ChatGPT, GenerativeAI 및 LLM 타임라인
이 저장소는 ChatGPT 발표 전후에 발생한 주요 이벤트(제품, 서비스, 논문, GitHub, 블로그 게시물 및 뉴스)의 타임라인을 구성합니다.
이 타임라인에서는 특히 LLM 및 Generative AI에 중점을 두고 다양한 정보를 선별하고 있습니다.
어쩌면 가장 뜨거운 역사의 한 장면일지도 모르기 때문에 그 추억을 잘 간직하는 것이 중요할 것 같아 정리했습니다.
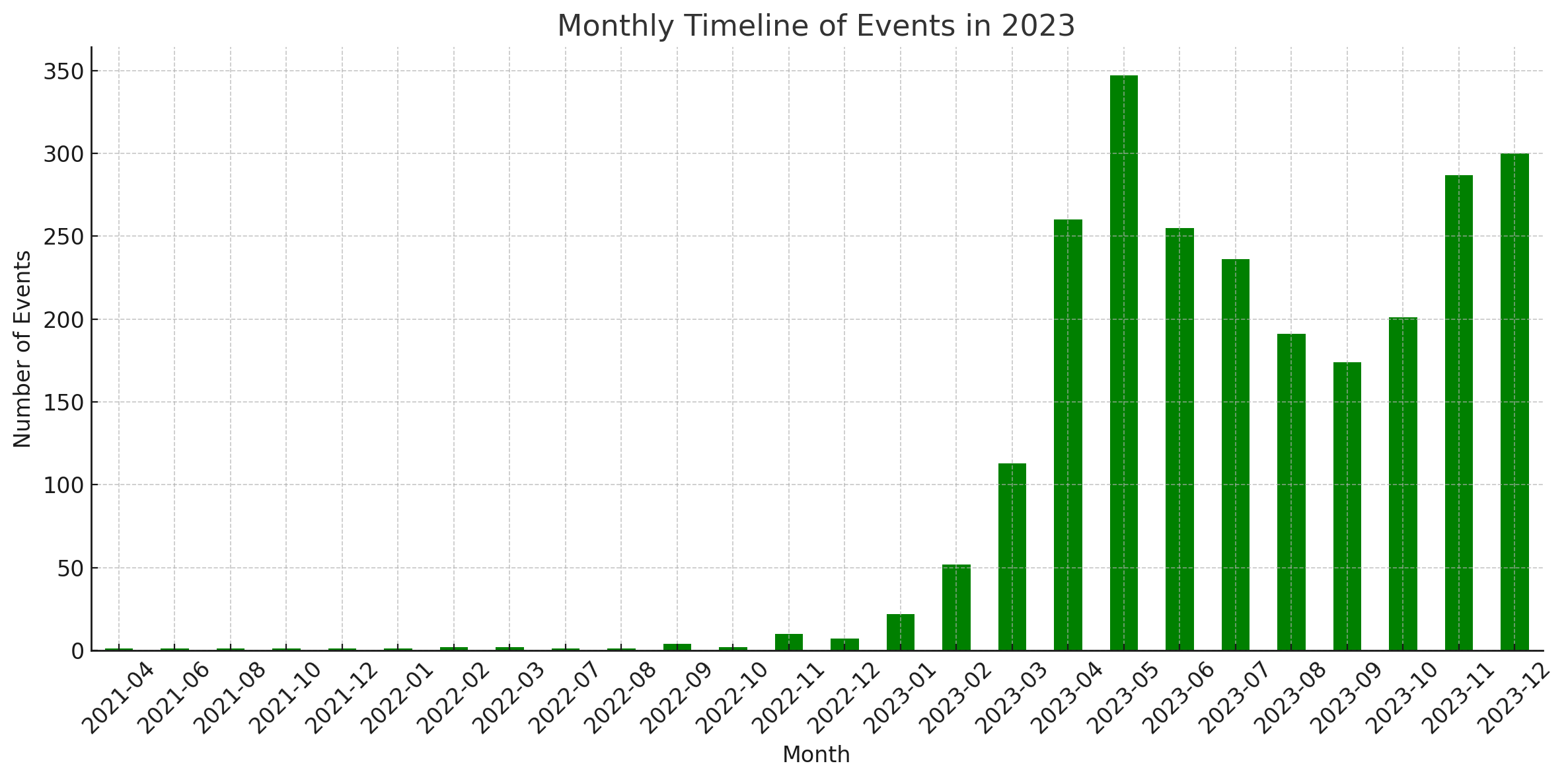
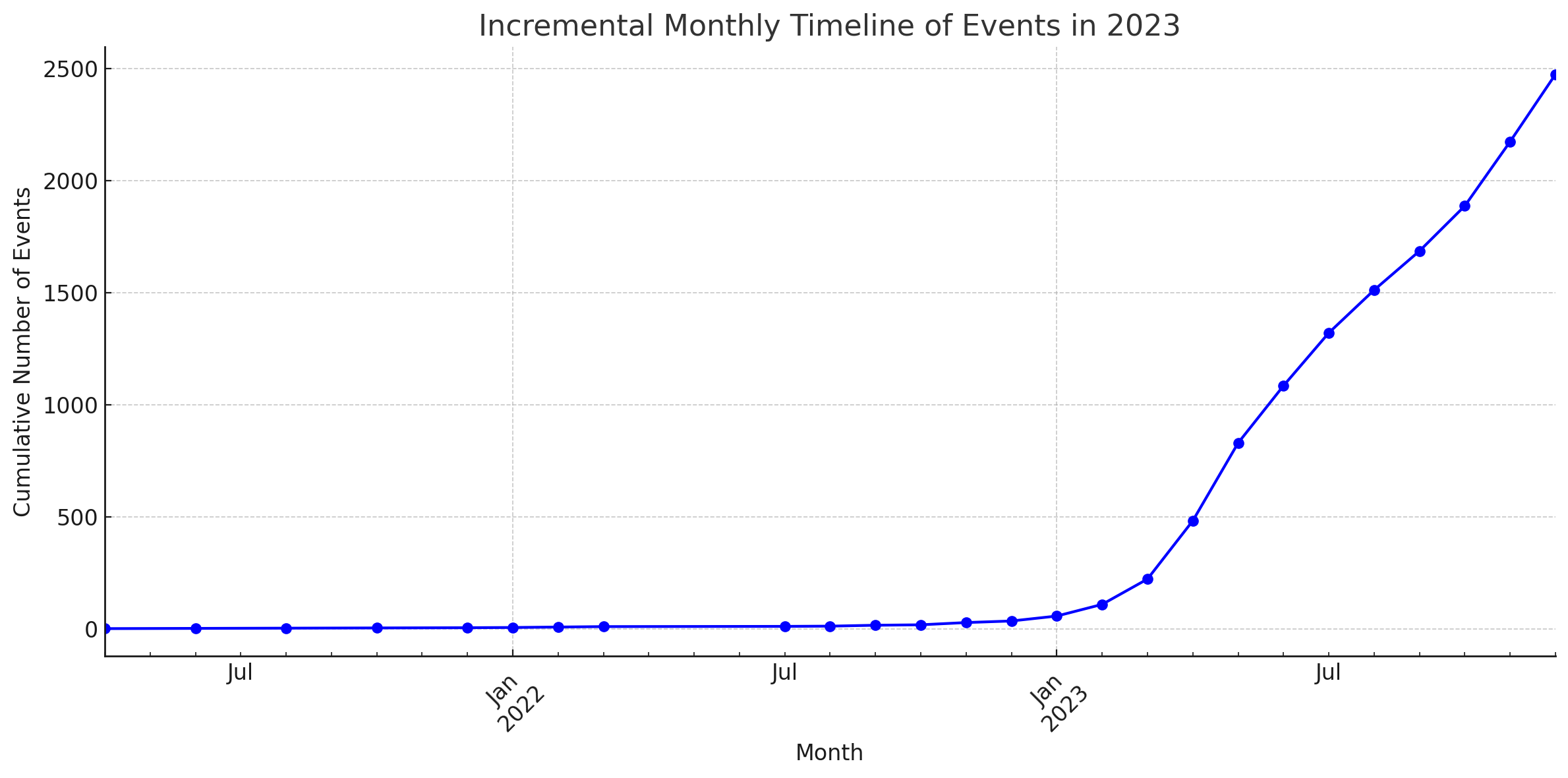
통계
이 다이어그램은 ChatGPT의 코드 해석기에 의해 생성되었습니다.
