LaTeX OCR
1.0.0
이 프로젝트의 목표는 수학 공식의 이미지를 가져와 해당 LaTeX 코드를 반환하는 학습 기반 시스템을 만드는 것입니다.
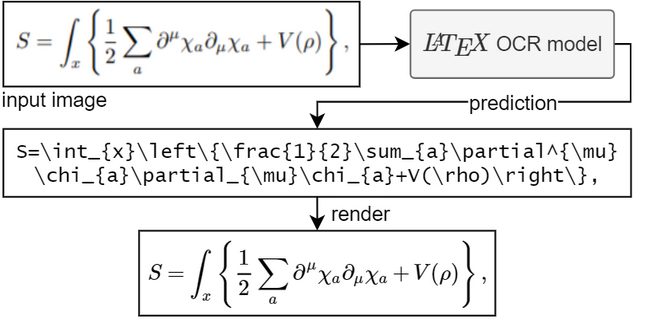
모델을 실행하려면 Python 3.7 이상이 필요합니다.
PyTorch가 설치되어 있지 않은 경우. 여기의 지침을 따르세요.
pix2tex 패키지를 설치하십시오:
pip install "pix2tex[gui]"
모델 체크포인트가 자동으로 다운로드됩니다.
이미지에서 예측을 얻는 방법에는 세 가지가 있습니다.
pix2tex 호출하여 명령줄 도구를 사용할 수 있습니다. 여기서 디스크의 기존 이미지와 클립보드의 이미지를 구문 분석할 수 있습니다.
@katie-lim 덕분에 모델 예측을 얻는 빠른 방법으로 멋진 사용자 인터페이스를 사용할 수 있습니다. latexocr 로 GUI를 호출하기만 하면 됩니다. 여기에서 스크린샷을 찍을 수 있으며 예측된 라텍스 코드가 MathJax를 사용하여 렌더링되고 클립보드에 복사됩니다.
Linux에서는 gnome-screenshot 미리 설치되어 있으면 gnome-screenshot (다중 모니터 지원과 함께 제공)과 함께 GUI를 사용할 수 있습니다. Wayland의 경우 grim 과 slurp 모두 사용할 수 있는 경우 사용됩니다. gnome-screenshot 은 wlroots 기반 Wayland 합성기와 호환되지 않습니다. 사용 가능한 경우 gnome-screenshot 선호되므로 이 경우 환경 변수 SCREENSHOT_TOOL grim 으로 설정해야 할 수도 있습니다(사용 가능한 다른 값은 gnome-screenshot 및 pil 입니다).
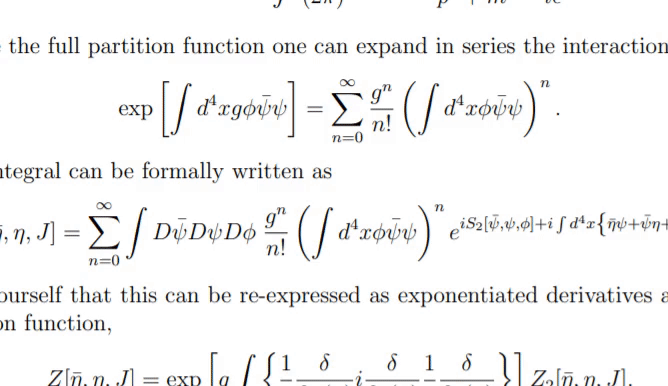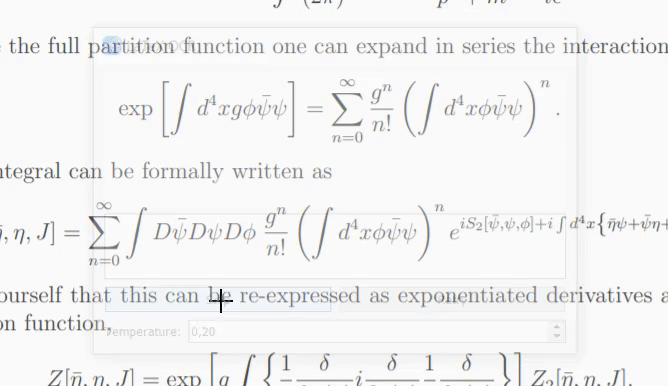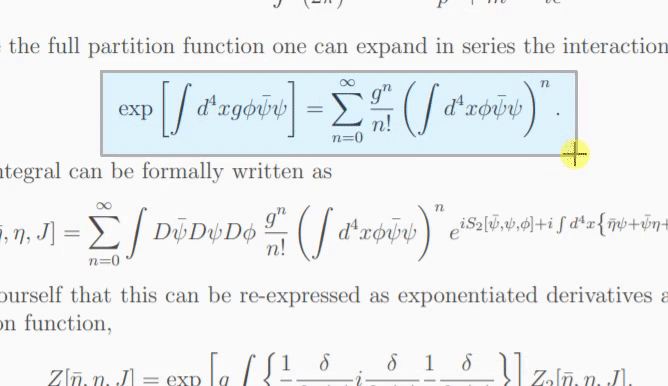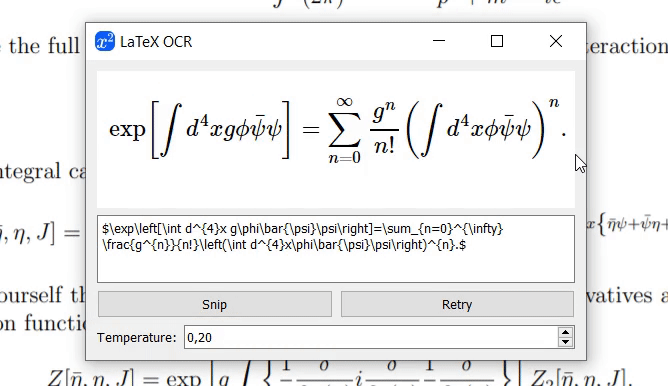
