DiSQ Score
1.0.0
논문의 공식 구현: 담론적 소크라테스 질문: 언어 모델의 담화 관계 이해의 충실성 평가(2024) Yisong Miao, Hongfu Liu, Wenqiang Lei, Nancy F. Chen, Min-Yen Kan. ACL 2024.
종이 PDF: https://yisong.me/publications/acl24-DiSQ-CR.pdf
슬라이드: https://yisong.me/publications/acl24-DiSQ-Slides.pdf
포스터: https://yisong.me/publications/acl24-DiSQ-Poster.pdf
git clone [email protected]:YisongMiao/DiSQ-Score.git
conda activate
cd DiSQ-Score
cd scripts
pip install -r requirements.txt
모든 언어 모델의 DiSQ Score 알고 싶으십니까? 이 한 줄 명령을 사용해도 됩니다!

HuggingFace 모델 허브에 호스팅된 모든 언어 모델(LM)을 평가하기 위한 단순화된 명령을 제공합니다. 새로운 모델(특히 우리 논문에서 연구되지 않은 모델)에 이 기능을 사용하는 것이 좋습니다.
bash scripts/one_model.sh <modelurl>
< modelurl > 변수는 Huggingface 허브의 단축 경로를 지정합니다. 예를 들어 다음과 같습니다.
bash scripts/one_model.sh meta-llama/Meta-Llama-3-8B
bash 파일을 실행하기 전에 bash 파일을 편집하여 로컬 HuggingFace 캐시에 대한 경로를 지정하세요.
예를 들어 scripts/one_model.sh에서는 다음과 같습니다.
#!/bin/bash
# Please define your own path here
huggingface_path=YOUR_PATH
YOUR_PATH Huggingface Cache의 절대 디렉터리 위치로 변경할 수 있습니다(예: /disk1/yisong/hf-cache ).
최소 200GB 이상의 여유 공간을 권장합니다.
출력 텍스트 파일은 다음을 포함하는 data/results/verbalizations/Meta-Llama-3-8B.txt 에 저장됩니다.
=== The results for model: Meta-Llama-3-8B ===
Dataset: pdtb
DiSQ Score : 0.206
Targeted Score: 0.345
Counterfactual Score: 0.722
Consistency: 0.827
DiSQ Score for Comparison.Concession: 0.188
DiSQ Score for Comparison.Contrast: 0.22
DiSQ Score for Contingency.Reason: 0.164
DiSQ Score for Contingency.Result: 0.177
DiSQ Score for Expansion.Conjunction: 0.261
DiSQ Score for Expansion.Equivalence: 0.221
DiSQ Score for Expansion.Instantiation: 0.191
DiSQ Score for Expansion.Level-of-detail: 0.195
DiSQ Score for Expansion.Substitution: 0.151
DiSQ Score for Temporal.Asynchronous: 0.312
DiSQ Score for Temporal.Synchronous: 0.084
=== End of the results for model: Meta-Llama-3-8B ===
=== The results for model: Meta-Llama-3-8B ===
Dataset: ted
DiSQ Score : 0.233
Targeted Score: 0.605
Counterfactual Score: 0.489
Consistency: 0.787
DiSQ Score for Comparison.Concession: 0.237
DiSQ Score for Comparison.Contrast: 0.268
DiSQ Score for Contingency.Reason: 0.136
DiSQ Score for Contingency.Result: 0.211
DiSQ Score for Expansion.Conjunction: 0.268
DiSQ Score for Expansion.Equivalence: 0.205
DiSQ Score for Expansion.Instantiation: 0.194
DiSQ Score for Expansion.Level-of-detail: 0.222
DiSQ Score for Expansion.Substitution: 0.176
DiSQ Score for Temporal.Asynchronous: 0.156
DiSQ Score for Temporal.Synchronous: 0.164
=== End of the results for model: Meta-Llama-3-8B ===
데이터 세트는 data/datasets/dataset_pdtb.json 및 data/datasets/dataset_ted.json 에 있는 JSON 파일에 저장됩니다. 예를 들어 PDTB 데이터세트에서 하나의 인스턴스를 선택해 보겠습니다.