기여
이슈와 Pull Request를 보내주시면 대단히 감사하겠습니다. 이전에 오픈 소스 프로젝트에 기여한 적이 없다면 끌어오기 요청을 만드는 방법을 안내해 드리겠습니다.
해결하려는 문제를 설명하는 문제를 여는 것부터 시작하면 됩니다.
이모티콘
arXiv , PDF ?, arxiv-vanity ?, 종이 페이지 ?, 코드가 포함된 논문 ✳️, Github
특허
이 문서는 MIT 라이센스에 따라 라이센스가 부여되었습니다 © Jonghong Jeon(전종홍)
타임라인 V2
2024년
- 05/17 - OpenAI, 게시물에 대한 AI 훈련을 위해 Reddit과 계약 체결
(소식), - 05/17 - OpenAI는 발표 후 1년도 채 되지 않아 장기적인 AI 위험에 초점을 맞춘 팀을 해산합니다.
(소식), - 05/17 - 첨단 AI의 안전성에 관한 국제과학보고서
(블로그), - 05/16 - TRANSIC: 온라인 수정을 통한 학습을 통한 Sim-to-Real 정책 전송
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - Toon3D: 새로운 관점에서 만화를 보기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - 과학 문헌에서 생태학적 정보를 추출하기 위한 AI 기반 대규모 언어 모델의 신뢰성 테스트
(소식), - 05/16 - 다중 모드 기반 모델의 다중 샷 상황 내 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - 너무 늦기 전에 AI를 일시 중지하는 방법
(소식), - 05/16 - DINO 1.5 접지: 개방형 물체 감지의 "가장자리" 향상
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - GPT Store 마이닝 및 분석
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - Dual3D: 듀얼 모드 다중 뷰 잠재 확산을 통한 효율적이고 일관된 텍스트-3D 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - 카멜레온: 혼합 모드 조기 융합 기초 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 - CAT3D: 다중 뷰 확산 모델을 사용하여 3D로 무엇이든 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/15 - Xmodel-VLM: 다중 모드 비전 언어 모델을 위한 간단한 기준선
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/15 - LoRA는 덜 배우고 덜 잊어버립니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/15 - Google의 보이지 않는 AI 워터마크는 생성된 텍스트와 비디오를 식별하는 데 도움이 됩니다.
(소식), - 05/15 - Google I/O 2024: 모든 내용 발표
(블로그), - 05/15 - BEHAVIOR Vision Suite: 시뮬레이션을 통한 맞춤형 데이터 세트 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/15 - ALPINE: 언어 모델에서 자기회귀 학습의 계획 기능 공개
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - 온라인과 오프라인 정렬 알고리즘 간의 성능 격차 이해
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - SpeechVerse: 대규모 일반화 가능 오디오 언어 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - SpeechGuard: 다중 모드 대형 언어 모델의 적대적 견고성 탐색
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - 낭비할 시간이 없습니다: 모바일 비디오 이해를 위해 채널에 시간을 투자하세요
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - Hunyuan-DiT: 세밀한 중국어 이해를 갖춘 강력한 다중 해상도 확산 변환기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - 조밀한 블롭 표현을 사용한 구성 텍스트-이미지 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 - 스케일링 법칙을 넘어서: 연관 메모리를 통한 변압기 성능 이해
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - SambaNova SN40L: 데이터 흐름과 전문가 구성으로 AI 메모리 벽 확장
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - RLHF 워크플로우: 보상 모델링에서 온라인 RLHF까지
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - Plot2Code: 과학적 플롯에서 코드 생성 시 다중 모드 대형 언어 모델을 평가하기 위한 종합 벤치마크
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - OpenAI, 최신 AI 모델 GPT-4o 공개
(소식), - 05/13 - MS MARCO 웹 검색: 수백만 개의 실제 클릭 레이블이 포함된 대규모 정보가 풍부한 웹 데이터 세트
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/13 - 대규모 언어 모델에 의해 작성되는 연구의 양은 얼마나 됩니까?
