aug pe
1.0.0
? 종이 • 데이터(Yelp/OpenReview/PubMed) • 프로젝트 페이지
이 리포지토리는 Aug-PE(Augmented Private Evolution) 알고리즘을 구현하여 LLM(대형 언어 모델)에 대한 추론 API 액세스를 활용하여 모델 교육 없이 DP(차등 비공개) 합성 텍스트를 생성합니다. DP-SGD 미세 조정과 Aug-PE를 비교합니다.

아래에
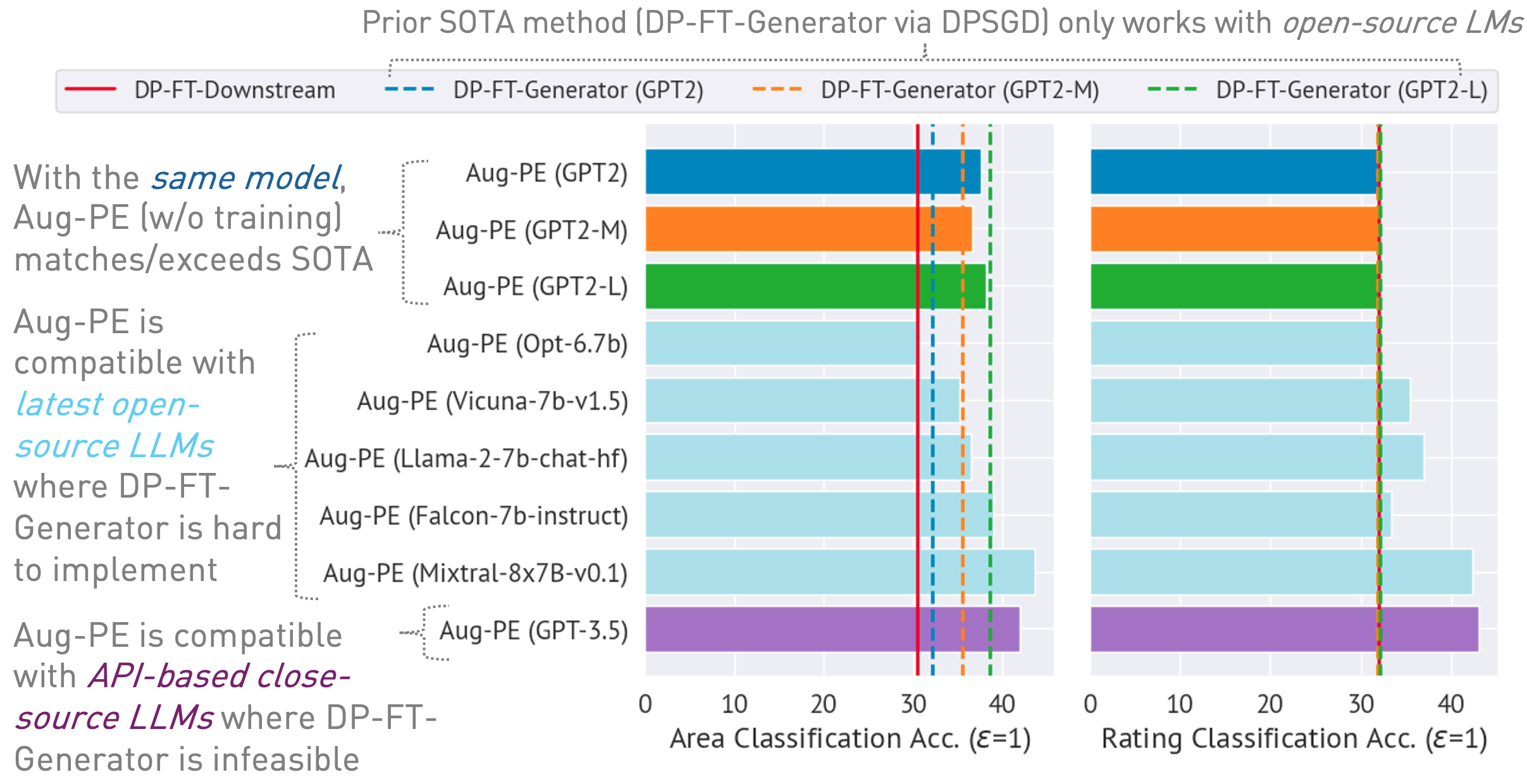
03/13/2024 : 알고리즘과 그 결과를 간략하게 설명하는 프로젝트 페이지를 사용할 수 있습니다.03/11/2024 : 코드 및 ArXiv 문서를 사용할 수 있습니다. conda env create -f environment.yml
conda activate augpe
데이터세트는 data/{dataset} 에 있으며, 여기서 dataset 는 yelp , openreview 및 pubmed 입니다.
이 링크에서 Yelp train.csv (1.21G) 및 PubMed train.csv (117MB)를 다운로드하거나 다음을 실행하십시오.
bash scripts/download_data.sh # download yelp train.csv and pubmed train.csv데이터 세트 설명:
개인 데이터에 대한 사전 계산 임베딩(Aug-PE 알고리즘의 1행):
bash scripts/embeddings.sh --openreview # Compute private embeddings
bash scripts/embeddings.sh --pubmed
bash scripts/embeddings.sh --yelp 참고: OpenReview 및 PubMed의 임베딩 계산은 상대적으로 빠릅니다. 그러나 Yelp의 대규모 데이터 세트 크기(190만 훈련 샘플)로 인해 프로세스는 약 40분 정도 걸릴 수 있습니다.
