meena chatbot
1.0.0
다음은 Google Research에서 개발하고 Towards a Human-like Open-Domain Chatbot이라는 논문에 설명된 최첨단 챗봇인 Meena를 재현하려는 시도입니다.
이 구현을 위해 저는 논문에 설명된 진화된 변환기 모델을 사용하여 tensor2tensor 딥 러닝 라이브러리를 사용했습니다.
사용된 훈련 세트는 이탈리아어로 된 OpenSubtitles 코퍼스입니다. 여기에서는 다른 많은 언어도 사용할 수 있습니다.
논문에서 수행된 작업과 유사하게 이 모델은 총 108M 매개변수에 대해 1개의 인코더 블록과 12개의 디코더 블록으로 구성됩니다. 사용된 최적화 프로그램은 논문에 설명된 것과 동일한 훈련 속도 일정을 가진 Adafactor입니다.
다음은 이탈리아어로 된 OpenSubtitles 데이터세트의 4천만 문장에 대해 모델을 훈련한 후의 결과입니다. 학습률은 0.01에서 시작하여 10,000단계 동안 일정하게 유지된 다음 단계 수의 역제곱근으로 감소합니다.
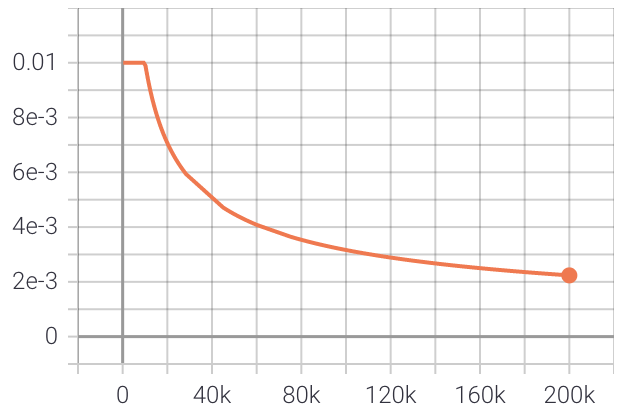
훈련 중 평가 손실의 플롯은 다음과 같습니다. 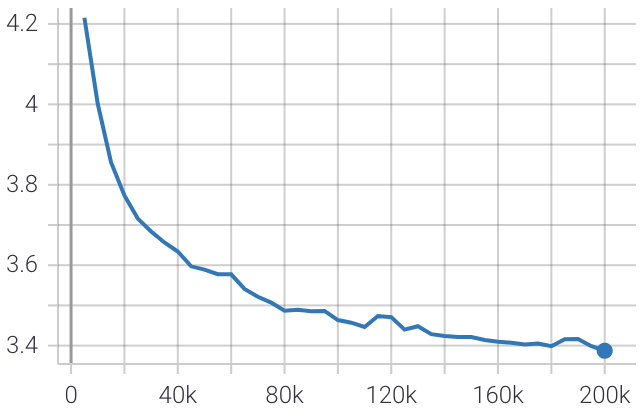
최종 Perplexity 점수는 10.4로 Google의 meena chatbot 10.2가 달성한 Perplexity 점수와 매우 가깝습니다.
이 논문은 챗봇의 "인간 유사성"과 상관관계가 있는 당혹성 점수와 민감성 및 특이성 평균 사이의 상관관계를 보여줍니다. 당혹감 점수는 우리 봇이 Cleverbot 및 DialoGPT와 같은 다른 챗봇보다 우수하다는 것을 보여줍니다. 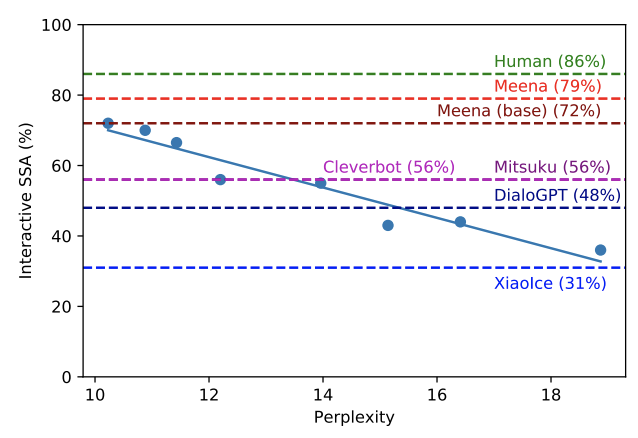
그러나 사용된 데이터 세트는 인간 간의 정상적인 대화를 잘 나타내지 않습니다. 그러나 Opensubtitles는 다양한 언어로 매우 큰 데이터 세트를 제공합니다.
노트북 meena_chatbot_inference.ipynb 를 실행하기만 하면 됩니다.
그렇지 않으면 다음 모델을 다운로드하여 추출하십시오. predict.py 에서 적절한 MODEL_DIR 및 CHECKPOINT_NAME을 설정하고 main.py 실행합니다.
학습을 위해 Google Colab에서 ipython 노트북을 실행하면 모델이 Google 드라이브에 저장됩니다. 실행이 끝나면 챗봇과 상호 작용할 수 있습니다.
폴더에 다음 파일을 복사하여 모델을 내보낼 수 있습니다.
적절한 모델 디렉터리를 설정한 후 main.py 실행합니다.
server.py 챗봇 제공을 위한 간단한 HTTP API를 제공합니다.