"2": {
"Didx": 2,
"arg1": "and special consultants are springing up to exploit the new tool",
"arg2": "Blair Entertainment, has just formed a subsidiary -- 900 Blair -- to apply the technology to television",
"DR": "Expansion.Instantiation.Arg2-as-instance",
"Conn": "for instance",
"events": [
[
"special consultants springing",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
],
[
"special consultants exploit the new tool",
"Blair Entertainment formed a subsidiary -- 900 Blair -- to apply the technology to television"
]
],
"context": "Other long-distance carriers have also begun marketing enhanced 900 service, and special consultants are springing up to exploit the new tool. Blair Entertainment, a New York firm that advises TV stations and sells ads for them, has just formed a subsidiary -- 900 Blair -- to apply the technology to television. "
},
이 사전 항목의 필드는 다음과 같습니다.
Didx : 담화 ID입니다.arg1 및 arg2 : 두 개의 인수입니다.DR : 담론관계.Conn : 담화 연결어입니다.events : 두드러진 신호로 예측된 이벤트 쌍을 저장하는 쌍 목록입니다.context : 담화 맥락입니다. cd DiSQ-Score
bash scripts/question_generation.sh
이 bash 파일은 question_generation.py 호출하여 다양한 구성에서 질문을 생성합니다.
question_generation.py 의 인수는 다음과 같습니다.
--dataset : 데이터 세트( pdtb 또는 ted 를 지정합니다.--modelname : 모델의 별칭이 생성되었습니다. 13b LLaMA2-13B, 13bchat 은 LLaMA2-13B-Chat, vicuna-13b 는 Vicuna-13B를 나타냅니다. 이러한 모델의 특정 URL은 disq_config.py 에서 찾을 수 있습니다.--version : v1 , v2 , v3 및 v4 옵션을 사용하여 사용할 프롬프트 템플릿의 버전을 지정합니다.--paraphrase : 표준 질문을 p1 및 p2 옵션을 사용하여 다른 말로 바꾸어 표현한 버전으로 바꿉니다. qa_utils.py 호출하는 표준 함수와 달리, 다르게 표현된 함수는 각각 qa_utils_p1.py 및 qa_utils_p2.py 호출합니다.--feature : 토론 질문에 사용할 언어 기능을 지정합니다. 언어적 특징에는 conn (담화 연결)과 context (담화 맥락)이 포함됩니다. 과거 QA 데이터에는 별도의 스크립트가 필요합니다. 출력은 예를 들어 data/questions/dataset_pdtb_prompt_v1.json 구성 dataset==pdtb 및 version==v1 아래에 저장됩니다.
이 접근 방식은 자동으로 수행되고 GitHub 저장소의 공간(최대 200MB까지 추가 가능)을 절약하는 데 도움이 되므로 사용자에게 직접 질문을 생성하도록 요청합니다. Bash 파일을 실행할 수 없는 경우, 질문 파일을 문의해 주세요.
cd DiSQ-Score
bash scripts/question_answering.sh
이 bash 파일은 question_answering.py 호출하여 특정 모델에 대해 DiSQ(Discursive Socratic Questioning)를 수행합니다. question_answering.py question_generation.py 의 모든 인수와 다음과 같은 새 인수를 가져옵니다.
--modelurl : 현재 구성 파일에 없는 새 모델의 URL을 지정합니다. 예를 들어 'meta-llama/Meta-Llama-3-8B'는 LLaMA3-8B 모델을 지정하고 modelname 인수를 덮어씁니다.--hf-path : 대규모 모델 매개변수를 저장할 경로를 지정합니다. 최소 200GB의 여유 디스크 공간이 권장됩니다.--device_number : 사용할 GPU의 ID를 지정합니다. 출력은 예를 들어 data/results/13bchat_dataset_pdtb_prompt_v1/ 에 저장됩니다. 각 질문에 대한 예측은 폴더 내의 피클 파일에 저장된 토큰 및 해당 확률 목록입니다.
주의 사항: 마법사 모델은 개발자에 의해 중단되었습니다. 우리는 사용자에게 이러한 모델을 사용하지 말 것을 권고합니다. https://huggingface.co/posts/WizardLM/329547800484476에서 토론 스레드를 확인하세요.
cd DiSQ-Score
bash scripts/eval.sh
이 bash 파일은 eval.py 호출하여 이전에 얻은 모델 예측을 평가합니다.
eval.py question_answering.py 와 동일한 매개변수 세트를 사용합니다.
지정된 데이터 세트가 PDTB인 경우 평가 결과는 disq_score_pdtb.csv 에 저장됩니다.