개인 정보 보호 예산을 고려하여 notebook/dp_budget.ipynb 에서 데이터세트의 DP 노이즈 수준을 계산합니다.
Wandb를 사용한 시각화를 위해 dpsda/arg_utils.py 의 키와 프로젝트 이름으로 --wandb_key 및 --project 구성합니다.
Hugging Face의 오픈 소스 LLM을 활용하여 합성 데이터를 생성합니다.
export CUDA_VISIBLE_DEVICES=0
bash scripts/hf/{dataset}/generate.sh # Replace `{dataset}` with yelp, openreview, or pubmed일부 주요 하이퍼파라미터:
noise : DP 소음.epoch : DP 설정에 10개의 epoch를 사용합니다. DP가 아닌 설정의 경우 Yelp에는 20개의 에포크를 사용하고 다른 데이터세트에는 10개의 에포크를 사용합니다.model_type : ["gpt2", "gpt2-medium", "gpt2-large", "meta-llama/Llama-2-7b-chat-hf", "tiiuae/falcon-7b-instruct"와 같은 포옹 얼굴 모델 , "facebook/opt-6.7b", "lmsys/vicuna-7b-v1.5", "mistralai/Mixtral-8x7B-Instruct-v0.1"].num_seed_samples : 합성 샘플의 수.lookahead_degree : 합성 샘플 임베딩 추정을 위한 변형 수(Aug-PE 알고리즘의 5번째 줄). 기본값은 0(자체 포함)입니다.L : 후보 합성 샘플을 생성하기 위한 변형 수와 관련됨(Aug-PE 알고리즘의 18행)feat_ext : 포옹 얼굴 문장 변환기에 모델을 삽입합니다.select_syn_mode : 히스토그램 투표 또는 확률에 따라 합성 샘플을 선택합니다. 기본값은 rank 입니다(Aug-PE 알고리즘의 19행).temperature : LLM 생성 온도입니다.DP 합성 텍스트로 다운스트림 모델을 미세 조정하고 실제 테스트 데이터에서 모델의 정확도를 평가합니다.
bash scripts/hf/{dataset}/downstream.sh # Finetune downstream model and evaluate performance 임베딩 분포 거리를 측정합니다.
bash scripts/hf/{dataset}/metric.sh # Calculate distribution distance모든 생성 및 평가 단계를 결합하는 간소화된 프로세스의 경우:
bash scripts/hf/template/{dataset}.sh # Complete workflow for each dataset 우리는 Azure OpenAI API를 통해 비공개 소스 모델을 사용합니다. apis/azure_api.py 에서 키와 엔드포인트를 설정하세요.
MODEL_CONFIG = {
'gpt-3.5-turbo' :{ "openai_api_key" : "YOUR_AZURE_OPENAI_API_KEY" ,
"openai_api_base" : "YOUR_AZURE_OPENAI_ENDPOINT" ,
"engine" : 'YOUR_DEPLOYMENT_NAME' ,
},
} 여기서 engine Azure에서 gpt-35-turbo 일 수 있습니다.
다음 스크립트를 실행하여 합성 데이터를 생성하고, 다운스트림 작업에서 이를 평가하고, 실제 데이터와 합성 데이터 간의 임베딩 분포 거리를 계산합니다.
bash scripts/gpt-3.5-turbo/{dataset}.sh생성된 텍스트의 길이를 제어하기 위해 GPT-3.5의 텍스트 길이 관련 프롬프트를 사용합니다. 여기에는 몇 가지 추가 하이퍼파라미터를 소개합니다.
dynamic_len 동적 길이 메커니즘을 활성화하는 데 사용됩니다.word_var_scale : Target_word를 결정하는 데 사용되는 가우스 노이즈 분산입니다.max_token_word_scale : 단어당 최대 토큰 수입니다. Target_word(프롬프트에 지정됨) 및 max_token_word_scale을 기반으로 LLM 생성을 위한 max_token을 설정했습니다. 실제 데이터와 합성 데이터 사이의 텍스트 길이 분포 차이를 계산하려면 노트북을 사용하세요: notebook/text_lens_distribution.ipynb
우리의 작업이 도움이 되었다고 생각하시면 다음과 같이 인용해 주시기 바랍니다.
@inproceedings {
xie2024differentially,
title = { Differentially Private Synthetic Data via Foundation Model {API}s 2: Text } ,
author = { Chulin Xie and Zinan Lin and Arturs Backurs and Sivakanth Gopi and Da Yu and Huseyin A Inan and Harsha Nori and Haotian Jiang and Huishuai Zhang and Yin Tat Lee and Bo Li and Sergey Yekhanin } ,
booktitle = { Forty-first International Conference on Machine Learning } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=LWD7upg1ob }
}코드나 논문과 관련된 질문이 있는 경우 언제든지 Chulin([email protected])으로 이메일을 보내거나 이슈를 열어주세요.