(블로그), - 05/13 - 안녕하세요 GPT-4o
(블로그), - 05/13 - Coin3D: 프록시 기반 컨디셔닝을 통한 제어 가능하고 대화형 3D 자산 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 - Piccolo2: 다중 작업 하이브리드 손실 훈련을 통한 일반 텍스트 임베딩
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 - LogoMotion: 콘텐츠 인식 애니메이션을 위한 시각적 기반 코드 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/10 - INSPECT - 대규모 언어 모델 평가를 위한 오픈 소스 프레임워크
(블로그), - 05/10 - AI안전연구소, 새로운 AI 안전성 평가 플랫폼 출시
(소식), - 05/07 - SUTRA: 확장 가능한 다국어 언어 모델 아키텍처
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/07 - Meta, Llama 3 오픈 소스 LLM 출시
(소식), - 05/03 - 비전 언어 모델을 구축할 때 무엇이 중요합니까?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - WildChat: 야생의 ChatGPT 상호작용 로그 100만 개
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - StoryDiffusion: 장거리 이미지 및 비디오 생성을 위한 일관된 Self-Attention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - Prometheus 2: 다른 언어 모델 평가에 특화된 오픈 소스 언어 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - NeMo-Aligner: 효율적인 모델 정렬을 위한 확장 가능한 툴킷
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - LLM-AD: 대형 언어 모델 기반 오디오 설명 시스템
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - FLAME: 대규모 언어 모델을 위한 사실 인식 정렬
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - 단일 이미지 쌍으로 텍스트-이미지 모델 사용자 정의
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - 신경 보상을 사용한 스펙트럼 가지치기 가우스 필드
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - 언어 모델 정렬을 위한 셀프 플레이 선호도 최적화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - 편집 배치 크기가 클수록 항상 더 좋습니까? -- Llama-3를 이용한 모델 편집에 관한 실증적 연구
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - Clover: 순차 지식을 사용한 회귀적 경량 추측 디코딩
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 - 초등학교 산수에서 대규모 언어 모델 성능에 대한 주의 깊은 조사
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - 시각적 사실 검사기: 충실도가 높은 상세 캡션 생성 가능
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - STT: 자율 주행을 위한 변압기를 사용한 상태 추적
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - SemantiCodec: 일반 사운드를 위한 초저비트 전송률 시맨틱 오디오 코덱
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - Octopus v4: 언어 모델 그래프
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - MotionLCM: 잠재 일관성 모델을 통한 실시간 제어 가능한 모션 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - MicroDreamer: 점수 기반 반복 재구성을 통해 sim20초 만에 제로샷 3D 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - Lightplane: 신경 3D 필드를 위한 확장성이 뛰어난 구성 요소
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - KAN: 콜모고로프-아놀드 네트웍스
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - 반복추론 선호도 최적화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - 보이지 않는 스티치: 깊이 인페인팅으로 부드러운 3D 장면 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - InstantFamily: 제로샷 다중 ID 이미지 생성을 위한 Masked Attention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - GS-LRM: 3D 가우스 스플래팅을 위한 대규모 재구성 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - Llama-3의 컨텍스트를 하룻밤 사이에 10배 확장
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - DOCCI: 연결 및 대조 이미지에 대한 설명
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/30 - 멀티 토큰 예측을 통해 더 좋고 더 빠른 대규모 언어 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - 스타일러스: 확산형 모델을 위한 자동 어댑터 선택
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - SAGS: 구조 인식 3D 가우스 스플래팅
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - 심사위원을 심사위원으로 교체: 다양한 모델 패널을 통해 LLM 세대 평가
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - NIST AI RMF 생성 AI 프로필
(소식), - 04/29 - LoRA Land: GPT-4와 경쟁하는 310개의 미세 조정된 LLM, 기술 보고서
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - 캥거루: 이중 조기 종료를 통한 무손실 자기 추측 디코딩
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/29 - 의학에서 Gemini 모델의 역량
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/28 - Paint by Inpaint: 이미지 개체를 먼저 제거하여 추가하는 방법 배우기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/28 - LEGENT: 구체화된 에이전트를 위한 개방형 플랫폼
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/27 - Ag2Manip: 에이전트에 구애받지 않는 시각적 및 동작 표현으로 새로운 조작 기술 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/26 - MaPa: 3D 모양을 위한 텍스트 기반 사실적 재질 페인팅
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/26 - BlenderAlchemy: Vision-Language 모델로 3D 그래픽 편집
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - Tele-FLM 기술 보고서
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - SEED-Bench-2-Plus: 텍스트가 풍부한 시각적 이해력을 갖춘 다중 모드 대형 언어 모델 벤치마킹
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - Gecko를 사용한 텍스트-이미지 평가 재검토: 지표, 프롬프트 및 인간 평가에 대해
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - PLLaVA: 비디오 밀도 캡션을 위한 이미지에서 비디오까지의 매개변수 없는 LLaVA 확장
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - LLM이 컨텍스트를 최대한 활용하도록 하세요
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - 항목을 하나씩 나열: 다중 모드 LLM을 위한 새로운 데이터 소스 및 학습 패러다임
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - 레이어 건너뛰기: 조기 종료 추론 및 자체 추측 디코딩 활성화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - Interactive3D: 대화형 3D 생성으로 원하는 것을 만듭니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - GPT-4V까지 얼마나 남았나요? 오픈 소스 제품군을 통해 상용 다중 모드 모델과의 격차 해소
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/25 - ConsistencyID: 세밀한 다중 모드 신원 보존을 통한 인물 사진 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - XC-캐시: 효율적인 LLM 추론을 위해 캐시된 컨텍스트에 교차 참여
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - 첨단 AI 비서의 윤리
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - PuLID: 대비 정렬을 통한 Pure 및 Lightning ID 사용자 정의
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - NeRF-XL: 다중 GPU로 NeRF 확장
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - MotionMaster: 비디오 생성을 위한 교육이 필요 없는 카메라 모션 전송
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - MoDE: 클러스터링을 통한 CLIP 데이터 전문가
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - MMT-Bench: 멀티태스크 AGI를 향한 대규모 비전 언어 모델을 평가하기 위한 포괄적인 멀티모달 벤치마크
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - MaGGIe: Masked Guided 점진적 인간 인스턴스 매트팅
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - ID-Aligner: 보상 피드백 학습을 통해 신원 보존 텍스트-이미지 생성 강화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - 제어 가능한 합성을 위한 편집 가능한 이미지 요소
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - CatLIP: 웹 규모 이미지-텍스트 데이터에 대한 2.7배 더 빠른 사전 훈련을 통한 CLIP 수준의 시각적 인식 정확도
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/24 - BASS: 일괄 주의 최적화 추측 샘플링
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - 변환기는 n-gram 언어 모델을 나타낼 수 있음
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - Pegasus-v1 기술 보고서
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - 여러 전문가의 혼합
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/23 - FlashSpeech: 효율적인 제로샷 음성 합성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - SnapKV: LLM은 세대 이전에 귀하가 무엇을 찾고 있는지 알고 있습니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - SEED-X: 통합된 다중 세분성 이해 및 생성을 갖춘 다중 모드 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - 장면 좌표 재구성: Relocalizer의 증분 학습을 통한 이미지 컬렉션 포즈
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - Phi-3 기술 보고서: 전화기에서 로컬로 실행되는 고성능 언어 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - OpenELM: 오픈 소스 교육 및 추론 프레임워크를 갖춘 효율적인 언어 모델 제품군
