nnl
gpt2-xl assets
nnl 은 저메모리 GPU 플랫폼의 대규모 모델을 위한 추론 엔진입니다.
큰 모델은 너무 커서 GPU 메모리에 맞지 않습니다. nnl PCIE 대역폭과 메모리 간의 균형을 통해 이 문제를 해결합니다.
일반적인 추론 파이프라인은 다음과 같습니다.
NNIL은 GPU 메모리 풀과 메모리 조각 모음을 통해 저사양 GPU 플랫폼에서 대규모 모델을 추론하는 것을 가능하게 합니다.
이것은 단지 몇 주 만에 작성한 취미 프로젝트이며, 현재는 CUDA 백엔드만 지원됩니다.
make lib nnl _cuda.a && make lib nnl _cuda_kernels.a이 명령은 lib/lib nnl _cuda.a 및 lib/lib nnl _cuda_kernels.a 라는 두 개의 정적 라이브러리를 빌드합니다. 첫 번째는 C++의 CUDA 백엔드가 있는 핵심 라이브러리이고, 두 번째는 CUDA 커널용입니다.
GPT2-XL(1.6B)의 데모 프로그램이 여기에 제공됩니다. 이 프로그램은 다음 명령으로 컴파일할 수 있습니다.
make gpt2_1558m릴리스에서 모든 가중치를 다운로드한 후 GTX 1050(2GB 메모리)과 같은 저사양 GPU 플랫폼에서 다음 명령을 실행할 수 있습니다.
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer " 그리고 출력은 다음과 같습니다: 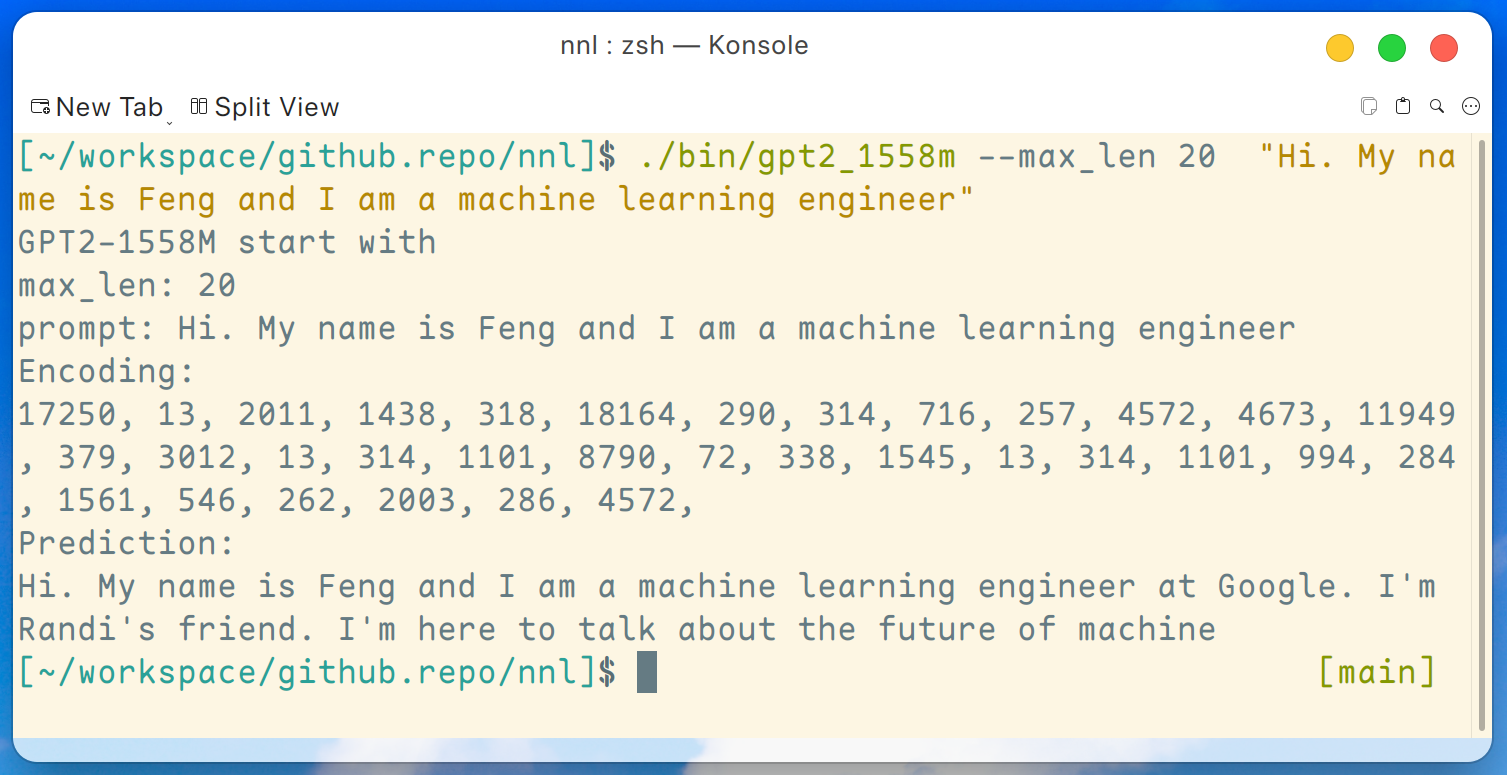
면책조항: 이것은 단지 gpt2-xl에 의해 생성된 예일 뿐입니다. 저는 Google에서 일하지 않으며 Randi를 모릅니다.
