reflexion
1.0.0
이 저장소에는 reflexion 위한 코드, 데모 및 로그 파일이 포함되어 있습니다. Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao의 언어 강화 학습을 통한 언어 에이전트.
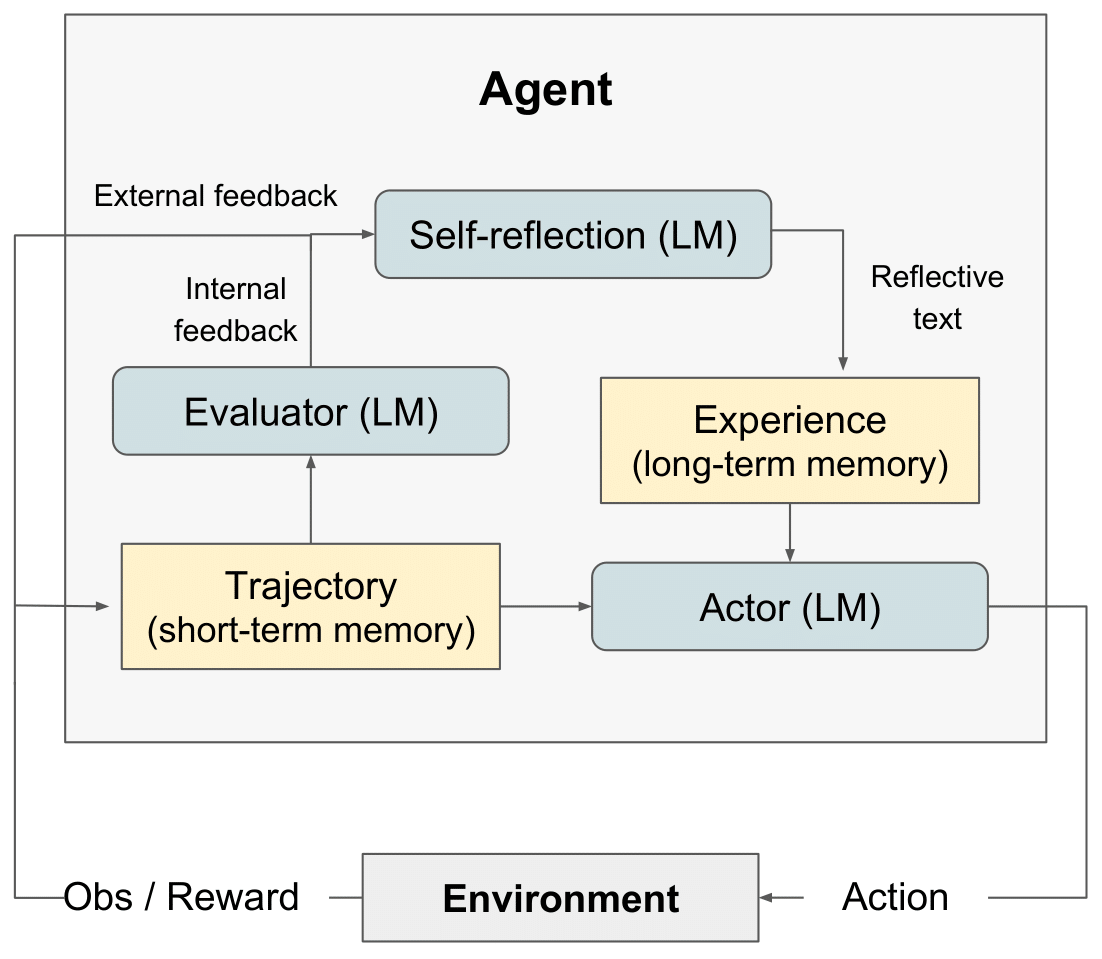 반사 RL 다이어그램" style="max-width: 100%;">
반사 RL 다이어그램" style="max-width: 100%;">
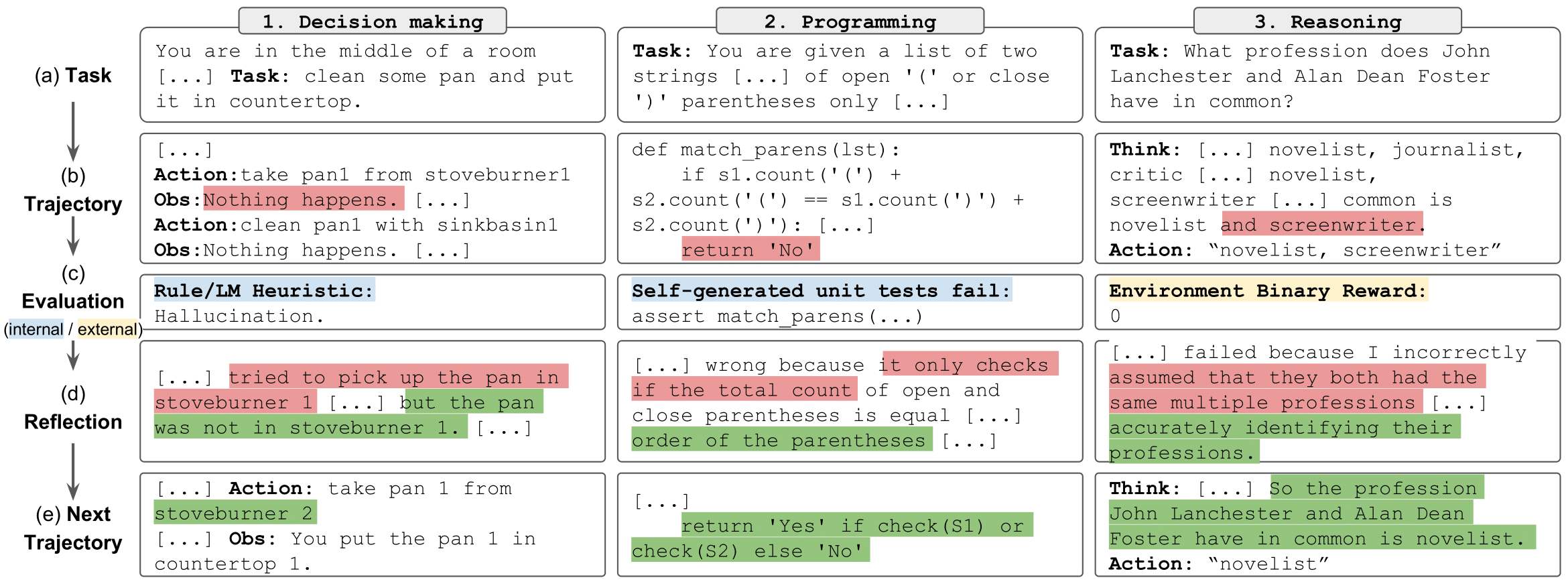 반사 작업" style="max-width: 100%;">
반사 작업" style="max-width: 100%;">
LeetcodeHardGym을 여기에 출시했습니다.
우리는 추론 실험 결과를 쉽게 실행하고, 탐색하고, 상호 작용할 수 있는 일련의 노트북을 제공했습니다. 각 실험은 HotPotQA 선택 항목 데이터 세트에서 무작위로 추출된 100개의 질문 샘플로 구성됩니다. 샘플의 각 질문은 특정 유형 및 reflexion 전략을 가진 에이전트에 의해 시도됩니다.
시작하려면:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY 환경 변수를 OpenAI API 키로 설정합니다. export OPENAI_API_KEY= < your key > 에이전트 유형은 실행하기로 선택한 노트북에 따라 결정됩니다. 사용 가능한 에이전트 유형은 다음과 같습니다.
ReAct - 반응 에이전트
CoT_context - 질문에 대한 지원 컨텍스트가 제공된 CoT 에이전트
CoT_no_context - 질문에 대한 지원 컨텍스트가 제공되지 않은 CoT 에이전트
각 에이전트 유형에 대한 노트북은 ./hotpot_runs/notebooks 디렉터리에 있습니다.
각 노트북을 사용하면 상담원이 사용할 reflexion 전략을 지정할 수 있습니다. Enum 에 정의된 사용 가능한 reflexion 전략은 다음과 같습니다.
reflexion Strategy.NONE - 에이전트에는 마지막 시도에 대한 정보가 제공되지 않습니다.