CSV 파일에는 다음과 같은 20개의 열이 있습니다.
taskcode : 테스트 중인 구성을 나타냅니다(예: dataset_pdtb_prompt_v1_13bchat ).modelname : 테스트 중인 언어 모델을 지정합니다.version : 프롬프트의 버전을 나타냅니다.paraphrase : 의역을 위한 매개변수입니다.feature : 사용된 기능을 지정합니다.Overall : 전체 DiSQ Score .Targeted : DiSQ Score 의 세 가지 구성 요소 중 하나인 타겟 점수입니다.Counterfactual : DiSQ Score 의 세 가지 구성 요소 중 하나인 반사실적 점수입니다.Consistency : 일관성 점수는 DiSQ Score 의 세 가지 구성 요소 중 하나입니다.Comparison.Concession : 이 특정 담화 관계에 대한 DiSQ Score .프롬프트 템플릿의 영향을 최소화하기 위해 버전 v1~v4 중에서 최상의 결과를 선택합니다.
이를 위해 eval.py 자동으로 최상의 결과를 추출합니다.
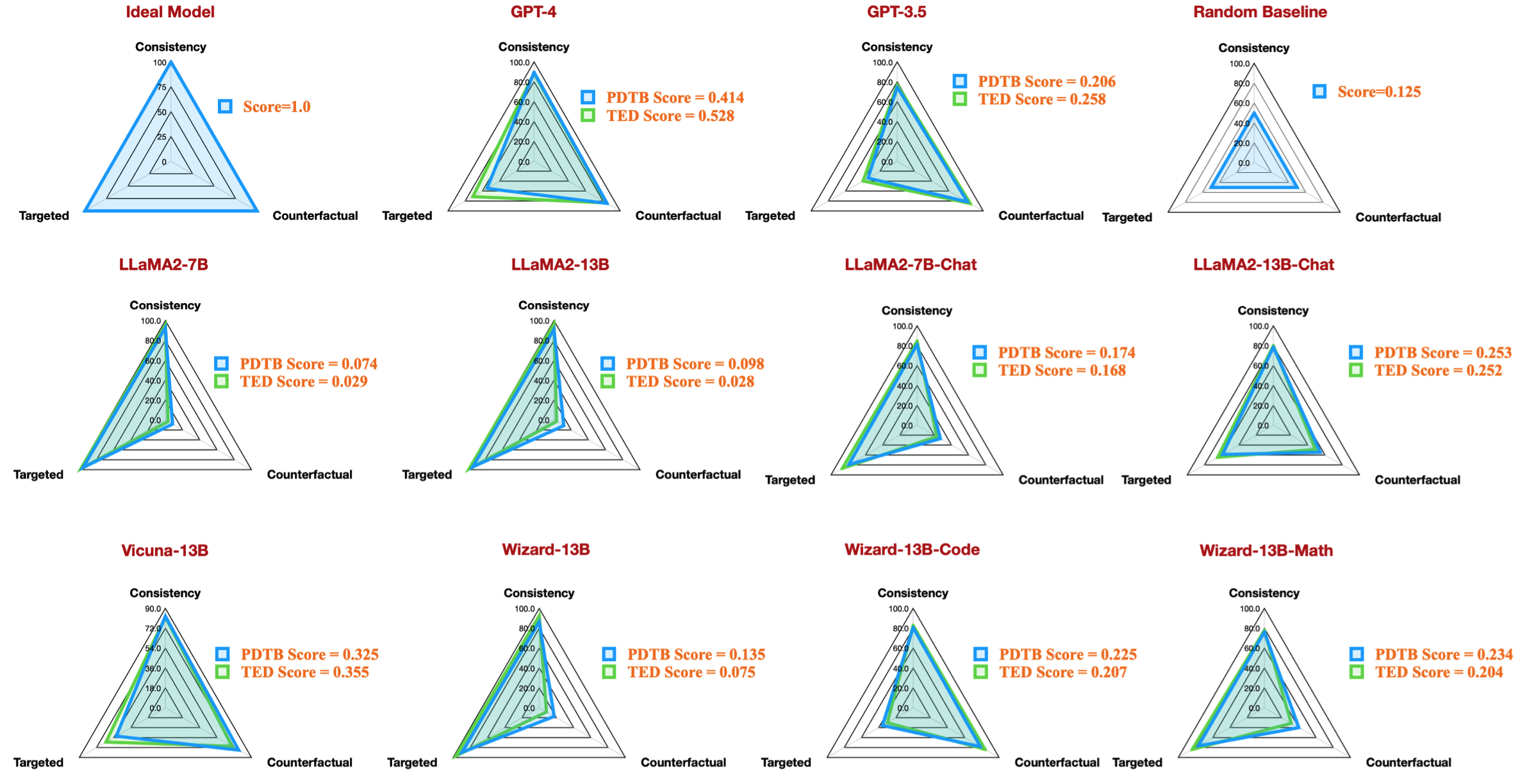
| 작업 코드 | 모델명 | 버전 | 의역 | 특징 | 전반적인 | 타겟 | 반사실적 | 일관성 | 비교.양보 | 비교.대비 | 우발사항.이유 | 우발상황.결과 | 확장.접합 | 확장.동등성 | 확장.인스턴스화 | 확장.세부정보 수준 | 확장.대체 | 임시.비동기 | 임시.동기 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 데이터세트_pdtb_prompt_v4_7b | 7b | v4 | 0.074 | 0.956 | 0.084 | 0.929 | 0.03 | 0.083 | 0.095 | 0.095 | 0.077 | 0.054 | 0.086 | 0.068 | 0.155 | 0.036 | 0.047 | ||
| 데이터 세트_pdtb_prompt_v1_7bchat | 7b채팅 | v1 | 0.174 | 0.794 | 0.271 | 0.811 | 0.231 | 0.435 | 0.132 | 0.173 | 0.214 | 0.105 | 0.121 | 0.15 | 0.199 | 0.107 | 0.04 | ||
| 데이터세트_pdtb_prompt_v2_13b | 13b | v2 | 0.097 | 0.945 | 0.112 | 0.912 | 0.037 | 0.099 | 0.081 | 0.094 | 0.126 | 0.101 | 0.113 | 0.107 | 0.077 | 0.083 | 0.093 | ||
| 데이터세트_pdtb_prompt_v1_13bchat | 13b채팅 | v1 | 0.253 | 0.592 | 0.545 | 0.785 | 0.195 | 0.485 | 0.129 | 0.173 | 0.289 | 0.155 | 0.326 | 0.373 | 0.285 | 0.194 | 0.028 | ||