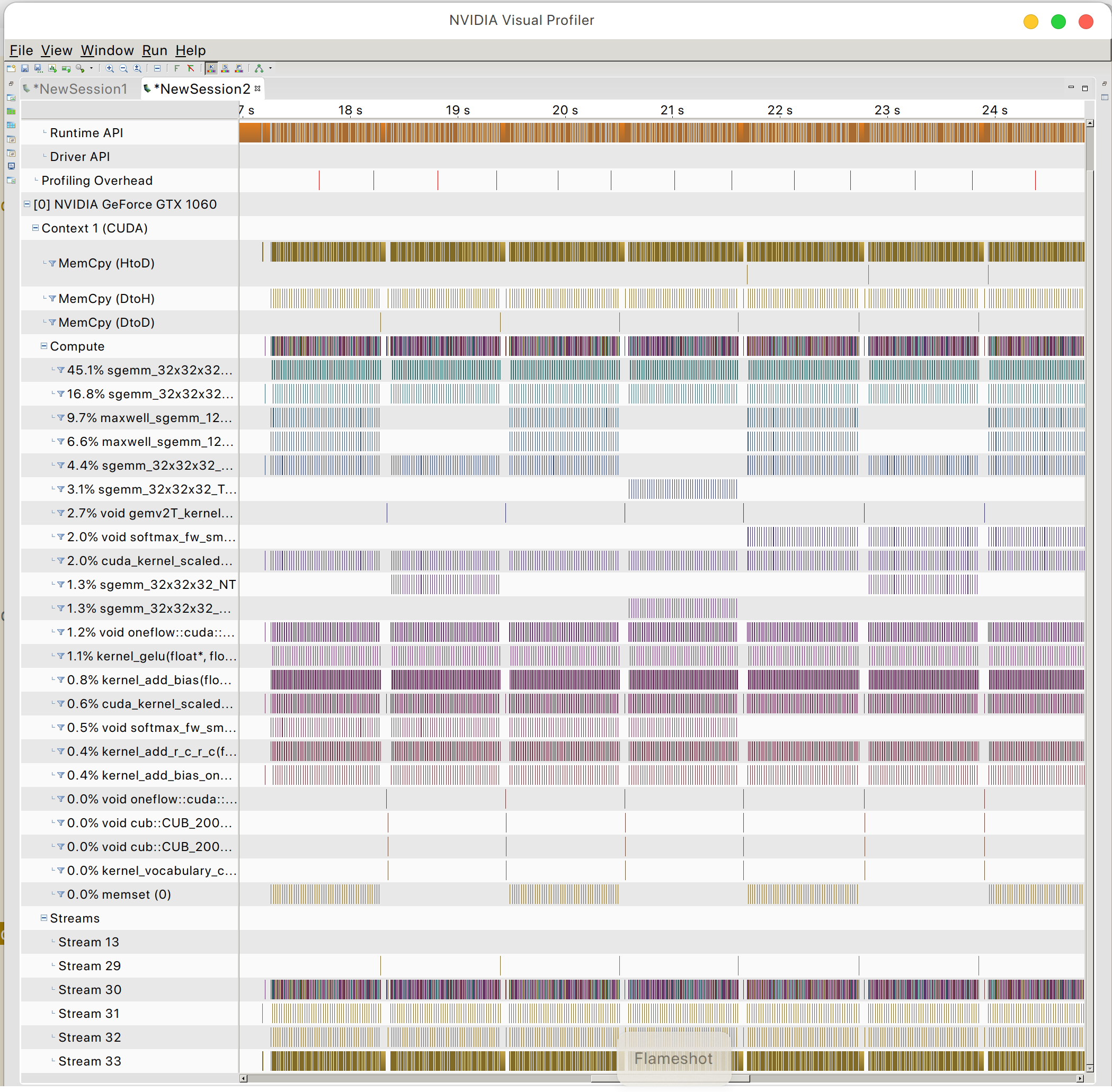
그리고 GPU 메모리 액세스 패턴을 찾을 수 있습니다
PeaceOSL