Patron
1.0.0
이 저장소에는 ACL 2023 논문 Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach에 대한 코드가 포함되어 있습니다.
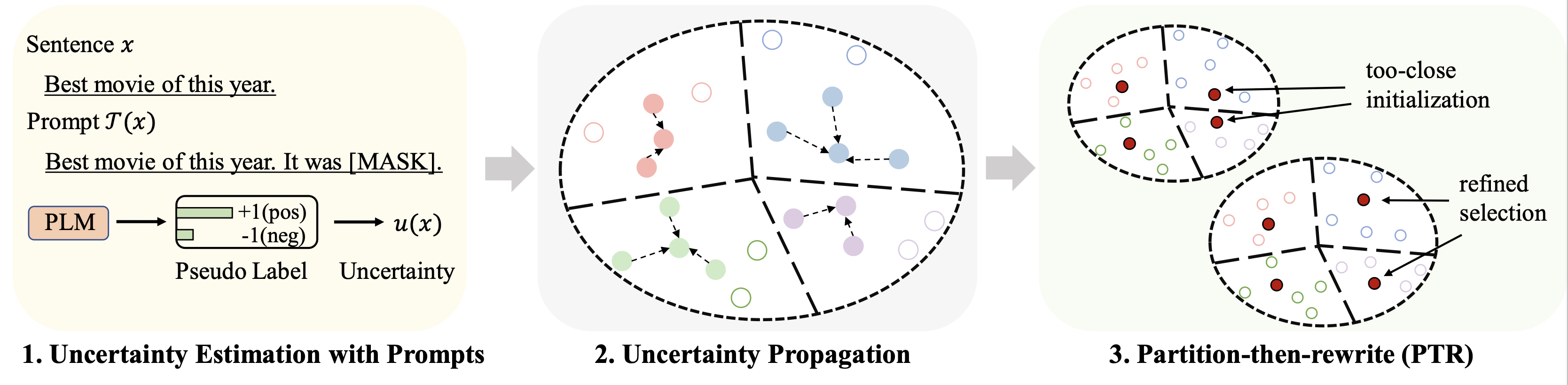
미세 조정을 위한 다양한 데이터세트(예산으로 128개의 라벨 사용)에 대한 결과는 다음과 같이 요약됩니다.
| 방법 | IMDB | 옐프 가득 | AG뉴스 | 야후! | DB피디아 | 트렉 | 평균 |
|---|---|---|---|---|---|---|---|
| Full Supervision (RoBERTa 기반) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| 무작위 샘플링 | 86.6 | 47.7 | 84.5 | 60.2 | 95.0 | 85.6 | 76.7 |
| 최고의 기준선(Chang et al. 2021) | 88.5 | 46.4 | 85.6 | 61.3 | 96.5 | 87.7 | 77.6 |
| Patron (우리) | 89.6 | 51.2 | 87.0 | 65.1 | 97.0 | 91.1 | 80.2 |
프롬프트 기반 학습을 위해 LM-BFF와 동일한 파이프라인을 사용합니다. 128개의 라벨이 포함된 결과는 다음과 같습니다.
| 방법 | IMDB | 옐프 가득 | AG뉴스 | 야후! | DB피디아 | 트렉 | 평균 |
|---|---|---|---|---|---|---|---|
| Full Supervision (RoBERTa 기반) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| 무작위 샘플링 | 87.7 | 51.3 | 84.9 | 64.7 | 96.0 | 85.0 | 78.2 |
| 최고의 기준선(Yuan 외, 2020) | 88.9 | 51.7 | 87.5 | 65.9 | 96.8 | 86.5 | 79.5 |
| Patron (우리) | 89.3 | 55.6 | 87.8 | 67.6 | 97.4 | 88.9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
주요 실험에는 다음 네 가지 데이터 세트를 사용합니다.
| 데이터세트 | 일 | 수업 수 | 라벨이 지정되지 않은 데이터/테스트 데이터 수 |
|---|---|---|---|
| IMDB | 감정 | 2 | 25,000/25,000 |
| 옐프 가득 | 감정 | 5 | 39,000/10,000 |
| AG 뉴스 | 뉴스 주제 | 4 | 119k/7.6k |
| 야후! 답변 | QA 주제 | 5 | 180k/30.1k |
| DB피디아 | 온톨로지 주제 | 14 | 280k/70k |
| 트렉 | 질문 주제 | 6 | 5천/0.5천 |
처리된 데이터는 이 링크에서 확인하실 수 있습니다. 이러한 데이터세트를 저장할 폴더는 다음 부분에서 설명합니다.
다음 명령을 실행하십시오.
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
우리는 데이터 세트에 대한 위 링크의 프롬프트를 통해 얻은 의사 예측을 제공합니다. 자세한 내용은 원본 논문을 참고하시기 바랍니다.
다음 명령을 실행합니다(AG News 데이터세트의 예).
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
몇 가지 중요한 하이퍼파라미터:
rho : 식에서 불확실성 전파에 사용되는 매개변수. 논문 6개beta : Eq.에서 거리의 정규화. 논문 8개gamma : Eq.의 정규화 항의 가중치입니다. 논문 10개 자세한 지침은 finetune 폴더를 참조하세요.
자세한 지침은 prompt_learning 폴더를 참조하세요.
프롬프트 기반 예측을 생성하기 위한 파이프라인으로 이 링크를 참조하세요. 프롬프트 자연어 처리 장치 및 템플릿을 사용자 정의해야 합니다.
문서 임베딩을 생성하려면 SimCSE를 사용하여 위 명령을 따를 수 있습니다.
선택한 데이터에 대한 인덱스를 생성하면 몇 번의 미세 조정 및 프롬프트 기반 학습 실험을 위해 Running Fine-tuning Experiments 및 Running Prompt-based Learning Experiments 의 파이프라인을 사용할 수 있습니다.
이 저장소가 귀하의 연구에 도움이 된다면 다음 논문을 인용해 주시기 바랍니다. 미리 감사드립니다!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
잘 정리된 코드를 제공한 SimCSE 및 OpenPrompt 저장소의 작성자에게 감사의 말씀을 전하고 싶습니다.