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - MultiBooth: 텍스트에서 이미지의 모든 개념 생성을 향하여
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - H-Infinity 이동 제어 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - 저비트 양자화 LLaMA3 모델은 얼마나 좋은가요? 경험적 연구
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - 단계 조정: 확산 모델에서 샘플링 일정 최적화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/22 - 다중 모드 자동 해석 에이전트
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/21 - Hyper-SD: 효율적인 이미지 합성을 위한 궤적 분할 일관성 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/21 - AdvPrompter: LLM을 위한 빠른 적응형 적대적 프롬프트
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/20 - 음악 일관성 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - 명령어 계층 구조: 권한 있는 명령어의 우선순위를 지정하기 위한 LLM 교육
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - TextSquare: 텍스트 중심의 시각적 교육 조정 확장
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - PhysDreamer: 비디오 생성을 통한 3D 개체와의 물리 기반 상호 작용
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - LLM-R2: 쿼리 효율성을 높이기 위한 대규모 언어 모델 강화 규칙 기반 재작성 시스템
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - 현실은 얼마나 현실인가? 제한되지 않은 적대적 사례를 위한 인간 평가 프레임워크
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - 실용적인 기능 수준 프로그램 복구를 통해 어디까지 갈 수 있나요?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - Groma: 다중 모드 대형 언어 모델 기반을 위한 현지화된 시각적 토큰화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - 가우스 스플래팅에 SFM 초기화가 필요합니까?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 - AutoCrawler: 웹 크롤러 생성을 위한 점진적인 이해 웹 에이전트
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - TriForce: 계층적 추측 디코딩을 통한 긴 시퀀스 생성의 무손실 가속
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - 상상력, 탐색, 비판을 통한 LLM의 자기 개선을 위해
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - 보상 재사용: 제로 샷 교차 언어 정렬을 위한 보상 모델 이전
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - Reka 코어, 플래시 및 엣지: 강력한 다중 모드 언어 모델 시리즈
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - OpenBezoar: 혼합된 명령 데이터로 훈련된 작고 비용 효율적인 개방형 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - MeshLRM: 고품질 메시를 위한 대규모 재구성 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - MLCommons의 AI 안전 벤치마크 v0.5 소개
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - Meta Llama 3 소개: 현재까지 가장 유능한 공개 LLM
(블로그), - 04/18 - EdgeFusion: 온디바이스 텍스트-이미지 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - BLINK: 다중 모드 대형 언어 모델은 볼 수 있지만 인식할 수는 없습니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - AniClipart: 텍스트-비디오 우선순위를 사용한 클립아트 애니메이션
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - MoA: 개인화 이미지 생성에서 주제-맥락 분리를 위한 주의 혼합
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - FlowMind: LLM을 통한 자동 워크플로 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - 동적 타이포그래피: 단어에 생명을 불어넣기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - 이제 Stable Diffusion 3 API 사용 가능
(트위터), (블로그), (데모), - 04/16 - VASA-1: 실시간으로 생성된 실제와 같은 오디오 기반 말하는 얼굴
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/16 - 지나 라이몬도 미국 상무장관, 미국 AI 안전 연구소 리더십 팀 확장 발표
(소식), - 04/16 - 잠재 확산을 이용한 장편 음악 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/15 - LLM 평가자는 자신의 세대를 인정하고 선호합니다
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/15 - Video2Game: 단일 비디오에서 실시간, 대화형, 사실적 및 브라우저 호환 환경 제공
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - Tango 2: 직접 선호도 최적화를 통한 확산 기반 텍스트-오디오 생성 정렬
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/15 - 신경 복사장 인페인팅을 위한 잠재 확산 모델 길들이기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - Opus는 Turing 기계로 작동할 수 있습니다.
(지저귀다), - 04/15 - MathGPT: Llama 2를 활용하여 고도로 맞춤화된 학습을 위한 플랫폼 구축
- 04/15 - HQ-Edit: 명령어 기반 이미지 편집을 위한 고품질 데이터세트
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - Ctrl-Adapter: 모든 확산 모델에 다양한 제어를 적용하기 위한 효율적이고 다양한 프레임워크
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - 압축은 지능을 선형적으로 나타냅니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 - CompGS: 압축된 가우스 스플래팅을 통한 효율적인 3D 장면 표현
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/14 - TextHawk: 다중 모드 대형 언어 모델의 효율적인 세분화된 인식 탐색
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/13 - Cathie Wood가 새로운 OpenAI 지분으로 ChatGPT 붐에 뛰어들었습니다.
(소식), - 04/12 - Scaling (Down) CLIP: 데이터, 아키텍처 및 교육 전략에 대한 종합 분석
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Visual Foundation 모델의 3D 인식 조사
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - 더 적은 토큰으로 소규모 기반 LM 사전 교육
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - 저수준 시력 작업을 위한 언어 지도의 견고성에 관하여: 깊이 추정을 통한 발견
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - MonoPatchNeRF: 패치 기반 단안 유도로 신경 복사장 개선
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Megalodon: 무제한 컨텍스트 길이를 사용한 효율적인 LLM 사전 훈련 및 추론
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 - ChatGPT가 학자들의 글쓰기 스타일을 변화시키고 있습니까?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - COCONut: COCO 세분화 현대화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - AI 칩으로 에너지 예산을 99% 이상 절감
(소식), - 04/12 - AdapterSwap: 데이터 제거 및 액세스 제어 보장을 갖춘 LLM의 지속적인 교육
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - Grok-1.5 비전 미리보기
(데모), - 04/12 - 좋은 점, 나쁜 점, 그리고 인간적인 핀
(소식), - 04/12 - 유료 ChatGPT 사용자는 이제 GPT-4 Turbo에 액세스할 수 있습니다.
(트위터), (뉴스), , () - 04/11 - AI 감사기준위원회의 필요성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/11 - 지속적인 학습을 위한 Transformer 기억하기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Amazon은 인공 지능 분야의 선도적인 목소리인 Andrew Ng를 이사회에 추가했습니다.
(소식), - 04/11 - Adobe, AI 모델 구축을 위해 분당 3달러에 비디오 구입
(소식), - 04/11 - UltraEval: LLM을 위한 유연하고 종합적인 평가를 위한 경량 플랫폼
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - 개방형 어휘 분할을 위한 전이 가능하고 원칙적인 효율성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - SWE 에이전트
(트위터), (데모), , () - 04/11 - 스파스 레인포머
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Rho-1: 모든 토큰이 필요한 것은 아닙니다
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - ResearchAgent: 대규모 언어 모델을 사용한 과학 문헌에 대한 반복적 연구 아이디어 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - RecurrentGemma: 효율적인 개방형 언어 모델을 위한 과거의 변환기 이동
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - OSWorld: 실제 컴퓨터 환경에서 개방형 작업을 위한 다중 모달 에이전트 벤치마킹
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - LLoCO: 긴 컨텍스트를 오프라인으로 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - 대규모 언어 모델(LLM)을 활용하여 협업적인 Human-AI 온라인 위험 데이터 주석 지원
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - JetMoE: 100만 달러로 Llama2 성능 달성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (프로젝트), (twitter), , (✳️), () - 04/11 - HGRN2: 상태 확장이 포함된 게이트 선형 RNN
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - 단어에서 숫자로: 문맥 내 예제가 제공되면 대규모 언어 모델이 비밀리에 유능한 회귀자가 됩니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Ferret-v2: 대규모 언어 모델의 참조 및 접지를 위한 향상된 기준선
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - ControlNet++: 효율적인 일관성 피드백으로 조건부 제어 개선
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - 장기 데이터 세트에서 상황 인식 비디오 이상 탐지
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - ChatGPT-3.5, LLM을 위한 스트리트 파이터 III 토너먼트에서 Claude 3가 픽셀화된 엉덩이를 찼습니다.