reflexion Strategy.LAST_ATTEMPT - 에이전트에는 질문에 대한 마지막 시도의 추론 추적이 컨텍스트로 제공됩니다.
reflexion Strategy. reflexion - 에이전트에는 마지막 시도에 대한 자체 반성이 컨텍스트로 제공됩니다.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - 에이전트에는 마지막 시도에 대한 추론 추적과 자체 성찰이 모두 컨텍스트로 제공됩니다.
이 저장소를 복제하고 AlfWorld 디렉터리로 이동하세요.
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs ./run_ reflexion .sh 에서 실행 매개변수를 지정합니다. num_trials : 반복 학습 단계 수 num_envs : 시도당 작업-환경 쌍 수 run_name : 이 실행의 이름 use_memory : 지속 메모리를 사용하여 자체 반영 저장(기준 실행을 실행하려면 끄기) is_resume : 재개하려면 로깅 디렉터리 사용 이전 실행 resume_dir : 이전 실행을 재개할 로깅 디렉토리 start_trial_num : 재개 실행인 경우 시작할 시도 번호
평가판 실행
./run_ reflexion .sh 로그는 ./root/<run_name> 으로 전송됩니다.
이러한 실험의 특성으로 인해 GPT-4에는 액세스가 제한되고 상당한 API 요금이 부과되므로 개별 개발자가 결과를 다시 실행하는 것이 불가능할 수 있습니다. 논문의 모든 실행과 추가 결과는 의사 결정을 위한 ./alfworld_runs/root , 추론을 위한 ./hotpotqa_runs/root , 프로그래밍을 위한 ./programming_runs/root 에 기록됩니다.
여기에서 원본 코드의 코드를 확인하세요.
여기에서 블로그 게시물을 읽어보세요.
여기에서 흥미로운 유형 예측 구현을 확인하세요: OpenTau
모든 질문은 [email protected]으로 문의하세요.
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

