fine grained sentiment app streamlit
1.0.0
이 저장소에는 이 Medium 시리즈에 자세히 설명된 세분화된 감정 분류의 결과를 설명하는 기존 대화형 애플리케이션과 동등한 Streamlit이 포함되어 있습니다.
다수의 분류기가 구현되었으며 그 결과는 LIME 설명자를 사용하여 설명됩니다. 분류자는 Stanford Sentiment Treebank(SST-5) 데이터 세트에 대해 교육을 받았습니다. 클래스 레이블은 [1, 2, 3, 4, 5] 중 하나입니다. 여기서 1 은 매우 부정적이며 5 매우 긍정적입니다.
Streamlit은 Python으로 대시보드를 구축하기 위한 가볍고 최소한의 프레임워크입니다. Streamlit의 주요 초점은 개발자에게 가능한 한 적은 코드 줄을 사용하여 UI 디자인의 프로토타입을 빠르게 제작할 수 있는 기능을 제공하는 것입니다. 백엔드 서버 및 해당 경로 정의, HTTP 요청 처리 등과 같이 일반적으로 웹 애플리케이션을 배포하는 데 필요한 모든 무거운 작업은 사용자로부터 추상화됩니다. 결과적으로 개발자의 경험에 관계없이 웹 앱을 신속하게 구현하는 것이 매우 쉬워집니다.
먼저 가상 환경을 설정하고 requirements.txt 에서 설치합니다.
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
추가 개발을 위해서는 기존 가상 환경을 활성화하기만 하면 됩니다.
source venv/bin/activate
가상 환경을 설정하고 활성화한 후 아래 명령어를 사용하여 앱을 실행합니다.
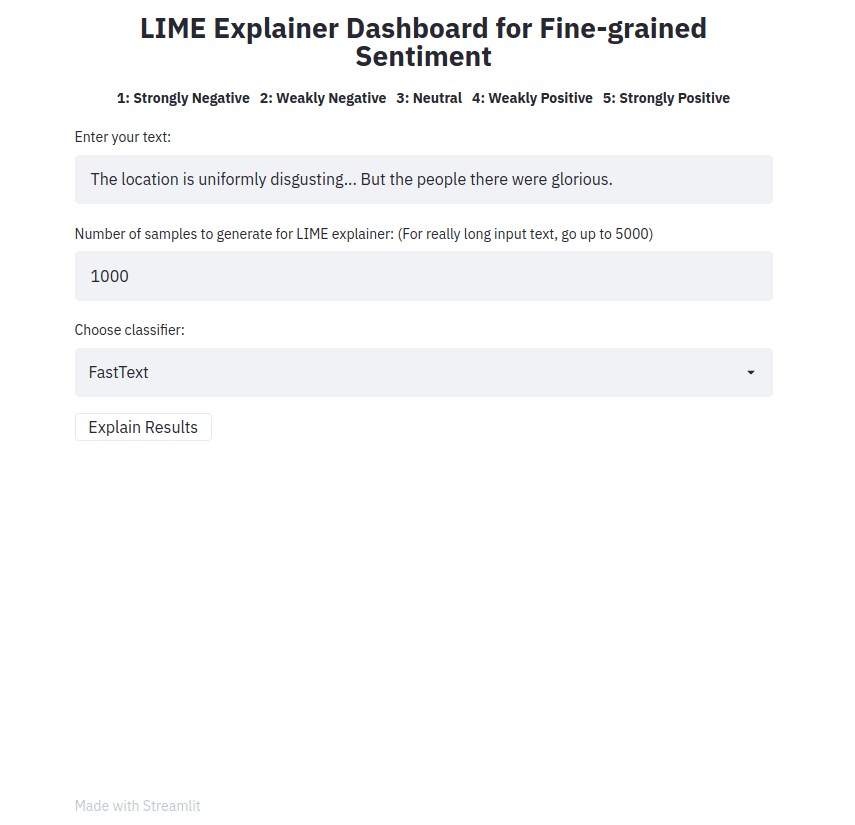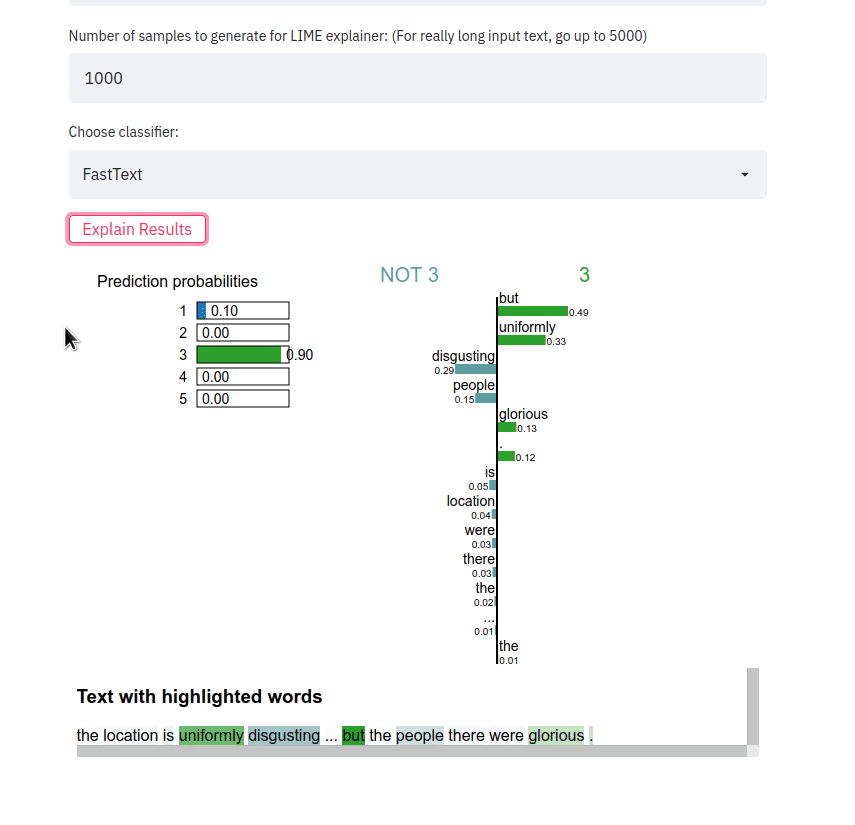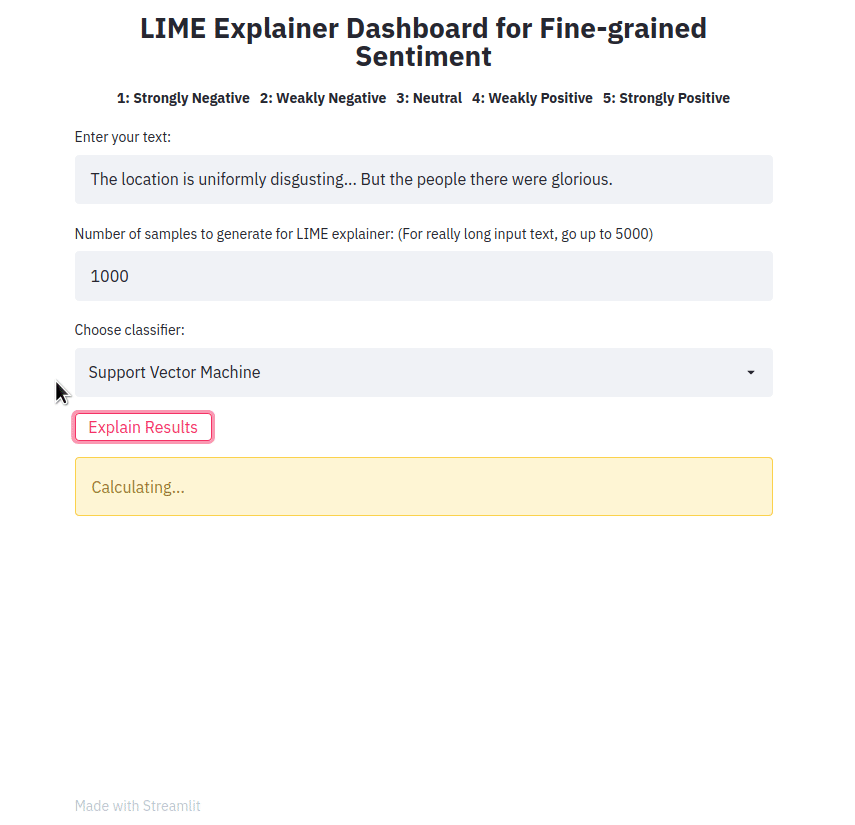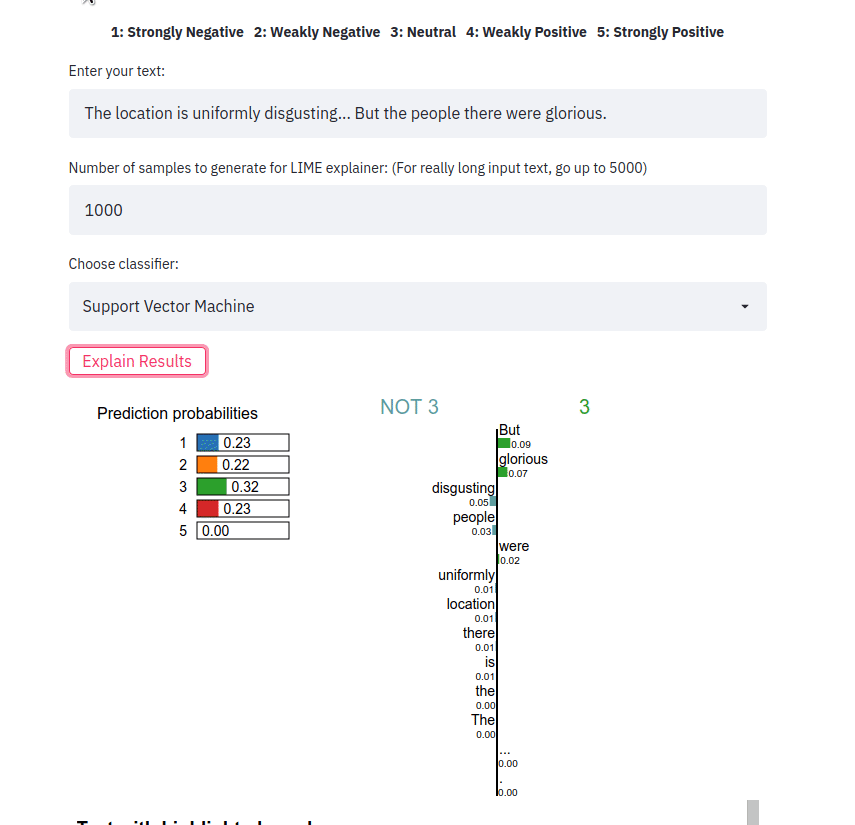
streamlit run app.py 문장을 입력하고 분류기 유형을 선택한 후 Explain results 버튼을 클릭하세요. 그런 다음 특정 클래스 레이블을 예측하는 분류기에 기여한 기능(예: 단어 또는 토큰)을 관찰할 수 있습니다.
프런트엔드 앱은 텍스트 샘플을 받아 다양한 방법에 대한 LIME 설명을 출력합니다. 앱은 https://sst5-explainer-streamlit.herokuapp.com/ 위치에서 Heroku를 사용하여 배포됩니다.
아래에 표시된 대로 자신만의 텍스트 예제를 가지고 플레이하고 설명된 세밀한 감정 결과를 확인하세요!
참고: PyTorch 기반 모델(Flair 및 인과 변환기)은 추론을 실행하는 데 비용이 많이 들기 때문에(GPU 필요) 이러한 방법은 배포되지 않습니다. 그러나 앱의 로컬 인스턴스에서는 실행할 수 있습니다.