(소식), - 04/11 - ChatGPT는 과거에 대한 미래의 이야기를 들려줄 때 미래를 예측할 수 있습니다
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - 언어 모델의 합성 데이터에 대해 학습한 모범 사례 및 교훈
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - Street Fighter 3에서 전투를 통해 LLM 벤치마크
(데모), , () - 04/11 - 오디오 대화: 오디오 및 음악 이해를 위한 대화 데이터세트
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - 제한된 간격으로 지침을 적용하면 확산 모델에서 샘플 및 배포 품질이 향상됩니다.
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - AmpleGCG: 개방형 및 폐쇄형 LLM 모두 탈옥을 위한 적대적 접미사의 보편적이고 전송 가능한 생성 모델 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 - LM 투명성 도구: Transformer 언어 모델 분석을 위한 대화형 도구
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - 이제 Gemini 1.5 Pro가 오디오를 이해합니다.
(지저귀다), - 04/10 - 개념 깊이 탐구: 대규모 언어 모델이 어떻게 다양한 계층에서 지식을 획득합니까?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 - Urban Architect: 사전 레이아웃을 통한 조정 가능한 3D 도시 장면 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - RealmDreamer: 인페인팅 및 깊이 확산을 사용한 텍스트 기반 3D 장면 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - OpenAI와 Meta가 인간처럼 추론할 수 있는 AI 모델 출시를 앞두고 있다고 보고서가 밝혔습니다.
(소식), - 04/10 - MetaCheckGPT -- LLM 불확실성과 메타 모델을 사용하는 다중 작업 환각 탐지기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - Meta는 Llama 3 오픈 소스 LLM이 다음 달에 출시될 것이라고 확인합니다.
(소식), - 04/10 - 컨텍스트를 남기지 않음: Infini-Attention을 갖춘 효율적인 무한 컨텍스트 변환기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - 증분 XAI: 증분 설명을 통한 기억에 남는 AI 이해
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - DreamScene360: 파노라마 가우스 스플래팅을 사용한 제약 없는 텍스트-3D 장면 생성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - 마파두부에 커피가 들어가나요? 식품 관련 문화 지식에 대한 LLM 탐색
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - BRAVE: 비전 언어 모델의 시각적 인코딩 확장
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - AI 스타트업 Mistral, OpenAI, Meta, Google과 경쟁할 281GB AI 모델 출시
(소식), - 04/10 - 원격 감시를 위한 에이전트 중심 생성 의미 통신
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - LLaMA 디코더를 Vision Transformer에 적용
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 - 모바일 네트워크의 비판적 사고를 위한 생성적 AI 통합에 관한 설문조사
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - 한번 살펴보세요! 언어 모델 탈옥 평가 방법 재검토
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - 자: 장기 컨텍스트 언어 모델의 실제 컨텍스트 크기는 얼마입니까?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - 가우스 스플래팅의 치밀화 수정
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - 휴대용 개체를 3D로 재구성
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - RAR-b: 검색 벤치마크로서의 추론
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - 개인정보 보호 프롬프트 엔지니어링: 설문조사
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - LLM이 생성한 소스 코드의 효율성 평가에 대해
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/09 - OmniFusion 기술 보고서
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - MuPT: 생성적 기호 음악 사전 훈련된 변환기
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - MiniCPM: 확장 가능한 훈련 전략을 갖춘 소규모 언어 모델의 잠재력 공개
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Magic-Boost: 다중 뷰 조건 확산으로 3D 생성 강화
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - LLM2Vec: 대규모 언어 모델은 비밀리에 강력한 텍스트 인코더입니다
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - InternLM-XComposer2-4KHD: 336픽셀에서 4K HD까지 해상도를 처리하는 선구적인 대형 비전 언어 모델
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Hash3D: 훈련이 필요 없는 3D 생성 가속
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Google, 생성 AI용 오픈소스 프로젝트 공개
(소식), - 04/09 - 코끼리는 절대 잊지 않습니다: 대규모 언어 모델의 표 형식 데이터 암기 및 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Apple은 새로운 Ferret-UI LLM을 공개했습니다. 이 AI는 iPhone 화면을 읽을 수 있습니다.
(소식), - 04/09 - AEGIS: LLM 전문가 앙상블을 통한 온라인 적응형 AI 콘텐츠 안전 조정
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - YaART: 또 다른 ART 렌더링 기술
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - WILBUR: 강력하고 정확한 웹 에이전트를 위한 적응형 상황 내 학습
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - UniFL: 통합 피드백 학습을 통해 안정적인 확산 개선
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - Unbridled Icarus: 다중 모드 대형 언어 모델 보안에서 이미지 입력의 잠재적 위험에 대한 조사
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - 환각 리더보드 - 대규모 언어 모델에서 환각을 측정하기 위한 공개적인 노력
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - LLM 기반 프로그램 복구의 사실 선택 문제
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/08 -Swapanything : 개인화 된 시각적 편집에서 임의의 객체 교환 활성화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08 -Sambalingo : 큰 언어 모델을 가르치는 새로운 언어
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08- 부정적인 선호도 최적화 : 치명적인 붕괴에서 효과적인 배우기까지
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08 -Naver 데뷔 다국어 하이퍼 클로바 X LLM 아시아 주권 AI를 구축하는 데 사용할 것입니다.