| 데이터세트_pdtb_prompt_v2_vicuna-13b | 비쿠나-13b | v2 | 0.325 | 0.512 | 0.766 | 0.829 | 0.087 | 0.515 | 0.201 | 0.352 | 0.369 | 0.0 | 0.334 | 0.46 | 0.199 | 0.511 | 0.074 |
예를 들어, 이 표는 우리 논문의 레이더 수치를 재현하는 사용 가능한 오픈 소스 모델에 대한 PDTB 데이터 세트에 대한 최상의 결과를 보여줍니다.
또한 언어적 특징에 관한 토론 질문을 평가하기 위한 지침도 제공합니다.
--feature question_generation.py (1단계)에서 conn 및 context 로 지정하고 모든 실험을 다시 실행하세요.question_generation_history.py 실행하세요. 이 스크립트는 저장된 QA 결과에서 답변을 추출하고 새로운 질문을 생성합니다.대부분의 NLP 사용자의 경우 기존 가상(conda) 환경에서 코드를 실행할 수 있을 것입니다.
실험을 수행했을 때 패키지 버전은 다음과 같습니다.
torch==2.0.1
transformers==4.30.0
sentencepiece
protobuf
scikit-learn
pandas
그러나 최신 모델에는 업그레이드된 패키지 버전이 필요하다는 사실을 확인했습니다.
torch==2.4.0
transformers==4.43.3
sentencepiece
protobuf
scikit-learn
pandas
우리 작업이 흥미롭다고 생각하시면 데이터세트/코드베이스를 사용해 보시기 바랍니다.
우리의 데이터 세트/코드베이스를 사용한 적이 있다면 우리 연구를 친절하게 인용해 주세요.
@inproceedings{acl24discursive,
title={Discursive Socratic Questioning: Evaluating the Faithfulness of Language Models' Understanding of Discourse Relations},
author={Yisong Miao , Hongfu Liu, Wenqiang Lei, Nancy F. Chen, and Min-Yen Kan},
booktitle={Proceedings of the Annual Meeting fof the Association of Computational Linguistics},
month={August},
year={2024},
organization={ACL},
address = "Bangkok, Thailand",
}
질문이나 버그 보고서가 있는 경우 문제를 제기하거나 이메일을 통해 직접 문의해 주세요.
이메일 주소: ?@?
어디 ?️= yisong , ?= comp.nus.edu.sg
CC 바이 4.0


