LM SupCon
1.0.0
이 레포는 NAACL 2022에 승인된 Yiren Jian, Chongyang Gao 및 Soroush Vosoughi의 Prompt-based Few-shot Language Learners를 위한 대조 학습 논문의 구현을 다룹니다.
이 저장소가 귀하의 연구에 유용하다고 생각되면 논문 인용을 고려해 보십시오.
@inproceedings { jian-etal-2022-contrastive ,
title = " Contrastive Learning for Prompt-based Few-shot Language Learners " ,
author = " Jian, Yiren and
Gao, Chongyang and
Vosoughi, Soroush " ,
booktitle = " Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies " ,
month = jul,
year = " 2022 " ,
address = " Seattle, United States " ,
publisher = " Association for Computational Linguistics " ,
url = " https://aclanthology.org/2022.naacl-main.408 " ,
pages = " 5577--5587 " ,
abstract = "The impressive performance of GPT-3 using natural language prompts and in-context learning has inspired work on better fine-tuning of moderately-sized models under this paradigm. Following this line of work, we present a contrastive learning framework that clusters inputs from the same class for better generality of models trained with only limited examples. Specifically, we propose a supervised contrastive framework that clusters inputs from the same class under different augmented {``}views{''} and repel the ones from different classes. We create different {``}views{''} of an example by appending it with different language prompts and contextual demonstrations. Combining a contrastive loss with the standard masked language modeling (MLM) loss in prompt-based few-shot learners, the experimental results show that our method can improve over the state-of-the-art methods in a diverse set of 15 language tasks. Our framework makes minimal assumptions on the task or the base model, and can be applied to many recent methods with little modification.",
} 우리 코드는 LM-BFF 및 SupCon( /src/losses.py )에서 많이 차용되었습니다.
이 저장소는 Ubuntu 18.04.5 LTS, Python 3.7, PyTorch 1.6.0 및 CUDA 10.1에서 테스트되었습니다. RoBERTa 기반 실험에는 48GB GPU가 필요하고 RoBERTa 대형 실험에는 4x 48GB GPU가 필요합니다. Nvidia RTX-A6000 및 RTX-8000에서 실험을 실행하지만 40GB의 Nvidia A100도 작동합니다.
LM-BFF의 사전 처리된 데이터 세트(SST-2, SST-5, MR, CR, MPQA, Subj, TREC, CoLA, MNLI, SNLI, QNLI, RTE, MRPC, QQP)를 사용합니다. LM-BFF는 데이터세트를 다운로드하고 준비하는 데 유용한 스크립트를 제공합니다. 아래 명령을 실행하기만 하면 됩니다.
cd data
bash download_dataset.sh그런 다음 다음 명령을 사용하여 연구에 사용한 16샷 데이터세트를 생성합니다.
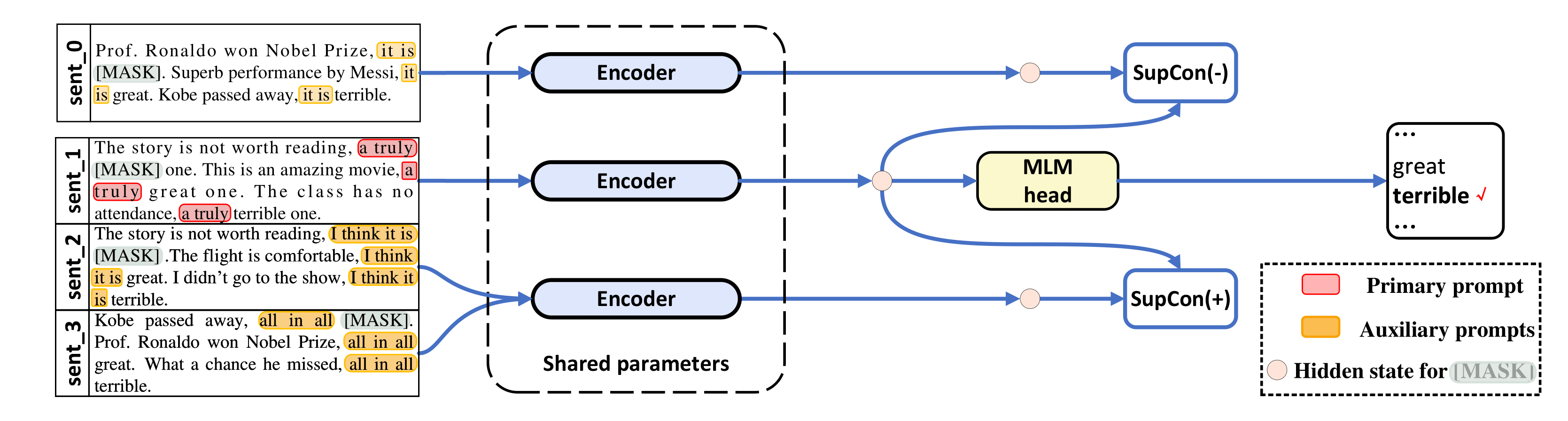
python tools/generate_k_shot_data.py 작업에 사용되는 기본 프롬프트(템플릿)는 run_experiments.sh 에 미리 정의되어 있습니다. 대조 학습을 위한 입력의 다중 보기를 생성할 때 사용되는 보조 템플릿은 /auto_template/$TASK 에서 찾을 수 있습니다.
시스템에 하나의 GPU가 있다고 가정하고 SST-5에서 미세 조정을 실행하는 예를 보여줍니다(입력의 "증강 보기"에 대한 무작위 템플릿 및 무작위 데모).
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 40 # ### batch size
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-base
bash run_experiment.sh
done
done
done
done
rm -rf result/ 우리의 프레임워크는 데모가 없는 프롬프트 기반 방법(예: TYPE=prompt 에도 적용됩니다(이 경우 "증강 보기" 생성을 위해 무작위로 템플릿을 샘플링합니다). 결과는 log 에 저장됩니다.
RoBERTa-large를 기본 모델로 사용하려면 각각 48GB 메모리를 갖춘 4개의 GPU가 필요합니다. 먼저 src/models.py 에서 라인 20을 def __init__(self, hidden_size=1024) 로 편집해야 합니다.
for seed in 13 21 42 87 100 # ### random seeds for different train-test splits
do
for bs in 10 # ### batch size for each GPU, total batch size is then 40
do
for lr in 1e-5 # ### learning rate for MLM loss
do
for supcon_lr in 1e-5 # ### learning rate for SupCon loss
do
TAG=exp
TYPE=prompt-demo
TASK=sst-5
BS= $bs
LR= $lr
SupCon_LR= $supcon_lr
SEED= $seed
MODEL=roberta-large
bash run_experiment.sh
done
done
done
done
rm -rf result/ python tools/gather_result.py --condition "{'tag': 'exp', 'task_name': 'sst-5', 'few_shot_type': 'prompt-demo'}"
log 에서 결과를 수집하고 5개의 열차-테스트 분할에 대한 평균 및 표준 편차를 계산합니다.
질문이 있으시면 저자에게 문의하세요.
예비 구현을 도와주신 LM-BFF 및 SupCon에게 감사드립니다.


