 소스 코드
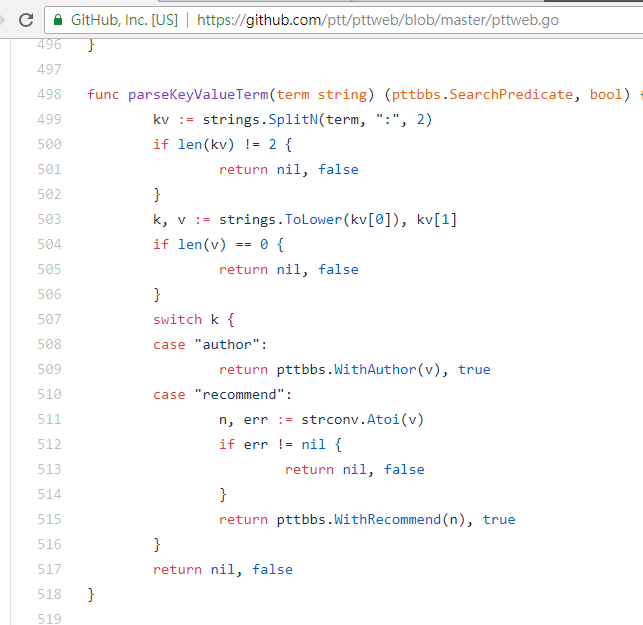
검색 결과의 최종 표현은 기본에서 언급한 일반 레이아웃과 동일하므로 이전 기능을 직접 Don't do it again! 할 수 있다는 점도 언급할 가치가 있습니다.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' })
post_entries = parse_article_entries ( resp . text ) # [沿用]
metadata = [ parse_article_meta ( entry ) for entry in post_entries ] # [沿用] 검색에는 또 다른 매개변수가 있습니다. page 수는 Google 검색과 마찬가지로 검색된 항목에 여러 페이지가 있을 수 있으므로 이 추가 매개변수를 사용하여 링크를 구문 분석하지 않고도 얻을 수 있는 결과 페이지를 제어할 수 있습니다. 페이지.
resp = requests . get ( search_endpoint_url , params = { 'q' : 'recommend:50' , 'page' : 2 }) 이전의 모든 기능을 ptt-parser에 통합하면 프로그래밍 방식으로 호출할 수 있는 API 형식의 명령줄 기능과爬蟲제공할 수 있습니다.
scrapy 사용하세요.
이 작품은 leVirve에서 제작했으며 Creative Commons Attribution 4.0 국제 라이선스에 따라 배포됩니다.