(소식), - 04/08 -MOMA : 빠른 개인화 된 이미지 생성을위한 멀티 모달 LLM 어댑터
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08 -MEDEXPQA : 의료 질문 답변을위한 대형 언어 모델의 다국어 벤치마킹
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08- MA-LMM : 장기 비디오 이해를위한 메모리-방지 대형 멀티 모달 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08 -LayoutLlm : 문서 이해를위한 큰 언어 모델을 가진 레이아웃 명령 튜닝
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 -FERRET -UI : 멀티 모달 LLM을 통한 접지 모바일 UI 이해
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08- 대형 언어 모델의 중재 적 추론 능력 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08 -Eagle and Finch : 매트릭스 값 상태 및 동적 재발이있는 RWKV
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 -CodeClm : 맞춤형 합성 데이터와 언어 모델을 정렬
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/08 -Autocoderover : 자율 프로그램 개선
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/07- 부하 예측의 TimeGpt : 대형 시계열 모델 관점
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/07 -Openai는 GPT -4를 훈련시키기 위해 백만 시간 이상의 YouTube 동영상 전사
(소식), - 04/07 -Magictime : 변성 시뮬레이터로서의 시간 경과 비디오 생성 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 -Byteedit : 생성 이미지 편집 부스트, 준수 및 가속화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/06- 의사의 대다수 투표는 병리학에 대한 AI 의존에 대한 적절성을 향상시킵니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) - 04/06- 확산 -RWKV : 확산 모델을위한 RWKV 유사 아키텍처 스케일링
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/06- Datenerf : NERF의 깊이 인식 텍스트 기반 편집
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/06- Beyondscene : 사전 위험 확산으로 고해상
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/06- 인간의 유용성을 최적화하여 확산 모델을 정렬합니다
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/06- 계획과 같은 작업을위한 기초 모델을 처음부터 시작하는 사례
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05- 미세 조정 및 양자화로부터 LLM 취약성 증가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05 -SpatialTracker : 3D 공간에서 2D 픽셀 추적
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05- 큰 언어 모델을 가진 사회적 기술 훈련
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05 -Sigma : 멀티 모달 시맨틱 세분화를위한 시암 맘바 네트워크
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/05- 강력한 가우스 플래팅
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05 -Physavatar : 시각적 관찰에서 옷을 입은 3D 아바타의 물리 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05- Koala : 키 프레임 조건 긴 비디오 LLM
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05- 단서 : LLM에 대한 임상 언어 이해 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05 -Chinese Tiny LLM : 중국 중심의 대형 언어 모델을 예방
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/05- 복잡한 비교에서 인간 지원 : 규모의 자동 정보 비교
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- 두 팔로 구체화 된 AI : 제로 샷 학습, 안전 및 모듈성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) - 04/04- 언어 모델 진화 : 반복적 인 학습 관점
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- 시각화가 큰 언어 모델에서 공간 추론을 유발합니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) (Twitter), - 04/04- 지수 데이터가없는 "Zero -Shot"없음 : 사전 여면 개념 주파수는 멀티 모달 모델 성능을 결정합니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- LLM 응답에서 오류 감지시 LLM 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- 주관적인 질문 수정으로 정보 추출에서 생성 언어 모델 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- 직접 내쉬 최적화 : 언어 모델 교육 일반적인 선호도와 자기 개선
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- CBR-RAG : 법적 질문 답변에 대한 LLM의 검색 증강 생성에 대한 사례 기반 추론
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- 제어 엔지니어링에서 대형 언어 모델의 기능 : GPT -4, Claude 3 Opus 및 Gemini 1.0 Ultra에 대한 벤치 마크 연구
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04 -CANTTALKABORTHIS : 대화에서 주제를 유지하기 위해 언어 모델을 정렬합니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04 -Autowebglm : 대형 언어 모델 기반 웹 탐색 에이전트를 부트 스트랩 및 강화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- 신경 압축 텍스트에 대한 LLM을 훈련시킵니다
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04 -REFT : 언어 모델에 대한 표현 미세
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- Red Teaming GPT-4V : GPT-4V는 UNI/Multi-Modal 탈옥 공격에 안전한가요?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- RALL-E : 텍스트 음성 합성을위한 추진력을 가진 강력한 코덱 언어 모델링
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04 -PointInfinity : 해상도 불변 지점 확산 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- MINIGPT4-VIEDO : 인터리브 시각 텍스트 토큰을 사용한 비디오 이해를위한 멀티 모달 LLM 발전
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Comat : 텍스트-이미지 확산 모델을 이미지-텍스트 컨셉 일치와 정렬
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04 -CodeeditorBench : 대형 언어 모델의 코드 편집 기능 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/04 -Autowebglm : 대형 언어 모델 기반 웹 탐색 에이전트를 부트 스트랩 및 강화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- 시각적 자동 회귀 모델링 : 차세대 예측을 통한 확장 가능한 이미지 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- 확산 기반 텍스트-이미지 생성의 확장 성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/03- 많은 샷 탈옥
() - 04/03- LVLM-intrepret : 대규모 시력 모델을위한 해석 도구
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/03- 컴파일러로서 언어 모델 : 의사 코드 실행 시뮬레이션 언어 모델에서 알고리즘 추론을 향상시킵니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/03- 인스턴트 스타일 : 텍스트-이미지 생성에서 스타일 보존을 향한 무료 점심
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- 프레디터 : 주파수 분해에 의한 고 충실도 및 전송 가능한 NERF 편집
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/03- 텍스트-이미지 확산 모델에서 상호 관찰을 번거롭게 만듭니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- Chatglm-Math : 자체 크리티컬 파이프 라인을 사용하여 대형 언어 모델에서 수학 문제 해결 향상
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/02- 영국 및 미국 AI 안전 과학 파트너십 발표
(소식), - 04/02- 계획 도메인 생성기로서 대형 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) - 04/02 -Poro 34B 및 다국어의 축복
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/02 -Octopus V2 : 슈퍼 에이전트를위한 기기 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/02- 혼합 내심 : 변압기 기반 언어 모델에서 동적으로 할당 된 컴퓨팅
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/02- 긴 컨텍스트 LLMS는 긴 컨텍스트 학습으로 어려움을 겪고 있습니다
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 -LLM -ABR : 대형 언어 모델을 통한 적응 형 비트 전송률 알고리즘 설계
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/02- 대형 언어 모델이 행동 건강 관리의 미래를 바꿀 수 있습니다 : 책임있는 개발 및 평가 제안
() - 04/02 -Hyperclova x 기술 보고서
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Cameractrl : 텍스트-비디오 생성을위한 카메라 제어 활성화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/02- 선호 트리를 가진 LLM 추론 일반인들의 발전
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- 검색 흐름 (SOS) : 언어 검색 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 -LLM Mastermind : 대형 언어 모델을 사용한 전략적 추론 조사
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/01- AI 대형 언어 모델의 상승과 상승 (LLMS)
(블로그), - 04/01- 스트리밍 밀도가 높은 비디오 캡션
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- 확산 모델에서 스타일 유사성 측정
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- 올바르게하기 : 텍스트-이미지 모델의 공간 일관성 향상
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 -AI 회사의 데이터가 많은 AI 회사의 경우 인터넷이 너무 작습니다.
