JustJoking.ai
1.0.0
이 프로젝트에서 저는 짧은 농담을 생성하는 변환기 모델을 훈련했습니다. 그런 다음 추론 방법을 약간 수정하여 입력으로 초기 문자열이 주어지면 모델이 유머러스한 방식으로 이를 완성하려고 시도하는 것과 같은 동일한 모델을 사용할 수 있었습니다.
동일한 작업을 수행하는 두 개의 노트북이 있습니다.
농담 생성 결과 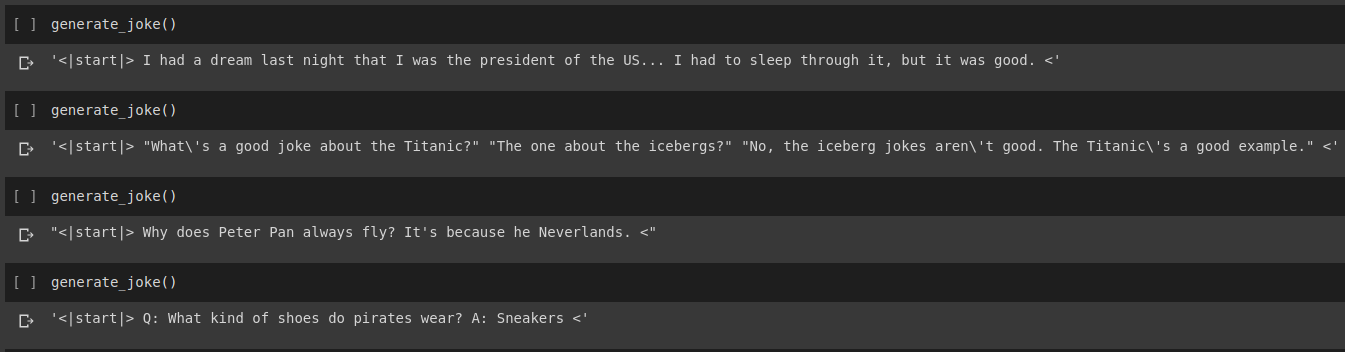
문장 완성 결과 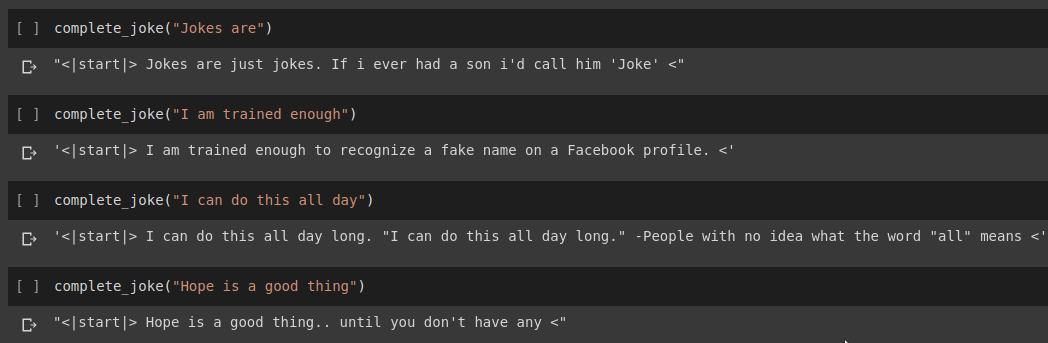
결과 
우리 작업에서는 Kaggle에서 제공되는 데이터 세트를 사용합니다. Reddit에서 스크랩한 200,000개 이상의 짧은 농담이 포함된 CSV입니다.
참고: 데이터 세트는 단순히 다양한 하위 레딧에서 스크랩되었기 때문에 데이터 세트에 있는 많은 농담은 상당히 인종차별적이고 성차별적입니다. 모든 AI는 훈련 데이터를 단일 지식 소스로 가정하므로 때때로 우리 모델이 비슷한 농담을 생성할 것으로 예상됩니다.
농담 문자열을 토큰화한 후에는 토큰화된 목록 끝에 start_token 과 end_token 추가합니다. 또한 농담 문자열의 길이가 다를 수 있으므로 모든 문자열에 지정된 max_length 에 패딩을 적용하여 배치에서 모든 텐서가 비슷한 모양을 갖도록 합니다.
이에 대한 코드는 Joke Generation.ipynb 노트북에서 찾을 수 있습니다. 여기서는 HuggingFace 라이브러리에서 GPT2Tokenizer 및 TFGPT2LMHead 모델을 가져옵니다. 코드는 Tensorflow2로 작성되었습니다. 노트북에는 적절한 위치에 코드에 대한 설명을 제공하는 주석이 있습니다. 또한 HuggingFace Docs는 모델의 입력 매개변수와 반환 값이 무엇인지에 대한 좋은 문서를 제공합니다. PyTorch 기반 구현에 대해서는 Tanul Singh의 Humour.ai 저장소를 참조하세요.