모델이 이미지의 내용을 확신할 수 없는 경우 "재시도"를 클릭할 때마다 다른 예측이 출력될 수 있습니다. temperature 매개변수를 사용하면 이 동작을 제어할 수 있습니다(낮은 온도에서도 동일한 결과가 생성됨).
API를 사용할 수 있습니다. 여기에는 추가 종속성이 있습니다. pip install -U "pix2tex[api]" 를 통해 설치하고 실행하세요.
파이썬 -m pix2tex.api.run
포트 8502에서 API에 연결하는 Streamlit 데모를 시작합니다. API에 사용할 수 있는 도커 이미지도 있습니다: https://hub.docker.com/r/lukasblecher/pix2tex
docker pull lukasblecher/pix2tex:api docker run --rm -p 8502:8502 lukasblecher/pix2tex:api
스트림라이트 데모 실행도 실행하려면
docker run --rm -it -p 8501:8501 --entrypoint python lukasblecher/pix2tex:api pix2tex/api/run.py
http://localhost:8501/로 이동합니다.
Python 내에서 사용
PIL import Imagefrom pix2tex.cli import LatexOCRimg = Image.open('path/to/image.png')model = LatexOCR()print(model(img))이 모델은 해상도가 낮은 이미지에서 가장 잘 작동합니다. 그래서 다른 신경망이 입력 이미지의 최적 해상도를 예측하는 전처리 단계를 추가했습니다. 이 모델은 훈련 데이터와 가장 유사하도록 사용자 정의 이미지의 크기를 자동으로 조정하여 실제에서 발견된 이미지의 성능을 향상시킵니다. 그래도 완벽하지 않고 거대한 이미지를 최적으로 처리하지 못할 수도 있으므로 사진을 찍기 전에 완전히 확대하지 마세요.
항상 결과를 주의 깊게 다시 확인하세요. 답이 틀렸다면 다른 해결 방법으로 예측을 다시 시도할 수 있습니다.