(소식), - 04/01- FlexIdReamer : Flexicubes가있는 단일 이미지-3D 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/01- 평가판 : 대형 언어 모델 평가를위한 통합 및 접근 가능한 라이브러리
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- 언어 모델 보상에서 비디오 대형 멀티 모달 모델의 직접 환경 설정 최적화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 -DBRX, 지속적인 사전 여지, 보상 벤치, 더 빠른 추론 등
(블로그), - 04/01- Cosmicman : 인간을위한 텍스트-이미지 기초 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/01- 통제 된 이미지 생성을위한 조건증 신경망
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/01- 더 큰 것은 항상 더 나은 것은 아닙니다 : 잠재 확산 모델의 특성 스케일링 특성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 04/01- 대형 언어 모델 초인간 화학자입니까?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/31 -Wavllm : 강력하고 적응적인 연설 대형 언어 모델을 향해
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/31- 플러그인에 지쳤습니까? 대형 언어 모델은 엔드 투 엔드 추천자 일 수 있습니다
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/30- 대형 언어 모델 강화 강화 학습에 대한 설문 조사 : 개념, 분류 및 방법
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/30 -ST -LLM : 대형 언어 모델은 효과적인 시간 학습자입니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) - 03/30- 레이아웃 인식 언어 모델의 소음 인식 교육
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/30 -Magritte : 이미지, Topview 및 Text의 조작 및 생성 3D 실현
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) - 03/30- Aurora-M : 미국 행정 주문에 따라 최초의 오픈 소스 다국어 언어 모델 레드 팀
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29- 해결할 수없는 문제 탐지 : 비전 언어 모델의 신뢰성 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29- Transformer-Lite : 휴대폰 GPU에 대형 언어 모델의 고효율 배포
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29- Snap-It, Tap-It, Splat-It : 도전적인 표면을 재구성하기위한 촉각 정보 3D 가우시안 스플릿
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/ 29- 영역 : 언어 모델링으로서의 참조 해상도
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29 -NVIDIA H200 GPUS CRUSH MLPERF의 LLM 추론 벤치 마크
(소식), - 03/29 -Mambamixer : 듀얼 토큰 및 채널 선택이있는 효율적인 선택적 상태 공간 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29 -Llava -Gemma : 컴팩트 한 언어 모델로 멀티 모달 기초 모델 가속화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29- InstantsPlat : 40 초 만에 구인이없는 스파스 뷰 포즈가없는 가우시안 스플릿
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29 -Gecko : 대형 언어 모델에서 증류 된 다목적 텍스트 임베드
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29 -Dijiang : 컴팩트 kernelization을 통한 효율적인 대형 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/29- Deepmind는 LLM을 사실 확인할 수있는 AI 기반 앱인 Safe를 개발합니다.
(소식), - 03/29 -CTRL -SIM : 오프라인 강화 학습을 가진 반응성 및 제어 가능한 주행 에이전트
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/29- 우리는 대규모 비전 언어 모델을 평가하기에 올바른 방법을 사용하고 있습니까?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/28 -SDPO : 데이터를 한 번에 모두 사용하지 마십시오.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/28 -MESH2NERF : 신경 방사선 표현 및 생성을위한 직접 메쉬 감독
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/28- 언어 모델에서 단락 암기
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/28 -Jamba : 하이브리드 변압기 - 엄마 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/28 -GaussianCube : 3D 생성 모델링을위한 최적의 전송을 사용하여 가우시안 스플릿 구조화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/28 -Claude 3은 AI 봇의 결투에서 GPT -4를 추월합니다. 행동에 참여하는 방법은 다음과 같습니다
(소식), - 03/28- Grok -1.5 발표
(블로그), (데모), - 03/27- 법적 자율성을 향한 길 : 대형 언어 모델, 전문가 시스템 및 베이지안 네트워크를 사용하여 법적 정보 추출, 변환,로드 및 계산에 대한 상호 운용적이고 설명 가능한 접근 방식
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27 -Vitar : 모든 해상도가있는 비전 변압기
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27- Op-Device Virtual Assistant를위한 세계적 영어 언어 모델로
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27 -TextCraftor : 텍스트 인코더는 이미지 품질 컨트롤러가 될 수 있습니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27 -ObjectDrop : Photorealistic 객체 제거 및 삽입을위한 부트 스트랩 카운터 평범
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27- Mini-Gemini : 다중 유산 비전 언어 모델의 잠재력을 채굴
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/27- 큰 언어 모델의 장기 사실
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 -LITA : 언어 지시 시간 - 국소화 보조
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 -Garment3dgen : 3D 의류 스타일 및 질감 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27 -Gamba : 단일보기 3D 재건을 위해 맘바와 함께 가우시안 스플릿과 결혼
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27- Flexedit : 유연하고 제어 가능한 확산 기반 객체 중심 이미지 편집
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/27 -Biomedlm : 생의학 텍스트에 대해 훈련 된 2.7b 매개 변수 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/26- MAGIS : GitHub 문제 해결을위한 LLM 기반 다중 에이전트 프레임 워크
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/26- 더 깊은 층의 불합리한 비 효율성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/26- TC4D : 궤적 조건 텍스트-4D 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/26- Octree-GS : LOD 구조화 된 3D 가우스와 일관된 실시간 렌더링을 향해
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/26- DBRX 소개 : 새로운 최첨단 오픈 LLM
(블로그), - 03/26 -InternLM2 기술 보고서
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/26- 자동 프롬프트 최적화를 통한 텍스트-이미지 일관성 향상
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/26- 인텔 데이터 센터 GPU의 완전 퓨즈 멀티 레이어 퍼셉트론
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 -EGOLIFTER : Egocentric 인식을위한 오픈 월드 3D 세분화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/26 -Aniportrait : 사진 초상화 애니메이션의 오디오 구동 합성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/26- 기하학적으로 정확한 방사선 필드에 대한 2D 가우시안 스플릿
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/25- LLMS의 임상 기능에 대한 자동 평가를 향해 : 메트릭, 데이터 및 알고리즘
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/25- 수리 에이전트 : 프로그램 수리를위한 자율적 인 LLM 기반 에이전트
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/25- RL 일관성 모델 : 더 빠른 보상 안내 텍스트-이미지 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/25- VP3D : 텍스트-3D 생성에 대한 2D 시각적 프롬프트가 해제
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/25- 여행 : 이미지-비디오 확산 모델 이전 이미지 노이즈를 가진 시간 잔차 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/25- SDXS : 이미지 조건을 가진 실시간 1 단계 잠복 확산 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 -LLM 에이전트 운영 체제
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 -Flashface : 고 충실도 정체성 보존을 가진 인간 이미지 개인화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/25- Dreampolisher : 기하학적 확산을 통한 고품질 텍스트-3D 세대를 향해
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/25- Be Helif : 다중 개체 텍스트-이미지 생성에 대한 경계주의
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/23- LLM 기반 코드 생성이 소프트웨어 개발 프로세스를 충족하는 경우
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/22- 주제 : 몇 가지 모범에서 테마 인식 3D 자산 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/22 -Simba : 시력 및 다변량 시계열을위한 단순화 된 맘바 기반 아키텍처
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 -LLM2LLM : 새로운 반복 데이터 향상으로 LLM을 높이기
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/22- Latte3D : 대규모 상각 된 텍스트-에 enhanced3D 합성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/22 -Internvideo2 : 멀티 모달 비디오 이해를위한 비디오 기초 모델 스케일링
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/22- 추종자 : 지침을 따르는 정보 검색 모델 평가 및 교육
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 -Dragapart : 관절화 된 개체에 대한 part 수준 동작 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/22- 큰 언어 모델이 컨텍스트에서 탐색 할 수 있습니까?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/22- Allhands : 대규모 언어 모델을 통한 대규모 구두 피드백에 대해 물어봐
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss) - 03/21- Peergpt : LLM 기반 동료 에이전트의 역할을 팀 중재자 및 어린이 협력 학습 참가자로서 조사
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21 -Stylecinegan : 미리 훈련 된 스타일 간을 사용한 Landscape Cinemagraph Generation
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/21- Streamingt2v : 텍스트에서 일관되고 역동적이며 확장 가능한 긴 비디오 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/21- 리노이즈 : 반복적 인 노이징을 통한 실제 이미지 역전
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21- 교정에 대한 의지 : 생성 언어 모델과 채팅
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21 -Rakutenai -7B : 일본어의 큰 언어 모델 확장
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21 -MyVLM : 사용자 별 쿼리를위한 VLM을 개인화합니다
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21 -Mathverse : 멀티 모달 LLM이 시각적 수학 문제의 다이어그램을 진정으로보고 있습니까?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21 -GRM : 효율적인 3D 재구성 및 생성을위한 대형 가우스 재구성 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/21- 총회는 인공 지능에 대한 랜드 마크 해상도를 채택합니다.