이에 대한 코드는 Joke_Completion_Pure_TF2_Implementation.ipynb 노트북에서 찾을 수 있습니다. 사물이 어떻게 작동하는지 더 깊이 이해하기 위해 프로젝트를 한 단계 더 발전시켜 외부 라이브러리 없이 변환기를 구축하려고 했습니다. Tensorflow에서 제공하는 Transformers에 대한 튜토리얼을 참조하고 튜토리얼에서 언급된 설명 중 일부를 추가 설명과 함께 내 노트에 넣어서 무슨 일이 일어나고 있는지 쉽게 이해할 수 있도록 했습니다.
먼저 데이터 세트에 대한 토크나이저를 구축하고 이를 사용하여 문자열을 토큰화했습니다. 그런 다음 Positional Encodings 및 MultiHeadAttention 위한 레이어를 구축했습니다. 또한 데이터에 적합한 마스크를 생성하기 위해 Lambda layer 사용했습니다.
그런 다음 디코더를 위한 단일 decoder layer 구축했습니다. 다음은 단일 디코더 레이어의 아키텍처입니다.
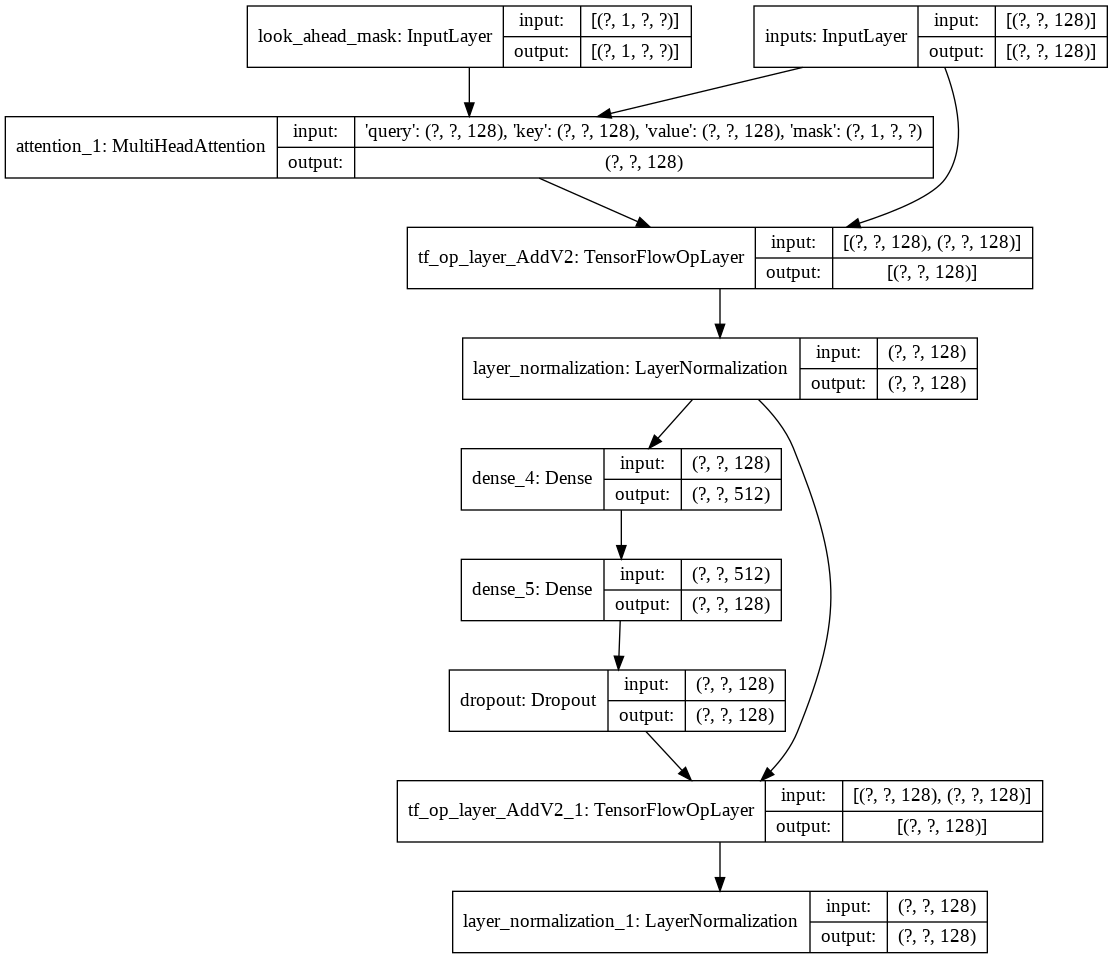
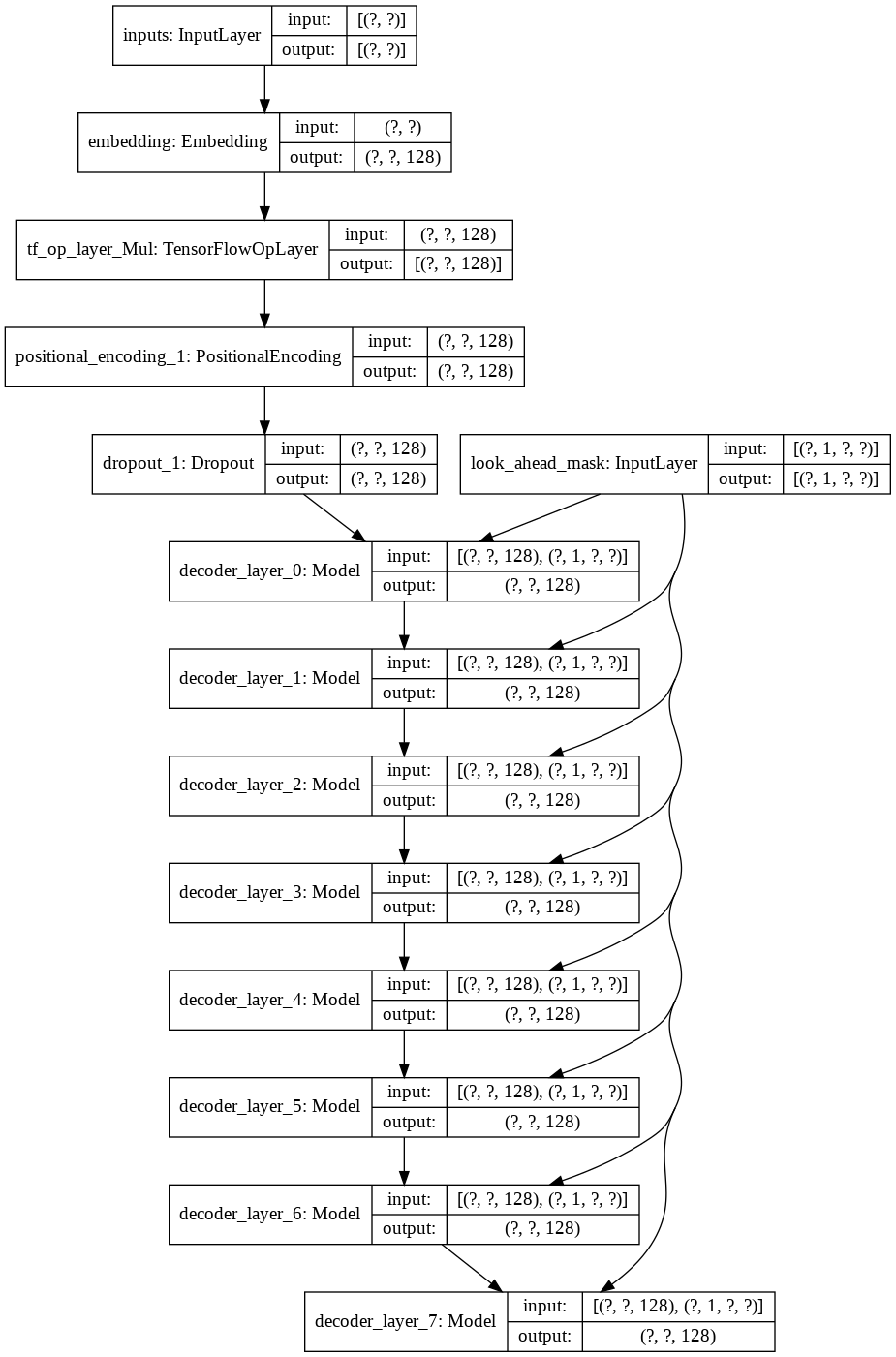
최종 transformer 모델의 경우 입력 토큰을 사용하고 이를 람다 계층을 통해 전달하여 마스크를 얻은 다음 마스크와 토큰을 모두 언어 디코더에 전달한 다음 출력이 밀도 계층을 통해 전달됩니다. 다음은 최종 모델의 아키텍처입니다.