패키지를 사용하고 싶으신가요?
지금은 문서를 작성하려고 합니다.
여기를 방문하세요: https://pix2tex.readthedocs.io/
몇 가지 종속성을 설치합니다 pip install "pix2tex[train]" .
먼저 이미지를 실제 라벨과 결합해야 합니다. 렌더링된 LaTeX 코드를 사용하여 이미지에 대한 상대 경로를 저장하는 데이터 세트 클래스(추가 개선이 필요함)를 작성했습니다. 데이터세트 피클 파일을 생성하려면 다음을 실행하세요.
python -m pix2tex.dataset.dataset --equations path_to_textfile --images path_to_images --out dataset.pkl
자신만의 토크나이저를 사용하려면 --tokenizer 통해 전달하세요(아래 참조).
생성된 교육 데이터는 Google 드라이브에서도 찾을 수 있습니다(formulae.zip - 이미지, math.txt - 라벨). 검증 및 테스트 데이터에 대해 단계를 반복합니다. 모두 동일한 레이블 텍스트 파일을 사용합니다.
구성 파일의 data (및 valdata ) 항목을 새로 생성된 .pkl 파일로 편집합니다. 원한다면 다른 하이퍼파라미터를 변경하세요. 템플릿은 pix2tex/model/settings/config.yaml 참조하세요.
이제 실제 훈련 실행을 위해
python -m pix2tex.train --config path_to_config_file
자신의 데이터를 사용하고 싶다면 다음을 사용하여 자신만의 토크나이저를 만드는 데 관심이 있을 수 있습니다.
python -m pix2tex.dataset.dataset --equations path_to_textfile --vocab-size 8000 --out tokenizer.json
구성 파일에서 토크나이저 경로를 업데이트하고 num_tokens 어휘 크기로 설정하는 것을 잊지 마세요.
이 모델은 ResNet 백본을 갖춘 ViT [1] 인코더와 Transformer [2] 디코더로 구성됩니다.
| BLEU 점수 | 정규 편집 거리 | 토큰 정확도 |
|---|---|---|
| 0.88 | 0.10 | 0.60 |
네트워크가 학습하려면 쌍을 이루는 데이터가 필요합니다. 운 좋게도 인터넷에는 Wikipedia, arXiv와 같은 LaTeX 코드가 많이 있습니다. 또한 im2latex-100k [3] 데이터 세트의 공식을 사용합니다. 모든 내용은 여기에서 확인할 수 있습니다.
수학을 다양한 글꼴로 렌더링하기 위해 XeLaTeX를 사용하고 PDF를 생성한 후 마지막으로 PNG로 변환합니다. 마지막 단계에서는 일부 타사 도구를 사용해야 합니다.
XeLaTeX
Ghostscript를 사용한 ImageMagick. (pdf를 png로 변환하는 경우)
KaTeX를 실행하기 위한 Node.js(Latex 코드 정규화용)
Python 3.7+ 및 종속성( setup.py 에 지정됨)
라틴 현대 수학, GFSNeohellenicMath.otf, Asana 수학, XITS 수학, Cambria 수학
더 많은 평가 측정항목 추가
GUI를 생성
빔 검색 추가
손으로 쓴 수식 지원(다 완료되었습니다. 학습 Colab 노트북 참조)
모델 크기 감소(증류)
최적의 하이퍼파라미터 찾기
모델 구조 조정
데이터 스크랩 수정 및 더 많은 데이터 스크랩
모델 추적(#2)
어떤 종류의 기여도 환영합니다.
lucidrains, rwightman, im2markup, arxiv_leaks, pkra: Mathjax, harupy: 캡처 도구에서 가져와 수정한 코드
[1] 이미지는 16x16 단어만큼의 가치가 있습니다
[2] 주의가 필요한 전부입니다
[3] Coarse-to-Fine Attention을 통한 이미지-마크업 생성