(소식), - 03/21- 가우스 프로스팅 : 실시간 렌더링을 가진 편집 가능한 복잡한 방사선 필드
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21- 시간과 공간 사이의 탐사 적
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21- 컨텐츠 프레임 모션 레이션 분해를 통한 효율적인 비디오 확산 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21- DreamReward : 인간 선호도를 가진 텍스트-3D 세대
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/21 -COBRA : 효율적인 추론을위한 Mamba 확장 대형 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/21- 챔피언 : 3D 파라 메트릭 지침을 가진 제어 가능하고 일관된 인간 이미지 애니메이션
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/21- Anyv2V : 비디오 대비 비디오 편집 작업을위한 플러그 앤 플레이 프레임 워크
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20- 매핑 LLM 보안 환경 매핑 : 포괄적 인 이해 관계자 위험 평가 제안
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20 -Zigma : Zigzag Mamba 확산 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 -VSTAR : 더 긴 동적 비디오 합성을위한 생성 시간 간호
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20- 리워드 벤치 : 언어 모델링에 대한 보상 모델 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/20- 반전 저주를 간호하기위한 역 훈련
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20- Radsplat : 900+ FPS로 강력한 실시간 렌더링을위한 Radiance Field Informed Gaussian Splatting
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20 -Mora : 다중 에이전트 프레임 워크를 통해 일반 비디오 생성 활성화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/20- Llamafactory : 100 개 이상의 언어 모델의 통합 효율적인 미세 조정
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/20- Idadapter : 텍스트-이미지 모델의 튜닝 프리 개인화를위한 혼합 기능 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20 -Hyperllava : 멀티 모달 대형 언어 모델을위한 동적 시각 및 언어 전문가 튜닝
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/20- 위험한 기능에 대한 프론티어 모델 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20 -DepthFM : 흐름 일치로 빠른 단안 깊이 추정
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20- 압축 3D : 단일 이미지에서 3D 생성을위한 압축 잠재 공간
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/20- Be-your-outpainter : 입력 별 적응을 통해 비디오가 돋보이는 비디오 마스터 링
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- 더 큰 비전 모델이 언제 필요하지 않습니까?
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- VID2ROBOT : 교차 변압기를 사용한 엔드 투 엔드 비디오 조건 정책 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- 계산 병리를위한 일반 목적 재단 모델로
() - 03/19- Texdreamer : 제로 샷 고 충실도 3D 인간 질감 생성을 향해
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- 장면 : 자동 회귀 구조화 된 언어 모델로 장면 재구성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- MPLUG-DOCOWL 1.5 : OCR-FREE 문서 이해를위한 통합 구조 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 -Magic Fixup : 동적 비디오를보고 사진 편집을 간소화합니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- LLMLINGUA-2 : 효율적이고 충실한 작업에 대한 프롬프트 압축을위한 데이터 증류
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- GVGEN : 부피 표현을 가진 텍스트-3D 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19 -Gaussianflow : 4D 컨텐츠 생성을위한 가우시안 역학 스플릿
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Fresco : Zero-샷 비디오 번역에 대한 공간-일시적 서신
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- Fouriscale : 훈련이없는 고해상도 이미지 합성에 대한 주파수 관점
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- 모델 병합 레시피의 진화 적 최적화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), ([: Octocat :] (https : //github.com/ Sakanaai/Evolutionary-model-merge)! [Github Repo Stars] (https://img.shields.io/github/stars/ Sakanaai/Evolutionary-Model-Merge? Style = Social)))) - 03/19 -Comboverse : 공간적으로 인식 확산 안내를 사용한 구성 3D 자산 생성
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- 차트 기반 추론 : LLM에서 VLM으로 기능을 전송합니다.
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19 -Apple의 MM1 : 이미지와 텍스트 데이터를 해석 할 수있는 멀티 모달 대형 언어 모델
(소식), - 03/19- 애니메이터 조명 : 교차 모델 확산 증류
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/19- 에이전트 - 플랜 : 대형 언어 모델에 대한 효과적인 에이전트 튜닝 데이터 및 방법 설계
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- 계산 병리를위한 시각적 기초 모델
(), (✳️) - 03/19- 대형 언어 모델을 통한 특성 AI 에이전트
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), (! [github repo stars] ( https://img.shields.io/github/stars/nuaa-nlp/character100? style = social)))) - 03/18- 우리는 LLM의 의사 결정에 얼마나 멀리 떨어져 있습니까? 다중 에이전트 환경에서 LLMS의 게임 능력 평가
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 -Videoagent : 비디오 이해를위한 메모리 - 방해 된 다중 모드 에이전트
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18 -vfusion3d : 비디오 확산 모델에서 확장 가능한 3D 생성 모델 학습
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18 -TNT -LLM : 대형 언어 모델로 규모로 텍스트 마이닝
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18 -SV3D : 잠재 비디오 확산을 사용하여 단일 이미지에서 새로운 멀티 뷰 합성 및 3D 세대
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18- 라우터 벤치 : 멀티 엘 라우팅 시스템의 벤치 마크
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), (ss) - 03/18- LLM으로 제로 샷 시각적 인식을 자동화하기위한 메타 프롬프트
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 -LN3DIFF : 빠른 3D 세대를위한 확장 가능한 잠재 신경장 확산
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18- Llava-Uhd : 종횡비 및 고해상도 이미지를 인식하는 LMM
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 -LARIMAR : 에피소드 메모리 제어가있는 대형 언어 모델
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18- Infinite-ID : ID- 시성 디퍼 커플 링 패러다임을 통한 신원 보존 개인화
(), (), (?), (?), (?), (html), (sl), (sp), (gs), (ss), (✳️) - 03/18 -GPT -4 평가자 : 농업 해충 관리에 대한 대형 언어 모델 평가
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS ), (봄 여름 시즌)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (지저귀다,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS) , (봄 여름 시즌)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️) , ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️) , ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️) , ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️) , ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS) , (봄 여름 시즌)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


